 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeU-Net Based Image Enhancement for Short-time Muon Scattering Tomography
Feb 05, 2026Muon Scattering Tomography (MST) is a promising non-invasive inspection technique, yet the practical application of short-time MST is hindered by poor image quality due to limited muon flux. To address this limitation, we propose a U-Net-based framework trained on Point of Closest Approach (PoCA) images reconstructed with simulation MST data to enhance image quality. When applied to experimental MST data, the framework significantly improves image quality, increasing the Structural Similarity Index Measure (SSIM) from 0.7232 to 0.9699 and decreasing the Learned Perceptual Image Patch Similarity (LPIPS) from 0.3604 to 0.0270. These results demonstrate that our method can effectively enhance low-statistics MST images, thereby paving the way for the practical deployment of short-time MST.
Should All Proposals be Treated Equally in Object Detection?
Jul 07, 2022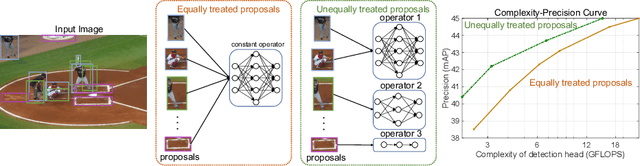
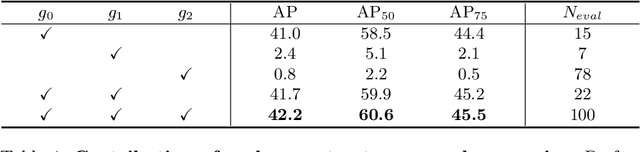
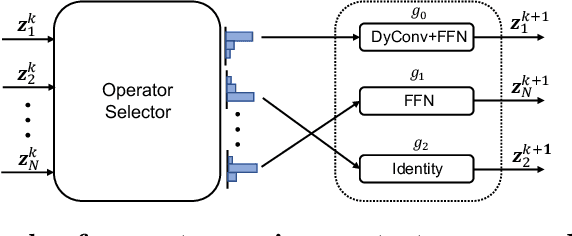
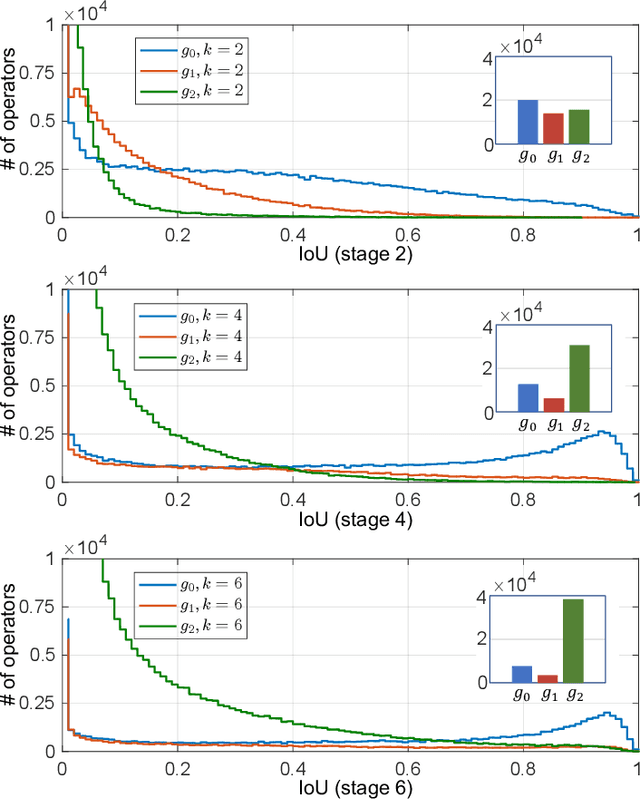
The complexity-precision trade-off of an object detector is a critical problem for resource constrained vision tasks. Previous works have emphasized detectors implemented with efficient backbones. The impact on this trade-off of proposal processing by the detection head is investigated in this work. It is hypothesized that improved detection efficiency requires a paradigm shift, towards the unequal processing of proposals, assigning more computation to good proposals than poor ones. This results in better utilization of available computational budget, enabling higher accuracy for the same FLOPS. We formulate this as a learning problem where the goal is to assign operators to proposals, in the detection head, so that the total computational cost is constrained and the precision is maximized. The key finding is that such matching can be learned as a function that maps each proposal embedding into a one-hot code over operators. While this function induces a complex dynamic network routing mechanism, it can be implemented by a simple MLP and learned end-to-end with off-the-shelf object detectors. This 'dynamic proposal processing' (DPP) is shown to outperform state-of-the-art end-to-end object detectors (DETR, Sparse R-CNN) by a clear margin for a given computational complexity.
