 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThird ArchEdge Workshop: Exploring the Design Space of Efficient Deep Neural Networks
Nov 22, 2020This paper gives an overview of our ongoing work on the design space exploration of efficient deep neural networks (DNNs). Specifically, we cover two aspects: (1) static architecture design efficiency and (2) dynamic model execution efficiency. For static architecture design, different from existing end-to-end hardware modeling assumptions, we conduct full-stack profiling at the GPU core level to identify better accuracy-latency trade-offs for DNN designs. For dynamic model execution, different from prior work that tackles model redundancy at the DNN-channels level, we explore a new dimension of DNN feature map redundancy to be dynamically traversed at runtime. Last, we highlight several open questions that are poised to draw research attention in the next few years.
Unsupervised Domain Adaptation for Object Detection via Cross-Domain Semi-Supervised Learning
Nov 24, 2019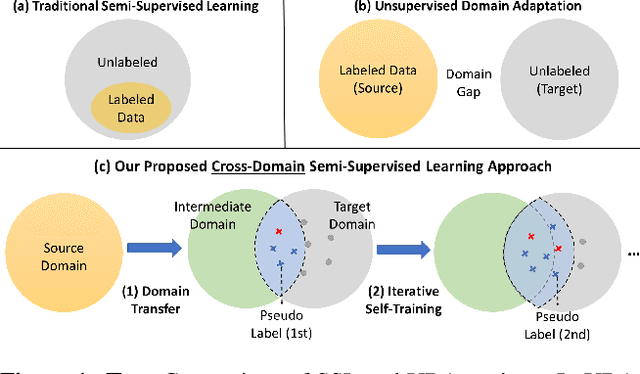
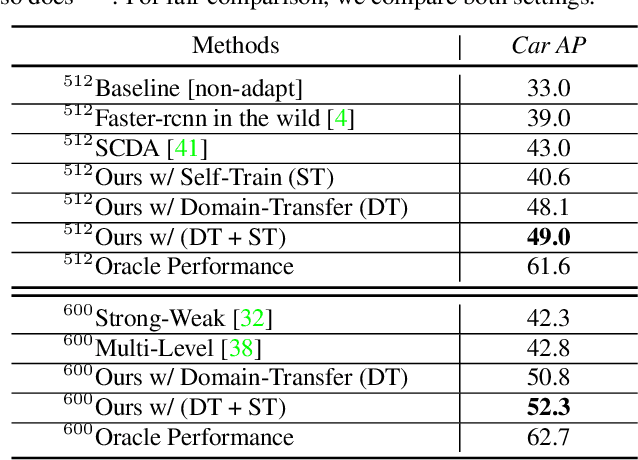
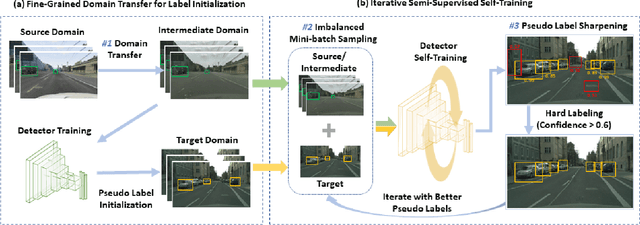
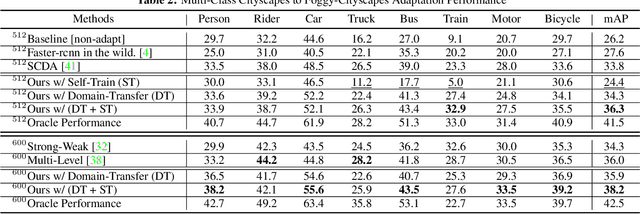
Current state-of-the-art object detectors can have significant performance drop when deployed in the wild due to domain gaps with training data. Unsupervised Domain Adaptation (UDA) is a promising approach to adapt models for new domains/environments without any expensive label cost. However, without ground truth labels, most prior works on UDA for object detection tasks can only perform coarse image-level and/or feature-level adaptation by using adversarial learning methods. In this work, we show that such adversarial-based methods can only reduce the domain style gap, but cannot address the domain content distribution gap that is shown to be important for object detectors. To overcome this limitation, we propose the Cross-Domain Semi-Supervised Learning (CDSSL) framework by leveraging high-quality pseudo labels to learn better representations from the target domain directly. To enable SSL for cross-domain object detection, we propose fine-grained domain transfer, progressive-confidence-based label sharpening and imbalanced sampling strategy to address two challenges: (i) non-identical distribution between source and target domain data, (ii) error amplification/accumulation due to noisy pseudo labeling on the target domain. Experiment results show that our proposed approach consistently achieves new state-of-the-art performance (2.2% - 9.5% better than prior best work on mAP) under various domain gap scenarios. The code will be released.
