 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQUIDAM: A Framework for Quantization-Aware DNN Accelerator and Model Co-Exploration
Jun 30, 2022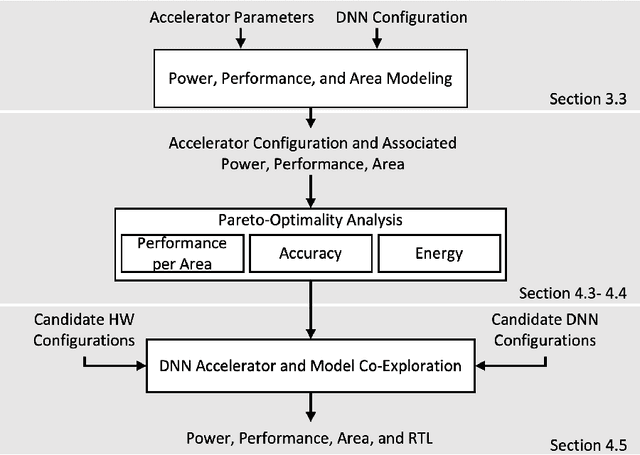
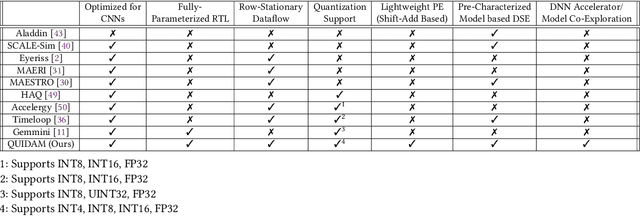
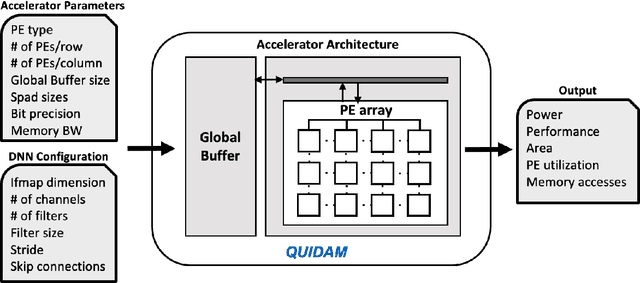
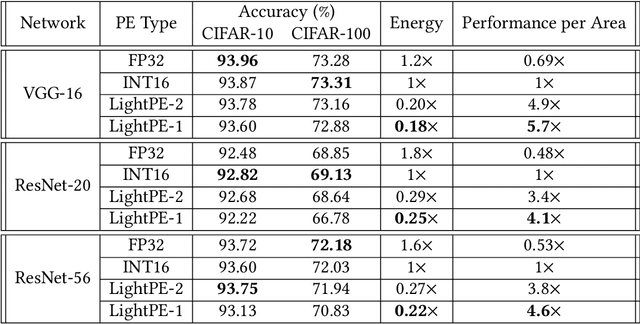
As the machine learning and systems communities strive to achieve higher energy-efficiency through custom deep neural network (DNN) accelerators, varied precision or quantization levels, and model compression techniques, there is a need for design space exploration frameworks that incorporate quantization-aware processing elements into the accelerator design space while having accurate and fast power, performance, and area models. In this work, we present QUIDAM, a highly parameterized quantization-aware DNN accelerator and model co-exploration framework. Our framework can facilitate future research on design space exploration of DNN accelerators for various design choices such as bit precision, processing element type, scratchpad sizes of processing elements, global buffer size, number of total processing elements, and DNN configurations. Our results show that different bit precisions and processing element types lead to significant differences in terms of performance per area and energy. Specifically, our framework identifies a wide range of design points where performance per area and energy varies more than 5x and 35x, respectively. With the proposed framework, we show that lightweight processing elements achieve on par accuracy results and up to 5.7x more performance per area and energy improvement when compared to the best INT16 based implementation. Finally, due to the efficiency of the pre-characterized power, performance, and area models, QUIDAM can speed up the design exploration process by 3-4 orders of magnitude as it removes the need for expensive synthesis and characterization of each design.