ConSLT: A Token-level Contrastive Framework for Sign Language Translation
Apr 11, 2022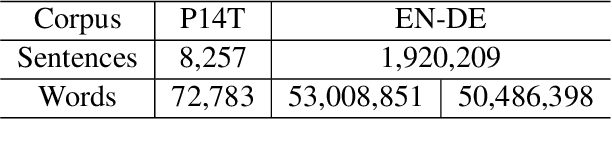
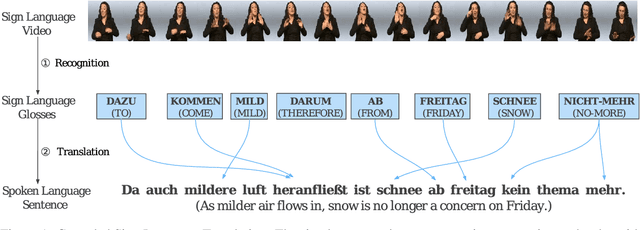
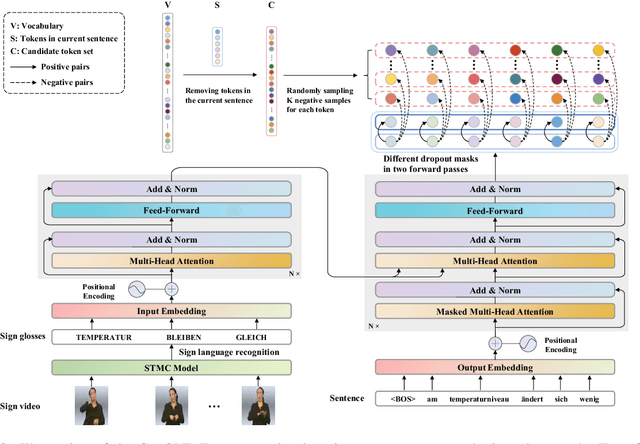
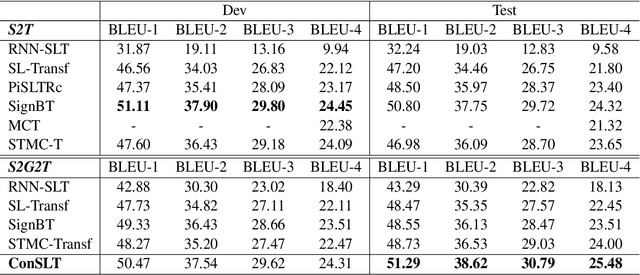
Sign language translation (SLT) is an important technology that can bridge the communication gap between the deaf and the hearing people. SLT task is essentially a low-resource problem due to the scarcity of publicly available parallel data. To this end, inspired by the success of neural machine translation methods based on contrastive learning, we propose ConSLT, a novel token-level \textbf{Con}trastive learning framework for \textbf{S}ign \textbf{L}anguage \textbf{T}ranslation. Unlike previous contrastive learning based works whose goal is to obtain better sentence representation, ConSLT aims to learn effective token representation by pushing apart tokens from different sentences. Concretely, our model follows the two-stage SLT method. First, in the recoginition stage, we use a state-of-the-art continuous sign language recognition model to recognize glosses from sign frames. Then, in the translation stage, we adopt the Transformer framework while introducing contrastive learning. Specifically, we pass each sign glosses to the Transformer model twice to obtain two different hidden layer representations for each token as "positive examples" and randomly sample K tokens that are not in the current sentence from the vocabulary as "negative examples" for each token. Experimental results demonstrate that ConSLT achieves new state-of-the-art performance on PHOENIX14T dataset, with +1.48 BLEU improvements.
