 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNonuniform-Tensor-Parallelism: Mitigating GPU failure impact for Scaled-up LLM Training
Apr 08, 2025



LLM training is scaled up to 10Ks of GPUs by a mix of data-(DP) and model-parallel (MP) execution. Critical to achieving efficiency is tensor-parallel (TP; a form of MP) execution within tightly-coupled subsets of GPUs, referred to as a scale-up domain, and the larger the scale-up domain the better the performance. New datacenter architectures are emerging with more GPUs able to be tightly-coupled in a scale-up domain, such as moving from 8 GPUs to 72 GPUs connected via NVLink. Unfortunately, larger scale-up domains increase the blast-radius of failures, with a failure of single GPU potentially impacting TP execution on the full scale-up domain, which can degrade overall LLM training throughput dramatically. With as few as 0.1% of GPUs being in a failed state, a high TP-degree job can experience nearly 10% reduction in LLM training throughput. We propose nonuniform-tensor-parallelism (NTP) to mitigate this amplified impact of GPU failures. In NTP, a DP replica that experiences GPU failures operates at a reduced TP degree, contributing throughput equal to the percentage of still-functional GPUs. We also propose a rack-design with improved electrical and thermal capabilities in order to sustain power-boosting of scale-up domains that have experienced failures; combined with NTP, this can allow the DP replica with the reduced TP degree (i.e., with failed GPUs) to keep up with the others, thereby achieving near-zero throughput loss for large-scale LLM training.
QUIDAM: A Framework for Quantization-Aware DNN Accelerator and Model Co-Exploration
Jun 30, 2022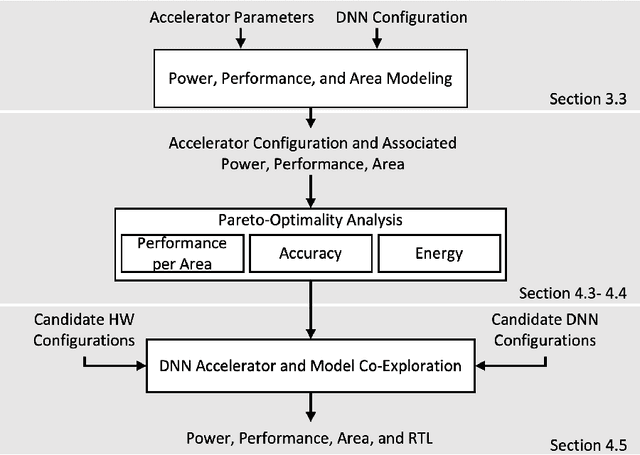
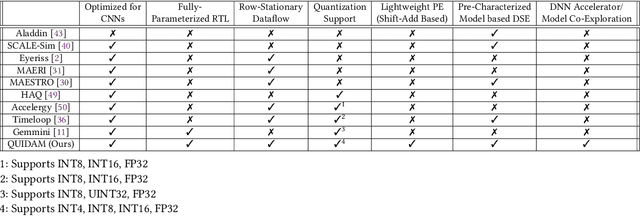
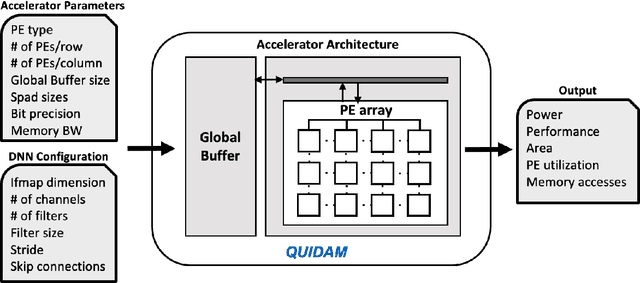
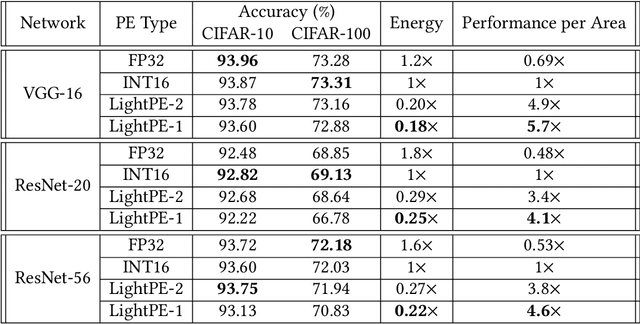
As the machine learning and systems communities strive to achieve higher energy-efficiency through custom deep neural network (DNN) accelerators, varied precision or quantization levels, and model compression techniques, there is a need for design space exploration frameworks that incorporate quantization-aware processing elements into the accelerator design space while having accurate and fast power, performance, and area models. In this work, we present QUIDAM, a highly parameterized quantization-aware DNN accelerator and model co-exploration framework. Our framework can facilitate future research on design space exploration of DNN accelerators for various design choices such as bit precision, processing element type, scratchpad sizes of processing elements, global buffer size, number of total processing elements, and DNN configurations. Our results show