QADAM: Quantization-Aware DNN Accelerator Modeling for Pareto-Optimality
May 20, 2022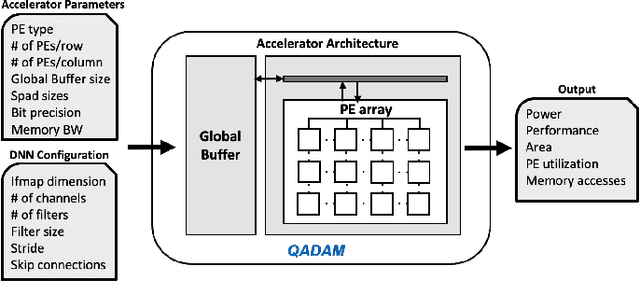
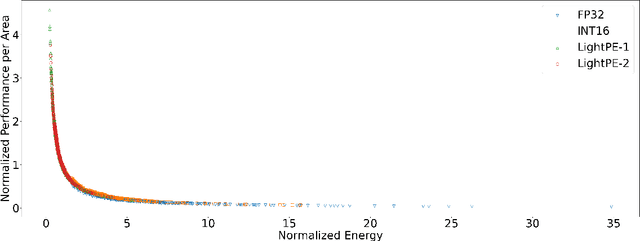
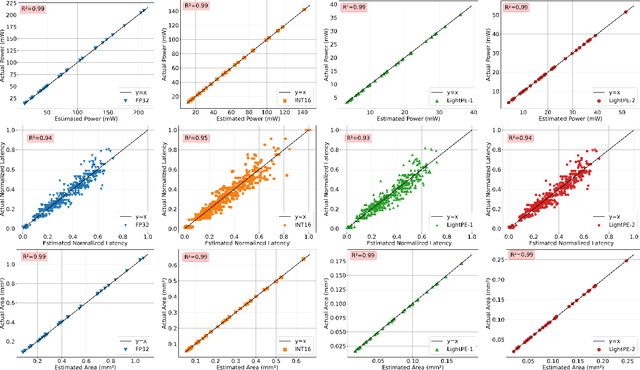
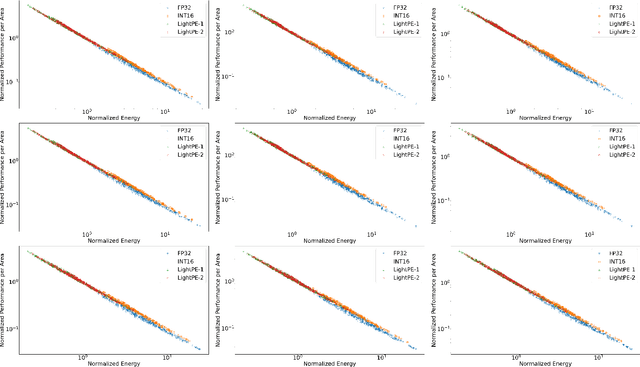
As the machine learning and systems communities strive to achieve higher energy-efficiency through custom deep neural network (DNN) accelerators, varied bit precision or quantization levels, there is a need for design space exploration frameworks that incorporate quantization-aware processing elements (PE) into the accelerator design space while having accurate and fast power, performance, and area models. In this work, we present QADAM, a highly parameterized quantization-aware power, performance, and area modeling framework for DNN accelerators. Our framework can facilitate future research on design space exploration and Pareto-efficiency of DNN accelerators for various design choices such as bit precision, PE type, scratchpad sizes of PEs, global buffer size, number of total PEs, and DNN configurations. Our results show that different bit precisions and PE types lead to significant differences in terms of performance per area and energy. Specifically, our framework identifies a wide range of design points where performance per area and energy varies more than 5x and 35x, respectively. We also show that the proposed lightweight processing elements (LightPEs) consistently achieve Pareto-optimal results in terms of accuracy and hardware-efficiency. With the proposed framework, we show that LightPEs achieve on par accuracy results and up to 5.7x more performance per area and energy improvement when compared to the best INT16 based design.