The Overlooked Classifier in Human-Object Interaction Recognition
Mar 10, 2022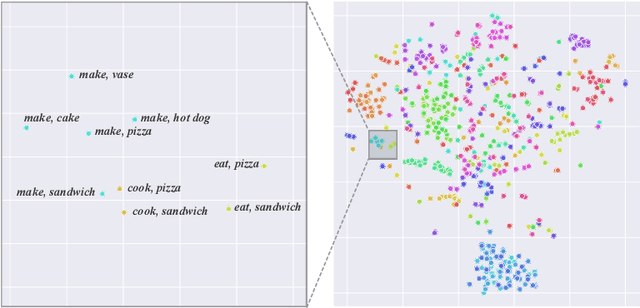
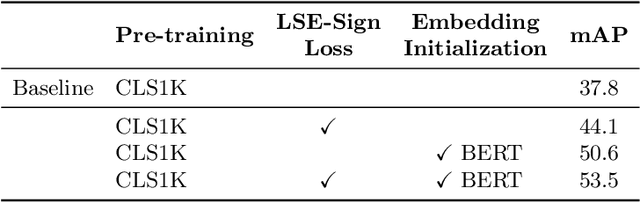
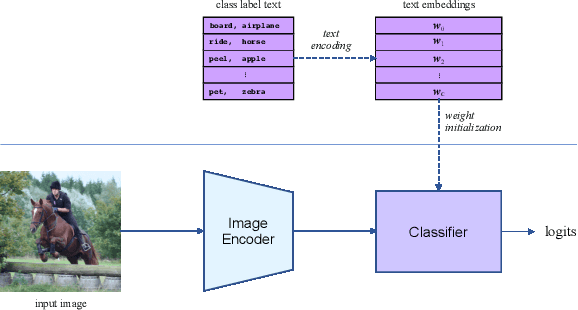

Human-Object Interaction (HOI) recognition is challenging due to two factors: (1) significant imbalance across classes and (2) requiring multiple labels per image. This paper shows that these two challenges can be effectively addressed by improving the classifier with the backbone architecture untouched. Firstly, we encode the semantic correlation among classes into the classification head by initializing the weights with language embeddings of HOIs. As a result, the performance is boosted significantly, especially for the few-shot subset. Secondly, we propose a new loss named LSE-Sign to enhance multi-label learning on a long-tailed dataset. Our simple yet effective method enables detection-free HOI classification, outperforming the state-of-the-arts that require object detection and human pose by a clear margin. Moreover, we transfer the classification model to instance-level HOI detection by connecting it with an off-the-shelf object detector. We achieve state-of-the-art without additional fine-tuning.
SA-VQA: Structured Alignment of Visual and Semantic Representations for Visual Question Answering
Jan 25, 2022Visual Question Answering (VQA) attracts much attention from both industry and academia. As a multi-modality task, it is challenging since it requires not only visual and textual understanding, but also the ability to align cross-modality representations. Previous approaches extensively employ entity-level alignments, such as the correlations between the visual regions and their semantic labels, or the interactions across question words and object features. These attempts aim to improve the cross-modality representations, while ignoring their internal relations. Instead, we propose to apply structured alignments, which work with graph representation of visual and textual content, aiming to capture the deep connections between the visual and textual modalities. Nevertheless, it is nontrivial to represent and integrate graphs for structured alignments. In this work, we attempt to solve this issue by first converting different modality entities into sequential nodes and the adjacency graph, then incorporating them for structured alignments. As demonstrated in our experimental results, such a structured alignment improves reasoning performance. In addition, our model also exhibits better interpretability for each generated answer. The proposed model, without any pretraining, outperforms the state-of-the-art methods on GQA dataset, and beats the non-pretrained state-of-the-art methods on VQA-v2 dataset.