Single-Path Mobile AutoML: Efficient ConvNet Design and NAS Hyperparameter Optimization
Jul 01, 2019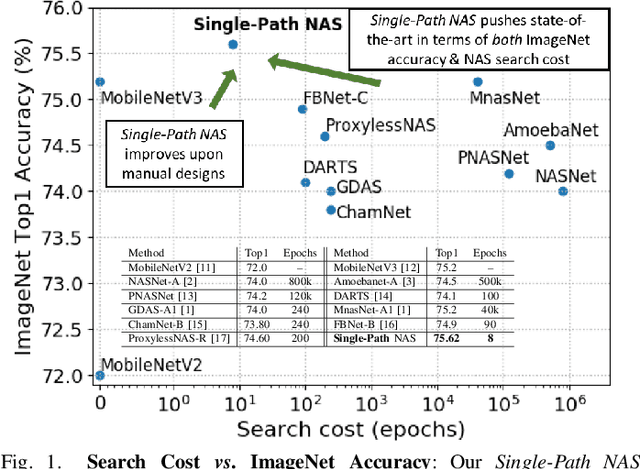
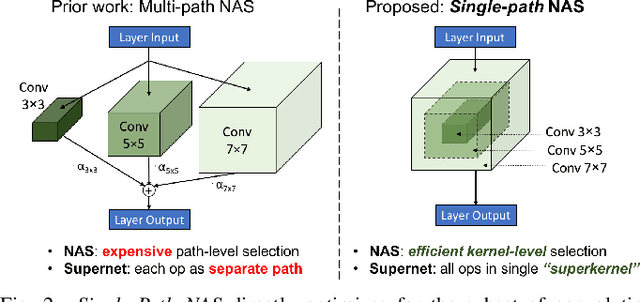
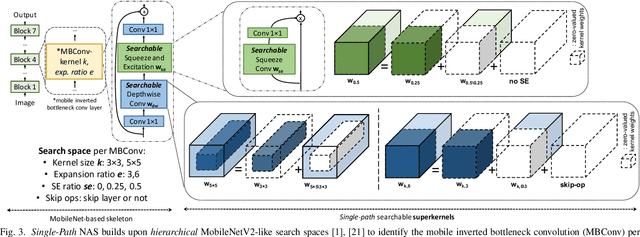
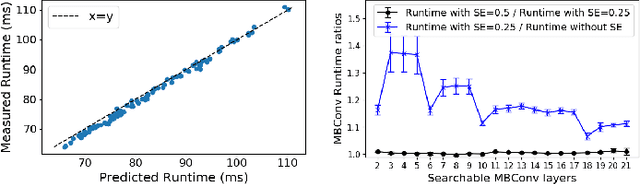
Can we reduce the search cost of Neural Architecture Search (NAS) from days down to only few hours? NAS methods automate the design of Convolutional Networks (ConvNets) under hardware constraints and they have emerged as key components of AutoML frameworks. However, the NAS problem remains challenging due to the combinatorially large design space and the significant search time (at least 200 GPU-hours). In this work, we alleviate the NAS search cost down to less than 3 hours, while achieving state-of-the-art image classification results under mobile latency constraints. We propose a novel differentiable NAS formulation, namely Single-Path NAS, that uses one single-path over-parameterized ConvNet to encode all architectural decisions based on shared convolutional kernel parameters, hence drastically decreasing the search overhead. Single-Path NAS achieves state-of-the-art top-1 ImageNet accuracy (75.62%), hence outperforming existing mobile NAS methods in similar latency settings (~80ms). In particular, we enhance the accuracy-runtime trade-off in differentiable NAS by treating the Squeeze-and-Excitation path as a fully searchable operation with our novel single-path encoding. Our method has an overall cost of only 8 epochs (24 TPU-hours), which is up to 5,000x faster compared to prior work. Moreover, we study how different NAS formulation choices affect the performance of the designed ConvNets. Furthermore, we exploit the efficiency of our method to answer an interesting question: instead of empirically tuning the hyperparameters of the NAS solver (as in prior work), can we automatically find the hyperparameter values that yield the desired accuracy-runtime trade-off? We open-source our entire codebase at: https://github.com/dstamoulis/single-path-nas.