QAPPA: Quantization-Aware Power, Performance, and Area Modeling of DNN Accelerators
May 17, 2022
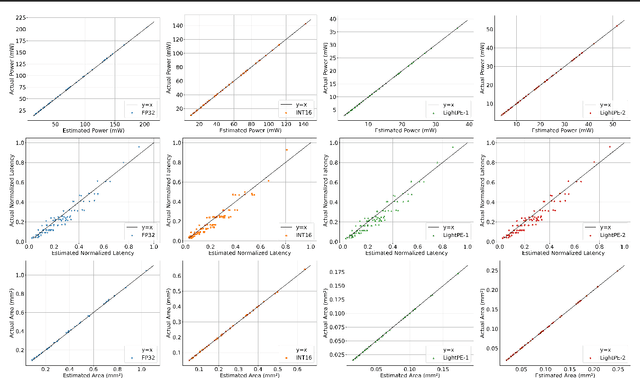
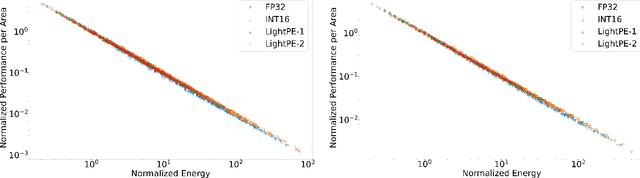

As the machine learning and systems community strives to achieve higher energy-efficiency through custom DNN accelerators and model compression techniques, there is a need for a design space exploration framework that incorporates quantization-aware processing elements into the accelerator design space while having accurate and fast power, performance, and area models. In this work, we present QAPPA, a highly parameterized quantization-aware power, performance, and area modeling framework for DNN accelerators. Our framework can facilitate the future research on design space exploration of DNN accelerators for various design choices such as bit precision, processing element type, scratchpad sizes of processing elements, global buffer size, device bandwidth, number of total processing elements in the the design, and DNN workloads. Our results show that different bit precisions and processing element types lead to significant differences in terms of performance per area and energy. Specifically, our proposed lightweight processing elements achieve up to 4.9x more performance per area and energy improvement when compared to INT16 based implementation.
Single-Path Mobile AutoML: Efficient ConvNet Design and NAS Hyperparameter Optimization
Jul 01, 2019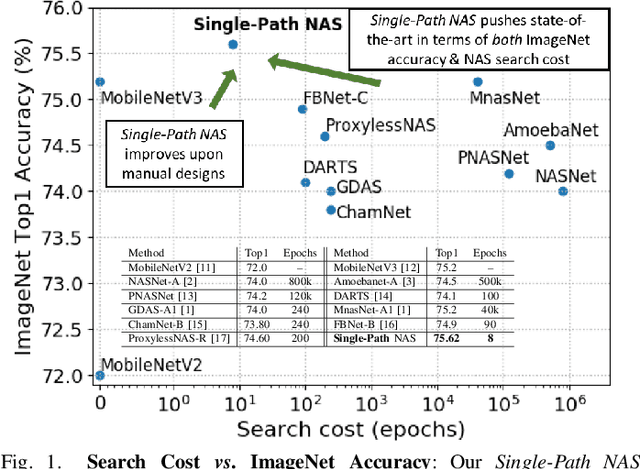
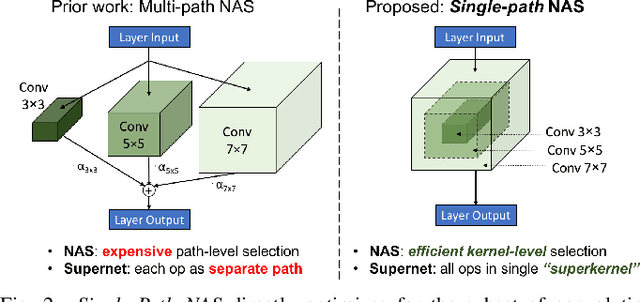
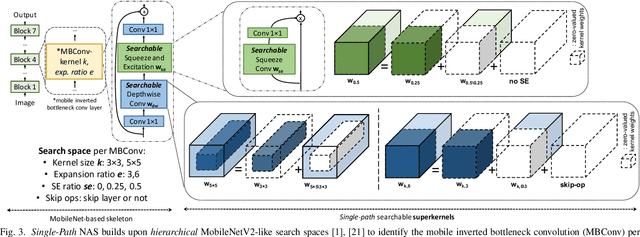
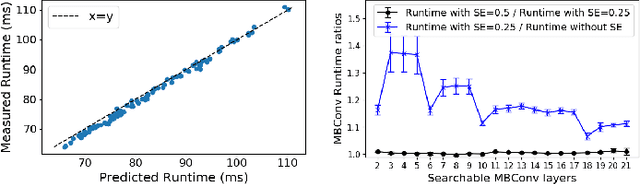
Can we reduce the search cost of Neural Architecture Search (NAS) from days down to only few hours? NAS methods automate the design of Convolutional Networks (ConvNets) under hardware constraints and they have emerged as key components of AutoML frameworks. However, the NAS problem remains challenging due to the combinatorially large design space and the significant search time (at least 200 GPU-hours). In this work, we alleviate the NAS search cost down to less than 3 hours, while achieving state-of-the-art image classification results under mobile latency constraints. We propose a novel differentiable NAS formulation, namely Single-Path NAS, that uses one single-path over-parameterized ConvNet to encode all architectural decisions based on shared convolutional kernel parameters, hence drastically