Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePay Attention when Required
Paper and Code
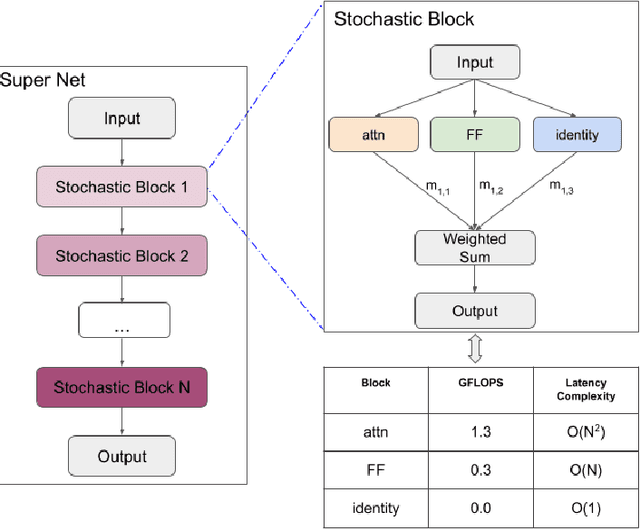
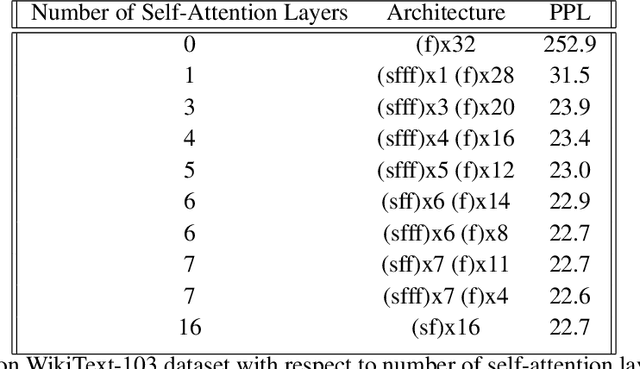


Transformer-based models consist of interleaved feed-forward blocks - that capture content meaning, and relatively more expensive self-attention blocks - that capture context meaning. In this paper, we explored trade-offs and ordering of the blocks to improve upon the current Transformer architecture and proposed PAR Transformer. It needs 35% lower compute time than Transformer-XL achieved by replacing ~63% of the self-attention blocks with feed-forward blocks, and retains the perplexity on WikiText-103 language modelling benchmark. We further validated our results on text8 and enwiki8 datasets, as well as on the BERT model.
* 9 pages, 4 figures, 7 tables
View paper on