that different bit precisions and processing element types lead to significant differences in terms of performance per area and energy. Specifically, our framework identifies a wide range of design points where performance per area and energy varies more than 5x and 35x, respectively. With the proposed framework, we show that lightweight processing elements achieve on par accuracy results and up to 5.7x more performance per area and energy improvement when compared to the best INT16 based implementation. Finally, due to the efficiency of the pre-characterized power, performance, and area models, QUIDAM can speed up the design exploration process by 3-4 orders of magnitude as it removes the need for expensive synthesis and characterization of each design.
Efficient Deep Learning Using Non-Volatile Memory Technology
Jun 27, 2022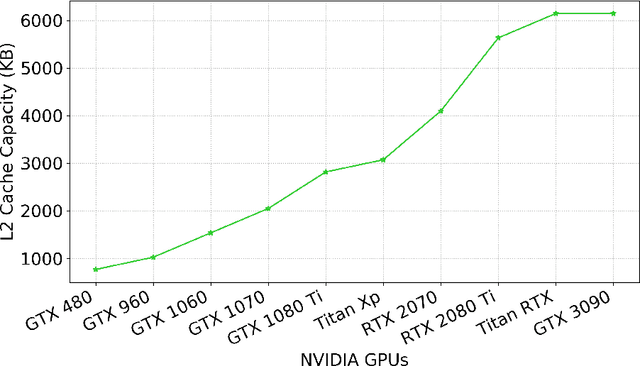

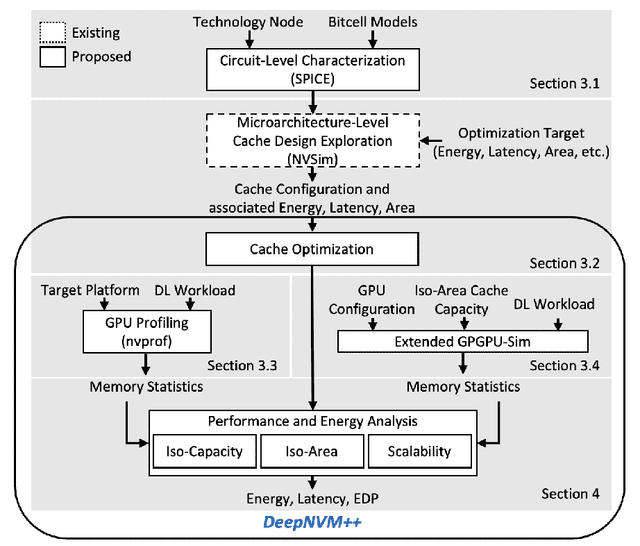

Embedded machine learning (ML) systems have now become the dominant platform for deploying ML serving tasks and are projected to become of equal importance for training ML models. With this comes the challenge of overall efficient deployment, in particular low power and high throughput implementations, under stringent memory constraints. In this context, non-volatile memory (NVM) technologies such as STT-MRAM and SOT-MRAM have significant advantages compared to conventional SRAM due to their non-volatility, higher cell density, and scalability features. While prior work has investigated several architectural implications of NVM for generic applications, in this work we present DeepNVM++, a comprehensive framework to characterize, model, and analyze NVM-based caches in GPU architectures for deep learning (DL) applications by combining technology-specific circuit-level models and the actual memory behavior of various DL workloads. DeepNVM++ relies on iso-capacity and iso-area performance and energy models for last-level caches implemented using conventional SRAM and emerging STT-MRAM and SOT-MRAM technologies. In the iso-capacity case, STT-MRAM and SOT-MRAM provide up to 3.8x and 4.7x energy-delay product (EDP) reduction and 2.4x and 2.8x area reduction compared to conventional SRAM, respectively. Under iso-area assumptions, STT-MRAM and SOT-MRAM provide up to 2.2x and 2.4x EDP reduction and accommodate 2.3x and 3.3x cache capacity when compared to SRAM, respectively. We also perform a scalability analysis and show that STT-MRAM and SOT-MRAM achieve orders of magnitude EDP reduction when compared to SRAM for large cache capacities. DeepNVM++ is demonstrated on STT-/SOT-MRAM technologies and can be used for the characterization, modeling, and analysis of any NVM technology for last-level caches in GPUs for DL applications.