Single-Path NAS: Device-Aware Efficient ConvNet Design
May 10, 2019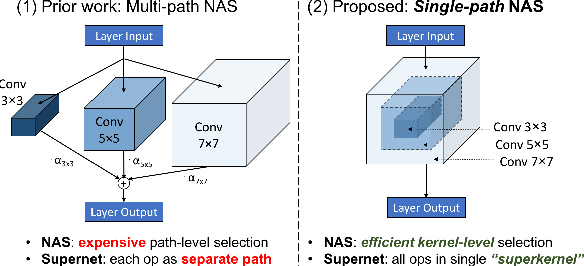
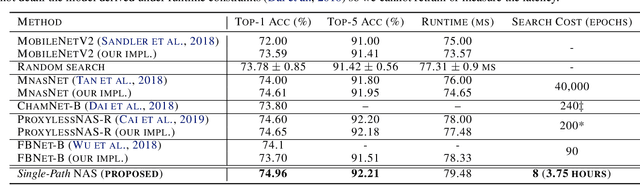
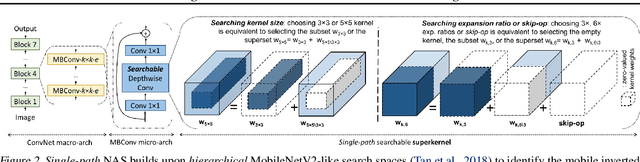
Can we automatically design a Convolutional Network (ConvNet) with the highest image classification accuracy under the latency constraint of a mobile device? Neural Architecture Search (NAS) for ConvNet design is a challenging problem due to the combinatorially large design space and search time (at least 200 GPU-hours). To alleviate this complexity, we propose Single-Path NAS, a novel differentiable NAS method for designing device-efficient ConvNets in less than 4 hours. 1. Novel NAS formulation: our method introduces a single-path, over-parameterized ConvNet to encode all architectural decisions with shared convolutional kernel parameters. 2. NAS efficiency: Our method decreases the NAS search cost down to 8 epochs (30 TPU-hours), i.e., up to 5,000x faster compared to prior work. 3. On-device image classification: Single-Path NAS achieves 74.96% top-1 accuracy on ImageNet with 79ms inference latency on a Pixel 1 phone, which is state-of-the-art accuracy compared to NAS methods with similar latency (<80ms).
Single-Path NAS: Designing Hardware-Efficient ConvNets in less than 4 Hours
Apr 05, 2019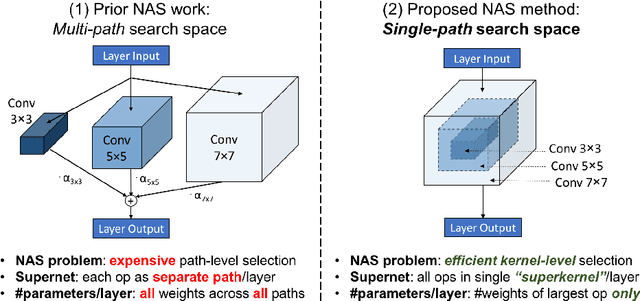
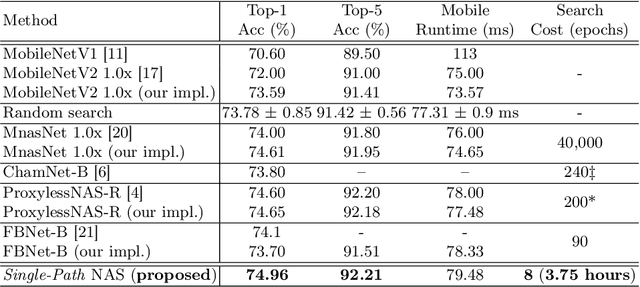
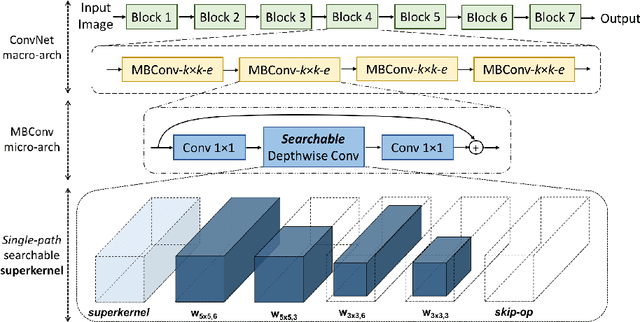

Can we automatically design a Convolutional Network (ConvNet) with the highest image classification accuracy under the runtime constraint of a mobile device? Neural architecture search (NAS) has revolutionized the design of hardware-efficient ConvNets by automating this process. However, the NAS problem remains challenging due to the combinatorially large design space, causing a significant searching time (at least 200 GPU-hours). To alleviate this complexity, we propose Single-Path NAS, a novel differentiable NAS method for designing hardware-efficient ConvNets in less than 4 hours. Our contributions are as follows: 1. Single-path search space: Compared to previous differentiable NAS methods, Single-Path NAS uses one single-path over-parameterized ConvNet to encode all architectural decisions with shared convolutional kernel parameters, hence drastically decreasing the number of trainable parameters and the search cost down to few epochs. 2. Hardware-efficient ImageNet classification: Single-Path NAS achieves 74.96% top-1 accuracy on ImageNet with 79ms latency on a Pixel 1 phone, which is state-of-the-art accuracy compared to NAS methods with similar constraints (<80ms). 3. NAS efficiency: Single-Path NAS search cost is only 8 epochs (30 TPU-hours), which is up to 5,000x faster compared to prior work. 4. Reproducibility: Unlike all recent mobile-efficient NAS methods which only release pretrained models, we open-source our entire codebase at: https://github.com/dstamoulis/single-path-nas.