decreasing the search overhead. Single-Path NAS achieves state-of-the-art top-1 ImageNet accuracy (75.62%), hence outperforming existing mobile NAS methods in similar latency settings (~80ms). In particular, we enhance the accuracy-runtime trade-off in differentiable NAS by treating the Squeeze-and-Excitation path as a fully searchable operation with our novel single-path encoding. Our method has an overall cost of only 8 epochs (24 TPU-hours), which is up to 5,000x faster compared to prior work. Moreover, we study how different NAS formulation choices affect the performance of the designed ConvNets. Furthermore, we exploit the efficiency of our method to answer an interesting question: instead of empirically tuning the hyperparameters of the NAS solver (as in prior work), can we automatically find the hyperparameter values that yield the desired accuracy-runtime trade-off? We open-source our entire codebase at: https://github.com/dstamoulis/single-path-nas.
ViP: Virtual Pooling for Accelerating CNN-based Image Classification and Object Detection
Jun 19, 2019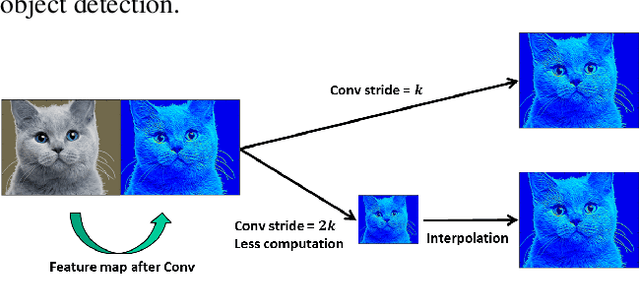

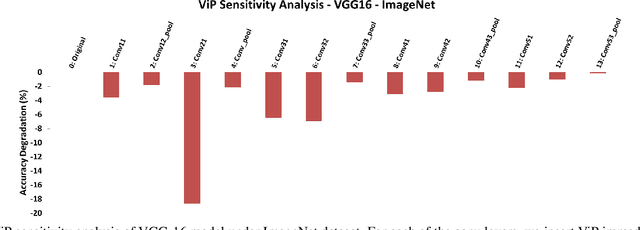
In recent years, Convolutional Neural Networks (CNNs) have shown superior capability in visual learning tasks. While accuracy-wise CNNs provide unprecedented performance, they are also known to be computationally intensive and energy demanding for modern computer systems. In this paper, we propose Virtual Pooling (ViP), a model-level approach to improve speed and energy consumption of CNN-based image classification and object detection tasks, with a provable error bound. We show the efficacy of ViP through experiments on four CNN models, three representative datasets, both desktop and mobile platforms, and two visual learning tasks, i.e., image classification and object detection. For example, ViP delivers 2.1x speedup with less than 1.5% accuracy degradation in ImageNet classification on VGG-16, and 1.8x speedup with 0.025 mAP degradation in PASCAL VOC object detection with Faster-RCNN. ViP also reduces mobile GPU and CPU energy consumption by up to 55% and 70%, respectively. Furthermore, ViP provides a knob for machine learning practitioners to generate a set of CNN models with varying trade-offs between system speed/energy consumption and accuracy to better accommodate the requirements of their tasks. Code is publicly available.