QADAM: Quantization-Aware DNN Accelerator Modeling for Pareto-Optimality
May 20, 2022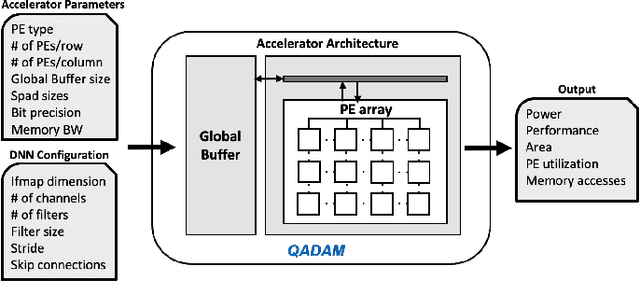
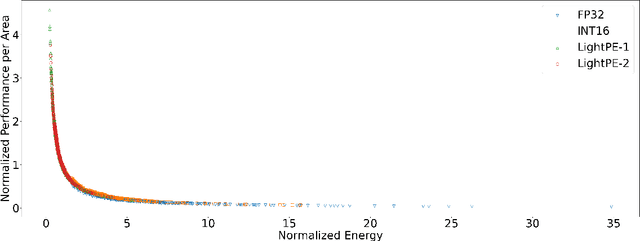
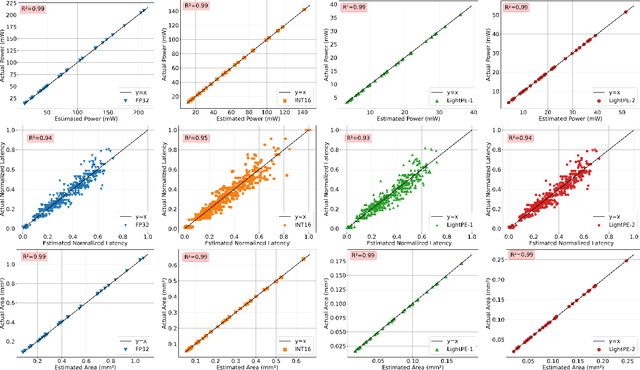
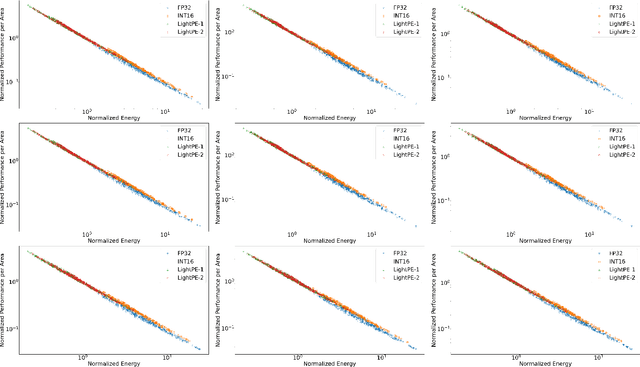
As the machine learning and systems communities strive to achieve higher energy-efficiency through custom deep neural network (DNN) accelerators, varied bit precision or quantization levels, there is a need for design space exploration frameworks that incorporate quantization-aware processing elements (PE) into the accelerator design space while having accurate and fast power, performance, and area models. In this work, we present QADAM, a highly parameterized quantization-aware power, performance, and area modeling framework for DNN accelerators. Our framework can facilitate future research on design space exploration and Pareto-efficiency of DNN accelerators for various design choices such as bit precision, PE type, scratchpad sizes of PEs, global buffer size, number of total PEs, and DNN configurations. Our results show that different bit precisions and PE types lead to significant differences in terms of performance per area and energy. Specifically, our framework identifies a wide range of design points where performance per area and energy varies more than 5x and 35x, respectively. We also show that the proposed lightweight processing elements (LightPEs) consistently achieve Pareto-optimal results in terms of accuracy and hardware-efficiency. With the proposed framework, we show that LightPEs achieve on par accuracy results and up to 5.7x more performance per area and energy improvement when compared to the best INT16 based design.
