 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePay Attention when Required
Sep 09, 2020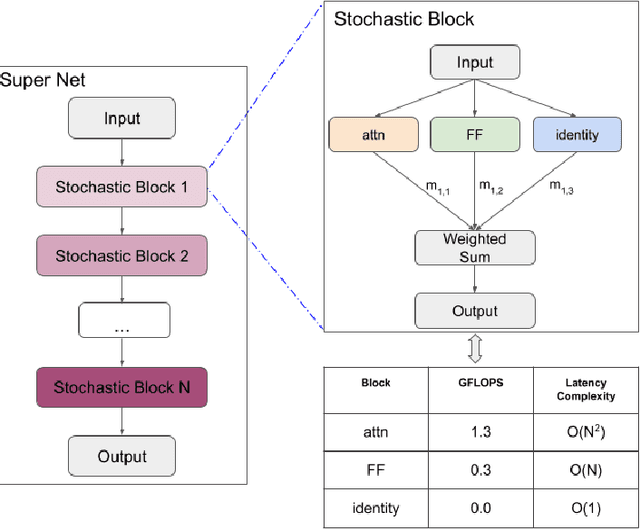
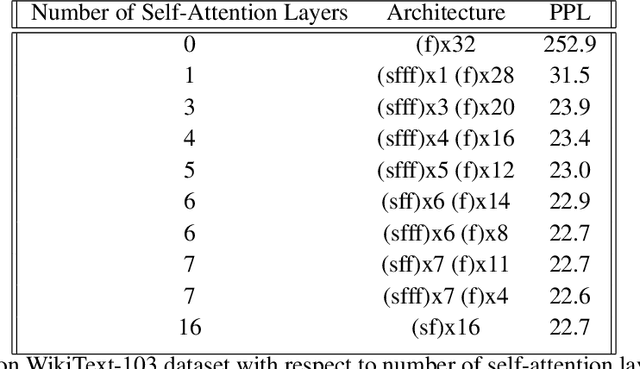


Transformer-based models consist of interleaved feed-forward blocks - that capture content meaning, and relatively more expensive self-attention blocks - that capture context meaning. In this paper, we explored trade-offs and ordering of the blocks to improve upon the current Transformer architecture and proposed PAR Transformer. It needs 35% lower compute time than Transformer-XL achieved by replacing ~63% of the self-attention blocks with feed-forward blocks, and retains the perplexity on WikiText-103 language modelling benchmark. We further validated our results on text8 and enwiki8 datasets, as well as on the BERT model.
GANDALF: Generative Adversarial Networks with Discriminator-Adaptive Loss Fine-tuning for Alzheimer's Disease Diagnosis from MRI
Aug 10, 2020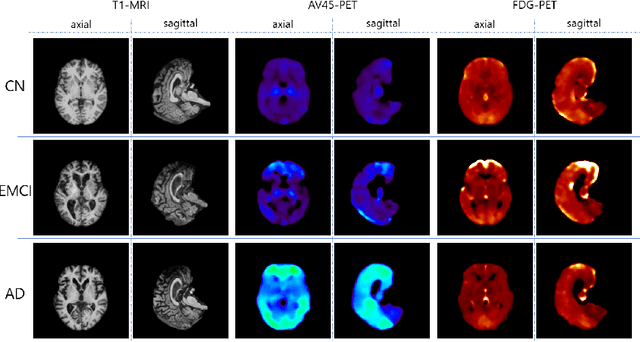
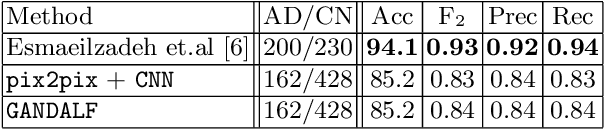
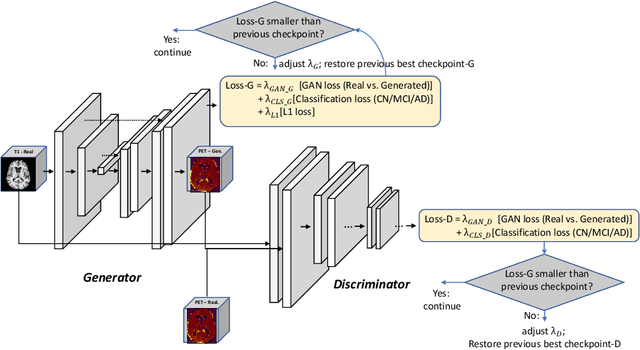
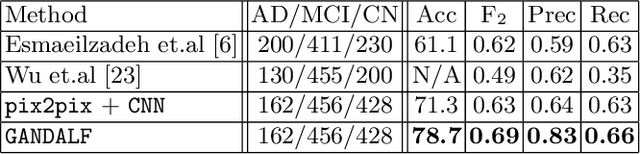
Positron Emission Tomography (PET) is now regarded as the gold standard for the diagnosis of Alzheimer's Disease (AD). However, PET imaging can be prohibitive in terms of cost and planning, and is also among the imaging techniques with the highest dosage of radiation. Magnetic Resonance Imaging (MRI), in contrast, is more widely available and provides more flexibility when setting the desired image resolution. Unfortunately, the diagnosis of AD using MRI is difficult due to the very subtle physiological differences between healthy and AD subjects visible on MRI. As a result, many attempts have been made to synthesize PET images from MR images using generative adversarial networks (GANs) in the interest of enabling the diagnosis of AD from MR. Existing work on PET synthesis from MRI has largely focused on Conditional GANs, where MR images are used to generate PET