Decoupling Object Detection from Human-Object Interaction Recognition
Dec 13, 2021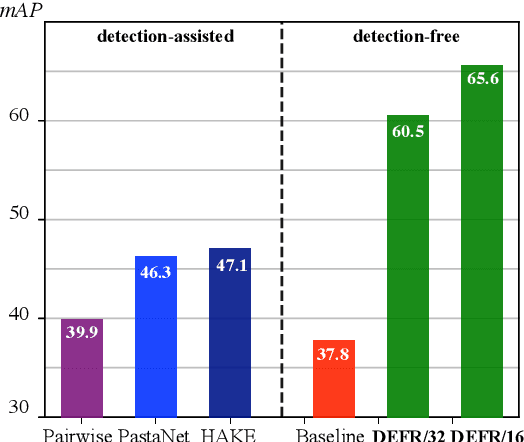

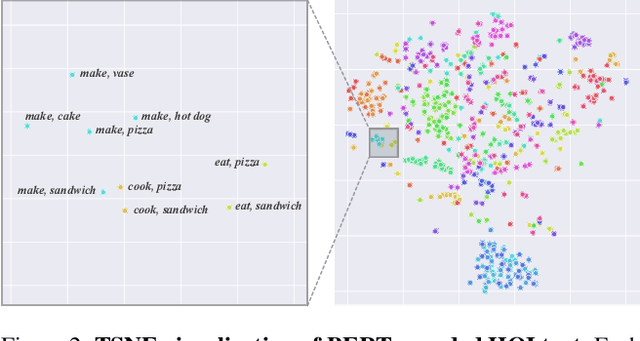
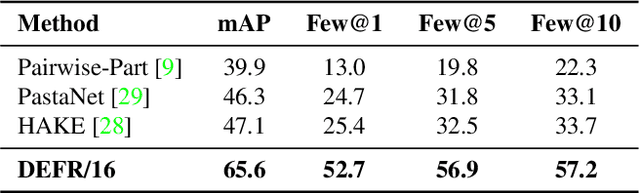
We propose DEFR, a DEtection-FRee method to recognize Human-Object Interactions (HOI) at image level without using object location or human pose. This is challenging as the detector is an integral part of existing methods. In this paper, we propose two findings to boost the performance of the detection-free approach, which significantly outperforms the detection-assisted state of the arts. Firstly, we find it crucial to effectively leverage the semantic correlations among HOI classes. Remarkable gain can be achieved by using language embeddings of HOI labels to initialize the linear classifier, which encodes the structure of HOIs to guide training. Further, we propose Log-Sum-Exp Sign (LSE-Sign) loss to facilitate multi-label learning on a long-tailed dataset by balancing gradients over all classes in a softmax format. Our detection-free approach achieves 65.6 mAP in HOI classification on HICO, outperforming the detection-assisted state of the art (SOTA) by 18.5 mAP, and 52.7 mAP in one-shot classes, surpassing the SOTA by 27.3 mAP. Different from previous work, our classification model (DEFR) can be directly used in HOI detection without any additional training, by connecting to an off-the-shelf object detector whose bounding box output is converted to binary masks for DEFR. Surprisingly, such a simple connection of two decoupled models achieves SOTA performance (32.35 mAP).