Single-Path NAS: Device-Aware Efficient ConvNet Design
May 10, 2019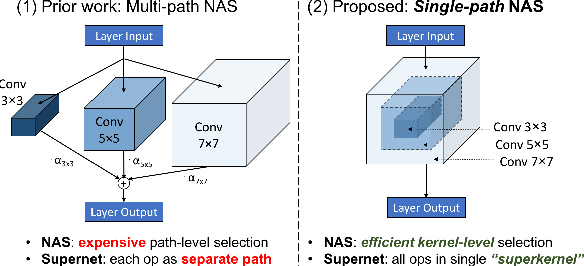
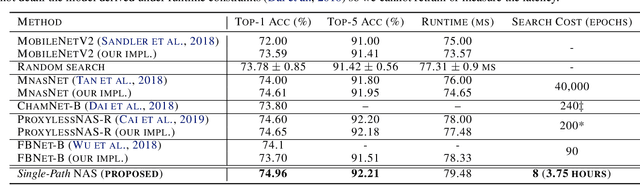
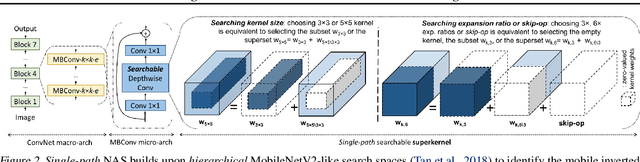
Can we automatically design a Convolutional Network (ConvNet) with the highest image classification accuracy under the latency constraint of a mobile device? Neural Architecture Search (NAS) for ConvNet design is a challenging problem due to the combinatorially large design space and search time (at least 200 GPU-hours). To alleviate this complexity, we propose Single-Path NAS, a novel differentiable NAS method for designing device-efficient ConvNets in less than 4 hours. 1. Novel NAS formulation: our method introduces a single-path, over-parameterized ConvNet to encode all architectural decisions with shared convolutional kernel parameters. 2. NAS efficiency: Our method decreases the NAS search cost down to 8 epochs (30 TPU-hours), i.e., up to 5,000x faster compared to prior work. 3. On-device image classification: Single-Path NAS achieves 74.96% top-1 accuracy on ImageNet with 79ms inference latency on a Pixel 1 phone, which is state-of-the-art accuracy compared to NAS methods with similar latency (<80ms).
LeGR: Filter Pruning via Learned Global Ranking
Apr 28, 2019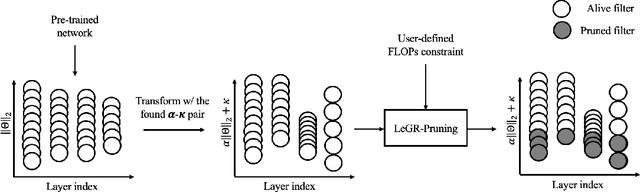
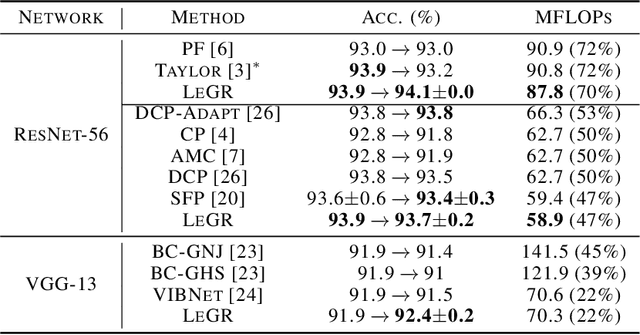
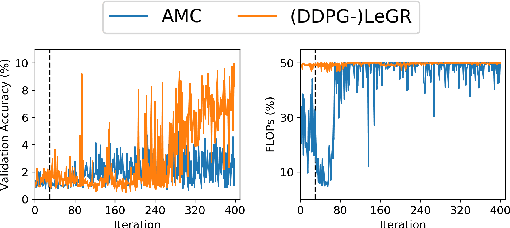
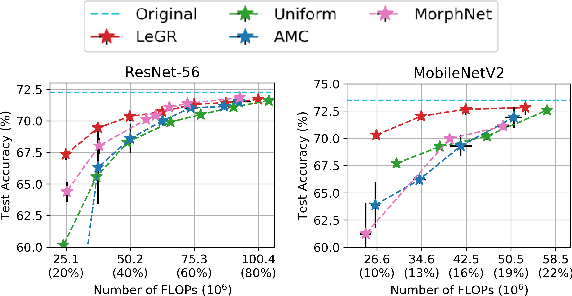
Filter pruning has shown to be effective for learning resource-constrained convolutional neural networks (CNNs). However, prior methods for resource-constrained filter pruning have some limitations that hinder their effectiveness and efficiency. When searching for constraint-satisfying CNNs, prior methods either alter the optimization objective or adopt local search algorithms with heuristic parameterization, which are sub-optimal, especially in low-resource regime. From the efficiency perspective, prior methods are often costly to search for constraint-satisfying CNNs. In this work, we propose learned global ranking, dubbed LeGR, which improves upon prior art in the two aforementioned dimensions. Inspired by theoretical analysis, LeGR is parameterized to learn layer-wise affine transformations over the filter norms to construct a learned global ranking. With global ranking, resource-constrained filter pruning at various constraint levels can be done efficiently. We conduct extensive empirical analyses to demonstrate the effectiveness of the proposed algorithm with ResNet and MobileNetV2 networks on CIFAR-10, CIFAR-100, Bird-200, and ImageNet datasets. Code is publicly available at https://github.com/cmu-enyac/LeGR.