QAPPA: Quantization-Aware Power, Performance, and Area Modeling of DNN Accelerators
May 17, 2022
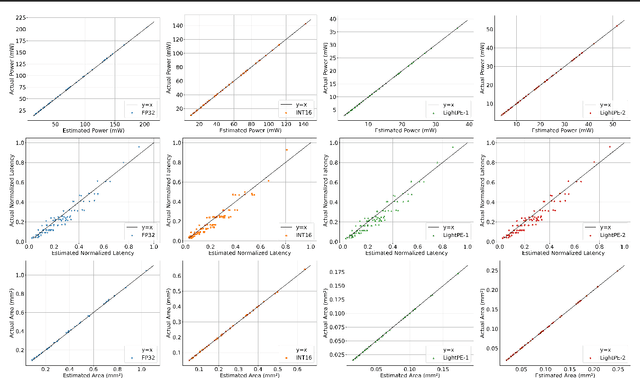
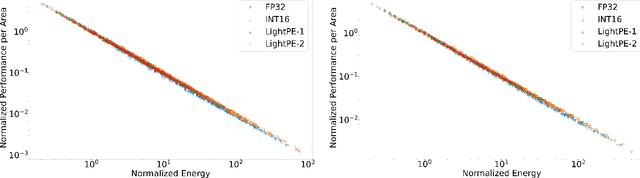

As the machine learning and systems community strives to achieve higher energy-efficiency through custom DNN accelerators and model compression techniques, there is a need for a design space exploration framework that incorporates quantization-aware processing elements into the accelerator design space while having accurate and fast power, performance, and area models. In this work, we present QAPPA, a highly parameterized quantization-aware power, performance, and area modeling framework for DNN accelerators. Our framework can facilitate the future research on design space exploration of DNN accelerators for various design choices such as bit precision, processing element type, scratchpad sizes of processing elements, global buffer size, device bandwidth, number of total processing elements in the the design, and DNN workloads. Our results show that different bit precisions and processing element types lead to significant differences in terms of performance per area and energy. Specifically, our proposed lightweight processing elements achieve up to 4.9x more performance per area and energy improvement when compared to INT16 based implementation.
