 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQUIDAM: A Framework for Quantization-Aware DNN Accelerator and Model Co-Exploration
Jun 30, 2022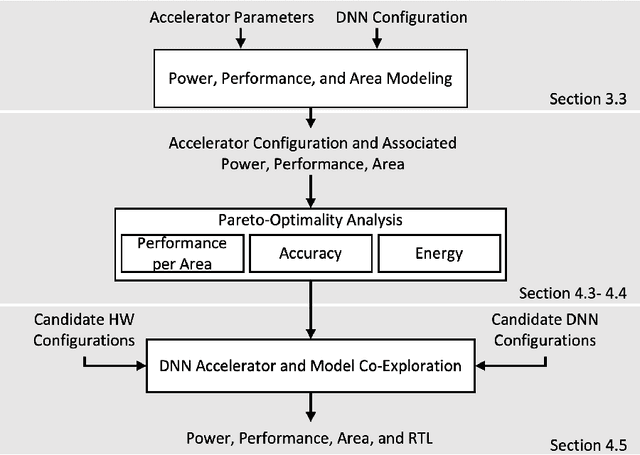
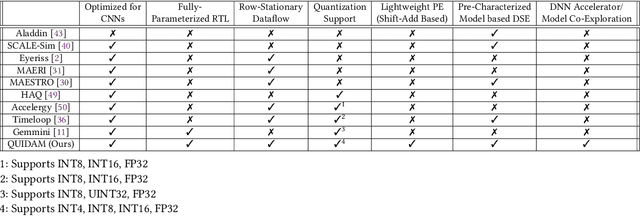
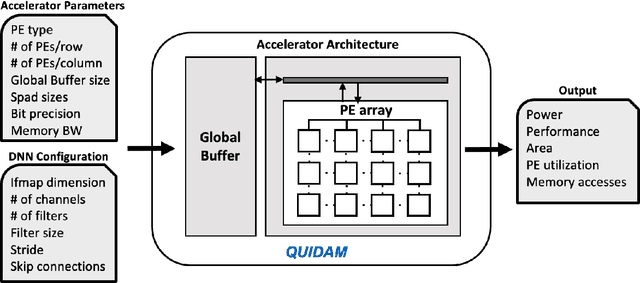
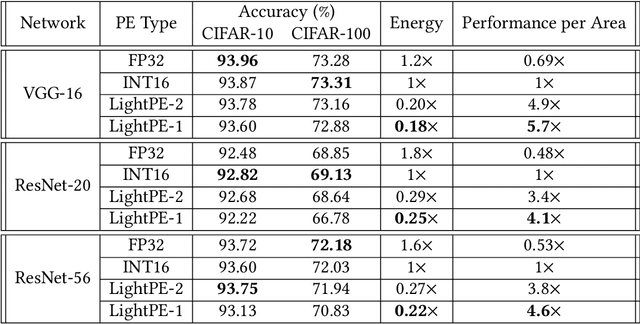
As the machine learning and systems communities strive to achieve higher energy-efficiency through custom deep neural network (DNN) accelerators, varied precision or quantization levels, and model compression techniques, there is a need for design space exploration frameworks that incorporate quantization-aware processing elements into the accelerator design space while having accurate and fast power, performance, and area models. In this work, we present QUIDAM, a highly parameterized quantization-aware DNN accelerator and model co-exploration framework. Our framework can facilitate future research on design space exploration of DNN accelerators for various design choices such as bit precision, processing element type, scratchpad sizes of processing elements, global buffer size, number of total processing elements, and DNN configurations. Our results show that different bit precisions and processing element types lead to significant differences in terms of performance per area and energy. Specifically, our framework identifies a wide range of design points where performance per area and energy varies more than 5x and 35x, respectively. With the proposed framework, we show that lightweight processing elements achieve on par accuracy results and up to 5.7x more performance per area and energy improvement when compared to the best INT16 based implementation. Finally, due to the efficiency of the pre-characterized power, performance, and area models, QUIDAM can speed up the design exploration process by 3-4 orders of magnitude as it removes the need for expensive synthesis and characterization of each design.