Single-Path NAS: Designing Hardware-Efficient ConvNets in less than 4 Hours
Apr 05, 2019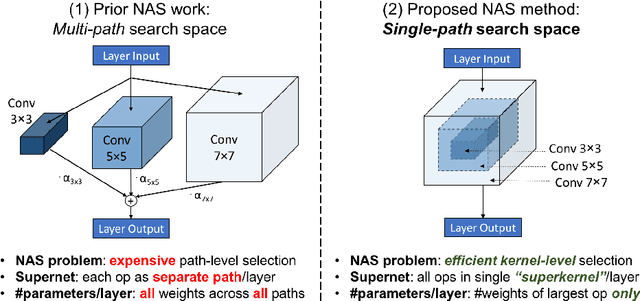
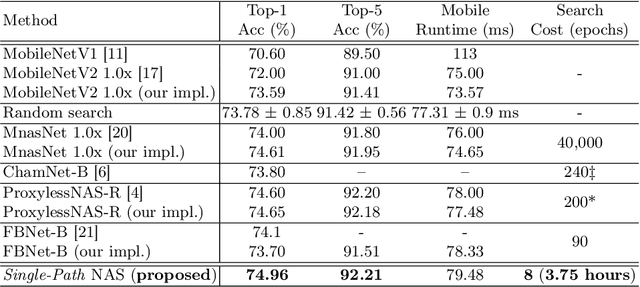
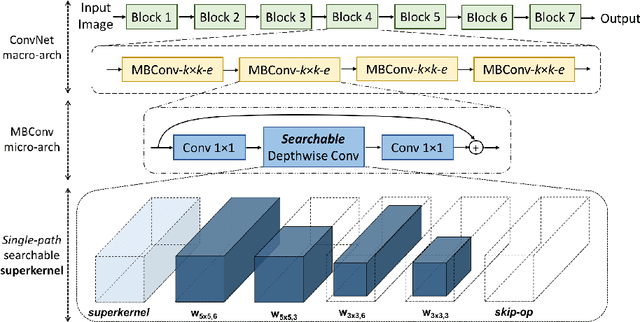

Can we automatically design a Convolutional Network (ConvNet) with the highest image classification accuracy under the runtime constraint of a mobile device? Neural architecture search (NAS) has revolutionized the design of hardware-efficient ConvNets by automating this process. However, the NAS problem remains challenging due to the combinatorially large design space, causing a significant searching time (at least 200 GPU-hours). To alleviate this complexity, we propose Single-Path NAS, a novel differentiable NAS method for designing hardware-efficient ConvNets in less than 4 hours. Our contributions are as follows: 1. Single-path search space: Compared to previous differentiable NAS methods, Single-Path NAS uses one single-path over-parameterized ConvNet to encode all architectural decisions with shared convolutional kernel parameters, hence drastically decreasing the number of trainable parameters and the search cost down to few epochs. 2. Hardware-efficient ImageNet classification: Single-Path NAS achieves 74.96% top-1 accuracy on ImageNet with 79ms latency on a Pixel 1 phone, which is state-of-the-art accuracy compared to NAS methods with similar constraints (<80ms). 3. NAS efficiency: Single-Path NAS search cost is only 8 epochs (30 TPU-hours), which is up to 5,000x faster compared to prior work. 4. Reproducibility: Unlike all recent mobile-efficient NAS methods which only release pretrained models, we open-source our entire codebase at: https://github.com/dstamoulis/single-path-nas.