DeepNVM++: Cross-Layer Modeling and Optimization Framework of Non-Volatile Memories for Deep Learning
Dec 08, 2020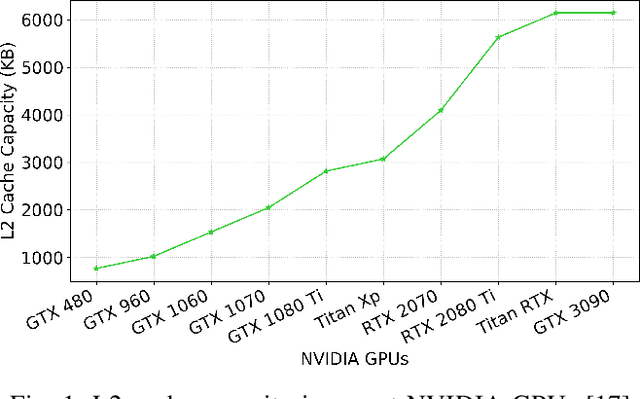
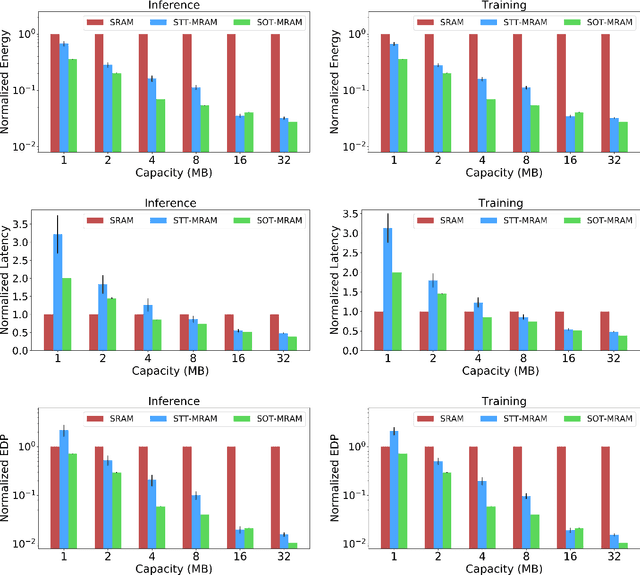
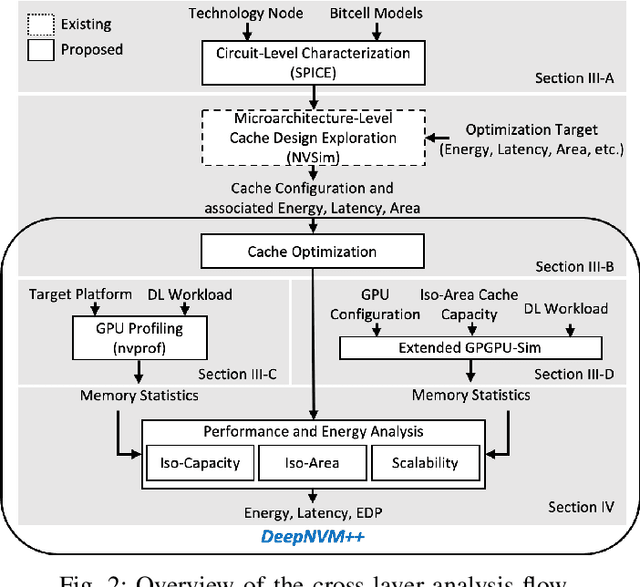
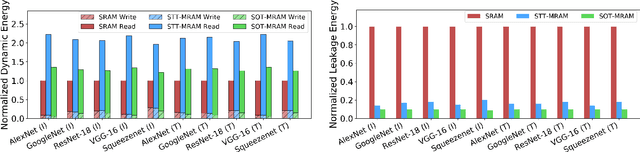
Non-volatile memory (NVM) technologies such as spin-transfer torque magnetic random access memory (STT-MRAM) and spin-orbit torque magnetic random access memory (SOT-MRAM) have significant advantages compared to conventional SRAM due to their non-volatility, higher cell density, and scalability features. While previous work has investigated several architectural implications of NVM for generic applications, in this work we present DeepNVM++, a framework to characterize, model, and analyze NVM-based caches in GPU architectures for deep learning (DL) applications by combining technology-specific circuit-level models and the actual memory behavior of various DL workloads. We present both iso-capacity and iso-area performance and energy analysis for systems whose last-level caches rely on conventional SRAM and emerging STT-MRAM and SOT-MRAM technologies. In the iso-capacity case, STT-MRAM and SOT-MRAM provide up to 3.8x and 4.7x energy-delay product (EDP) reduction and 2.4x and 2.8x area reduction compared to conventional SRAM, respectively. Under iso-area assumptions, STT-MRAM and SOT-MRAM provide up to 2x and 2.3x EDP reduction and accommodate 2.3x and 3.3x cache capacity when compared to SRAM, respectively. We also perform a scalability analysis and show that STT-MRAM and SOT-MRAM achieve orders of magnitude EDP reduction when compared to SRAM for large cache capacities. Our comprehensive cross-layer framework is demonstrated on STT-/SOT-MRAM technologies and can be used for the characterization, modeling, and analysis of any NVM technology for last-level caches in GPUs for DL applications.