QADAM: Quantization-Aware DNN Accelerator Modeling for Pareto-Optimality
May 20, 2022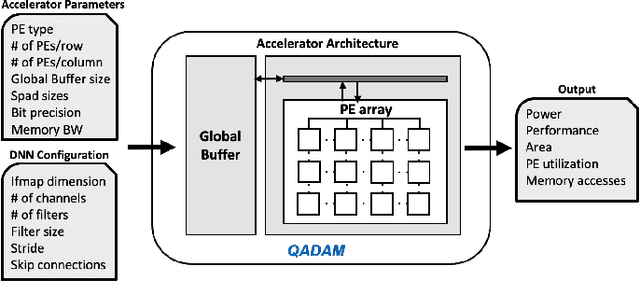
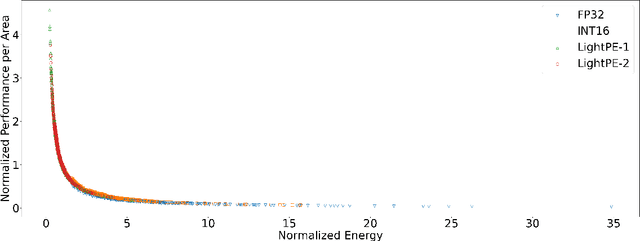
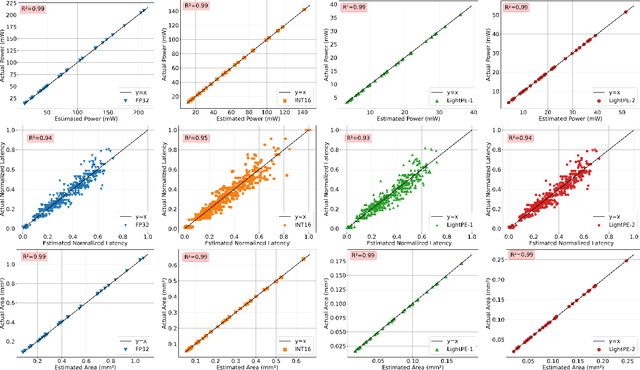
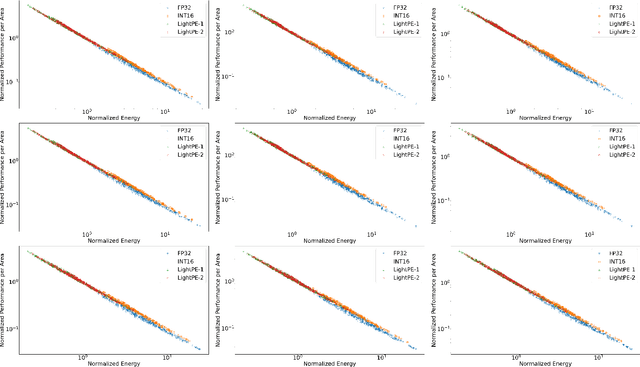
As the machine learning and systems communities strive to achieve higher energy-efficiency through custom deep neural network (DNN) accelerators, varied bit precision or quantization levels, there is a need for design space exploration frameworks that incorporate quantization-aware processing elements (PE) into the accelerator design space while having accurate and fast power, performance, and area models. In this work, we present QADAM, a highly parameterized quantization-aware power, performance, and area modeling framework for DNN accelerators. Our framework can facilitate future research on design space exploration and Pareto-efficiency of DNN accelerators for various design choices such as bit precision, PE type, scratchpad sizes of PEs, global buffer size, number of total PEs, and DNN configurations. Our results show that different bit precisions and PE types lead to significant differences in terms of performance per area and energy. Specifically, our framework identifies a wide range of design points where performance per area and energy varies more than 5x and 35x, respectively. We also show that the proposed lightweight processing elements (LightPEs) consistently achieve Pareto-optimal results in terms of accuracy and hardware-efficiency. With the proposed framework, we show that LightPEs achieve on par accuracy results and up to 5.7x more performance per area and energy improvement when compared to the best INT16 based design.
QAPPA: Quantization-Aware Power, Performance, and Area Modeling of DNN Accelerators
May 17, 2022
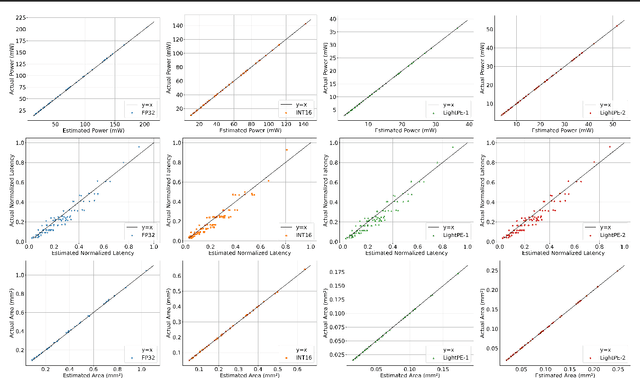
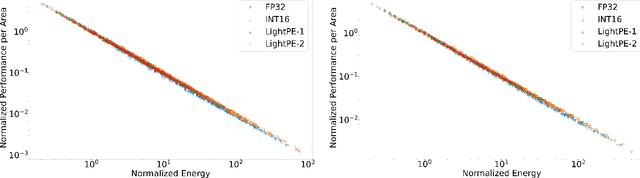

As the machine learning and systems community strives to achieve higher energy-efficiency through custom DNN accelerators and model compression techniques, there is a need for a design space exploration framework that incorporates quantization-aware processing elements into the accelerator design space while having accurate and fast power, performance, and area models. In this work, we present QAPPA, a highly parameterized quantization-aware power, performance, and area modeling framework for DNN accelerators. Our framework can facilitate the future research on design space exploration of DNN accelerators for various design choices such as bit precision, processing element type, scratchpad sizes of processing elements, global buffer size, device bandwidth, number of total processing elements in the the design, and DNN workloads. Our results show that different bit precisions and processing element types lead to significant differences in terms of performance per area and energy. Specifically, our proposed lightweight processing elements achieve up to 4.9x more performance per area and energy improvement when compared to INT16 based implementation.