FLightNNs: Lightweight Quantized Deep Neural Networks for Fast and Accurate Inference
Apr 05, 2019
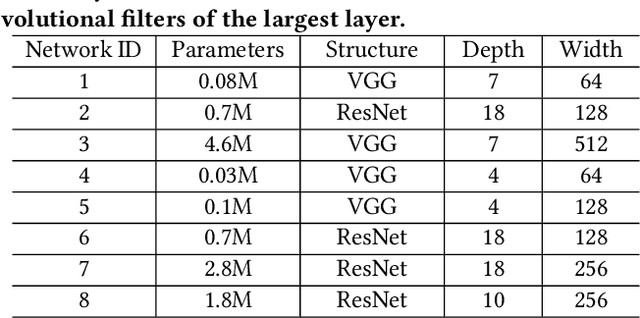
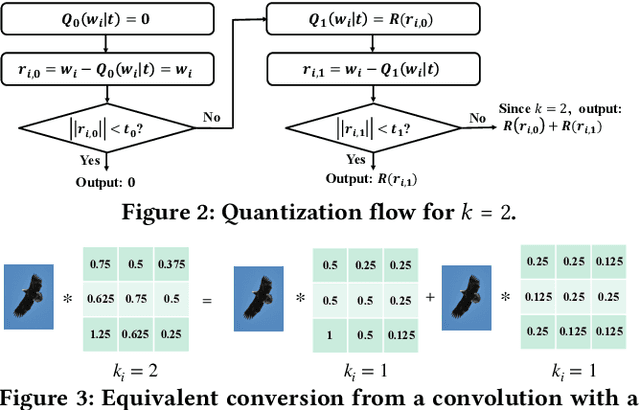
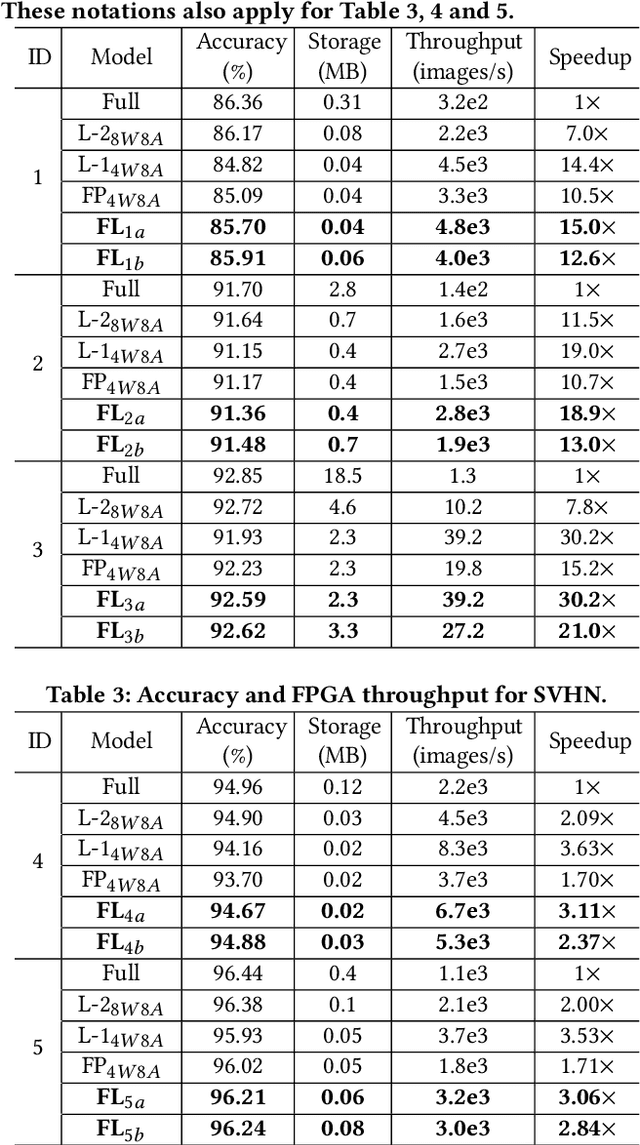
To improve the throughput and energy efficiency of Deep Neural Networks (DNNs) on customized hardware, lightweight neural networks constrain the weights of DNNs to be a limited combination (denoted as $k\in\{1,2\}$) of powers of 2. In such networks, the multiply-accumulate operation can be replaced with a single shift operation, or two shifts and an add operation. To provide even more design flexibility, the $k$ for each convolutional filter can be optimally chosen instead of being fixed for every filter. In this paper, we formulate the selection of $k$ to be differentiable, and describe model training for determining $k$-based weights on a per-filter basis. Over 46 FPGA-design experiments involving eight configurations and four data sets reveal that lightweight neural networks with a flexible $k$ value (dubbed FLightNNs) fully utilize the hardware resources on Field Programmable Gate Arrays (FPGAs), our experimental results show that FLightNNs can achieve 2$\times$ speedup when compared to lightweight NNs with $k=2$, with only 0.1\% accuracy degradation. Compared to a 4-bit fixed-point quantization, FLightNNs achieve higher accuracy and up to 2$\times$ inference speedup, due to their lightweight shift operations. In addition, our experiments also demonstrate that FLightNNs can achieve higher computational energy efficiency for ASIC implementation.