The Architectural Implications of Distributed Reinforcement Learning on CPU-GPU Systems
Dec 08, 2020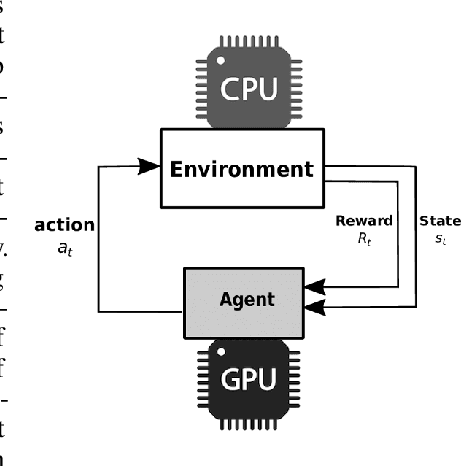
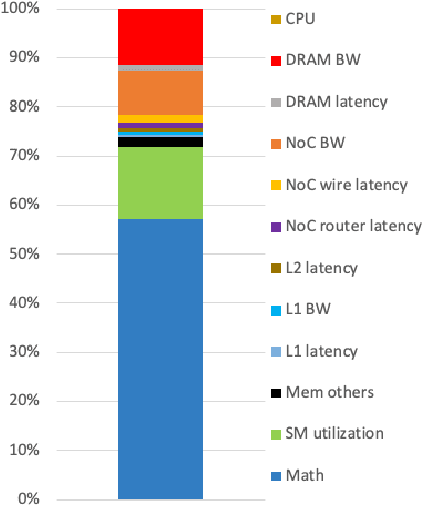
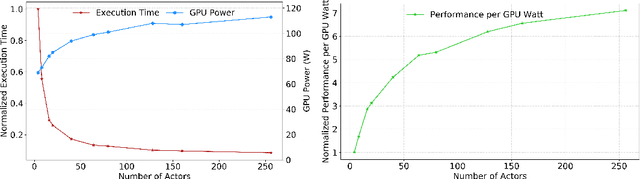
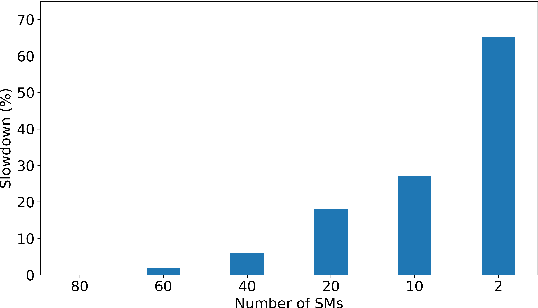
With deep reinforcement learning (RL) methods achieving results that exceed human capabilities in games, robotics, and simulated environments, continued scaling of RL training is crucial to its deployment in solving complex real-world problems. However, improving the performance scalability and power efficiency of RL training through understanding the architectural implications of CPU-GPU systems remains an open problem. In this work we investigate and improve the performance and power efficiency of distributed RL training on CPU-GPU systems by approaching the problem not solely from the GPU microarchitecture perspective but following a holistic system-level analysis approach. We quantify the overall hardware utilization on a state-of-the-art distributed RL training framework and empirically identify the bottlenecks caused by GPU microarchitectural, algorithmic, and system-level design choices. We show that the GPU microarchitecture itself is well-balanced for state-of-the-art RL frameworks, but further investigation reveals that the number of actors running the environment interactions and the amount of hardware resources available to them are the primary performance and power efficiency limiters. To this end, we introduce a new system design metric, CPU/GPU ratio, and show how to find the optimal balance between CPU and GPU resources when designing scalable and efficient CPU-GPU systems for RL training.