images and subsequently used for AD diagnosis. There is no end-to-end training goal. This paper proposes an alternative approach to the aforementioned, where AD diagnosis is incorporated in the GAN training objective to achieve the best AD classification performance. Different GAN lossesare fine-tuned based on the discriminator performance, and the overall training is stabilized. The proposed network architecture and training regime show state-of-the-art performance for three- and four- class AD classification tasks.
GANBERT: Generative Adversarial Networks with Bidirectional Encoder Representations from Transformers for MRI to PET synthesis
Aug 10, 2020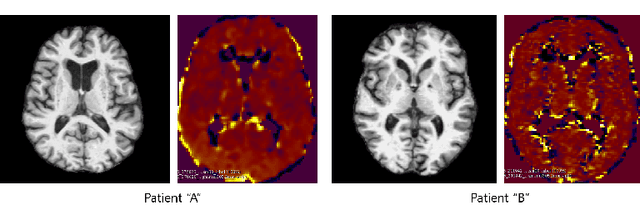
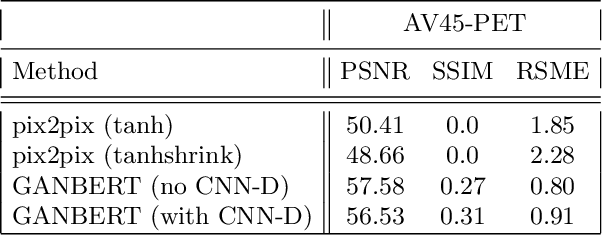


Synthesizing medical images, such as PET, is a challenging task due to the fact that the intensity range is much wider and denser than those in photographs and digital renderings and are often heavily biased toward zero. Above all, intensity values in PET have absolute significance, and are used to compute parameters that are reproducible across the population. Yet, usually much manual adjustment has to be made in pre-/post- processing when synthesizing PET images, because its intensity ranges can vary a lot, e.g., between -100 to 1000 in floating point values. To overcome these challenges, we adopt the Bidirectional Encoder Representations from Transformers (BERT) algorithm that has had great success in natural language processing (NLP), where wide-range floating point intensity values are represented as integers ranging between 0 to 10000 that resemble a dictionary of natural language vocabularies. BERT is then trained to predict a proportion of masked values images, where its "next sentence prediction (NSP)" acts as GAN discriminator. Our proposed approach, is able to generate PET images from MRI images in wide intensity range, with no manual adjustments in pre-/post- processing. It is a method that can scale and ready to deploy.