Regularizing Activation Distribution for Training Binarized Deep Networks
Apr 04, 2019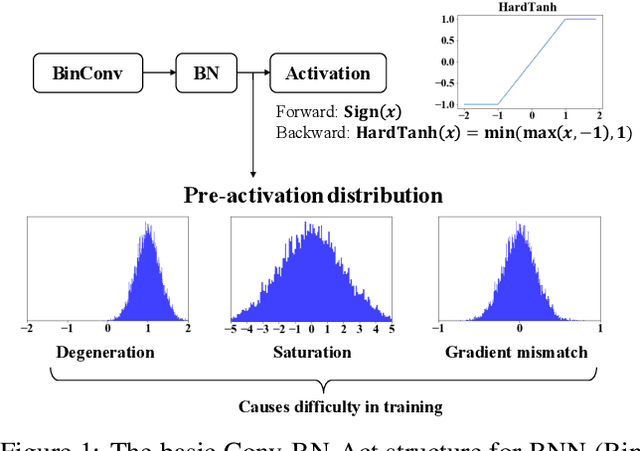
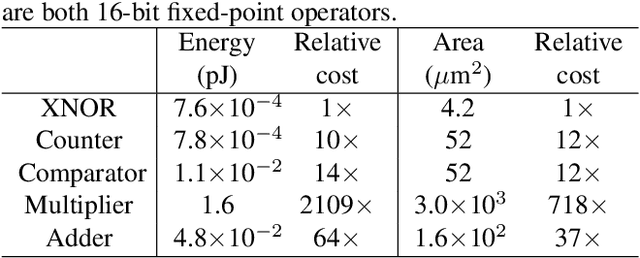
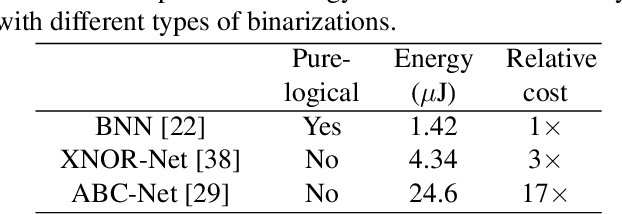
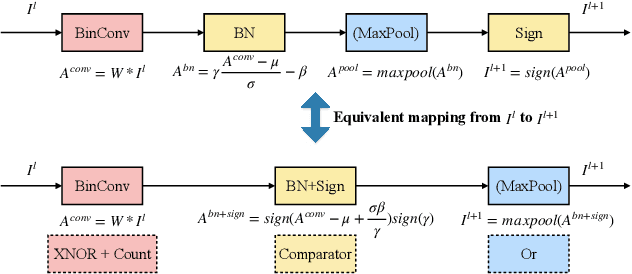
Binarized Neural Networks (BNNs) can significantly reduce the inference latency and energy consumption in resource-constrained devices due to their pure-logical computation and fewer memory accesses. However, training BNNs is difficult since the activation flow encounters degeneration, saturation, and gradient mismatch problems. Prior work alleviates these issues by increasing activation bits and adding floating-point scaling factors, thereby sacrificing BNN's energy efficiency. In this paper, we propose to use distribution loss to explicitly regularize the activation flow, and develop a framework to systematically formulate the loss. Our experiments show that the distribution loss can consistently improve the accuracy of BNNs without losing their energy benefits. Moreover, equipped with the proposed regularization, BNN training is shown to be robust to the selection of hyper-parameters including optimizer and learning rate.