Improving Vision Transformers for Incremental Learning
Dec 12, 2021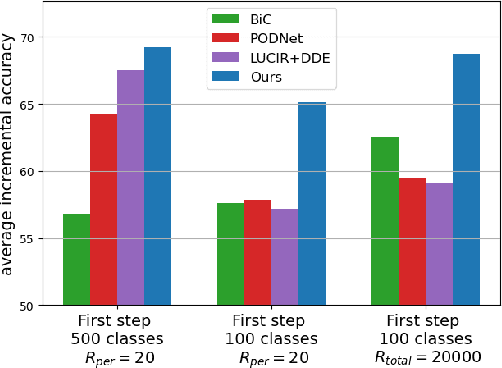
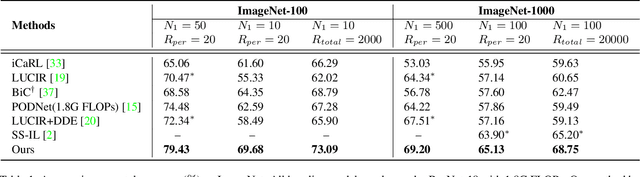
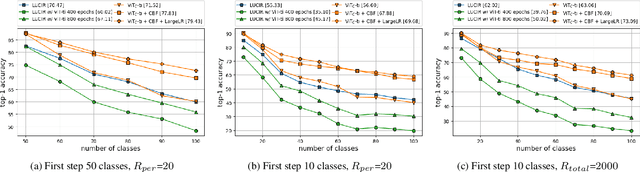
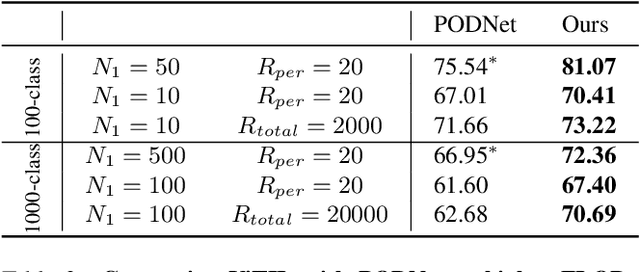
This paper studies using Vision Transformers (ViT) in class incremental learning. Surprisingly, naive application of ViT to replace convolutional neural networks (CNNs) results in performance degradation. Our analysis reveals three issues of naively using ViT: (a) ViT has very slow convergence when class number is small, (b) more bias towards new classes is observed in ViT than CNN-based models, and (c) the proper learning rate of ViT is too low to learn a good classifier. Base on this analysis, we show these issues can be simply addressed by using existing techniques: using convolutional stem, balanced finetuning to correct bias, and higher learning rate for the classifier. Our simple solution, named ViTIL (ViT for Incremental Learning), achieves the new state-of-the-art for all three class incremental learning setups by a clear margin, providing a strong baseline for the research community. For instance, on ImageNet-1000, our ViTIL achieves 69.20% top-1 accuracy for the protocol of 500 initial classes with 5 incremental steps (100 new classes for each), outperforming LUCIR+DDE by 1.69%. For more challenging protocol of 10 incremental steps (100 new classes), our method outperforms PODNet by 7.27% (65.13% vs. 57.86%).
Is Object Detection Necessary for Human-Object Interaction Recognition?
Jul 27, 2021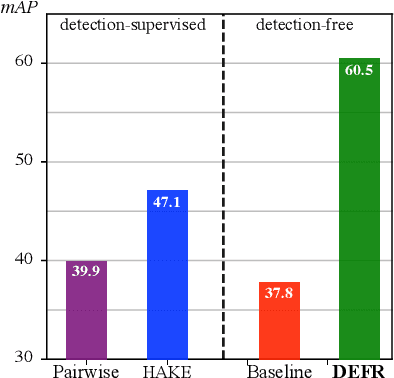
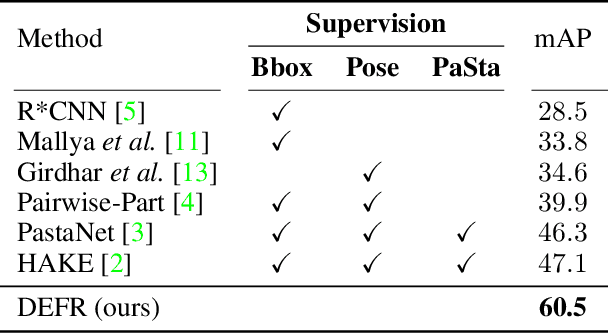
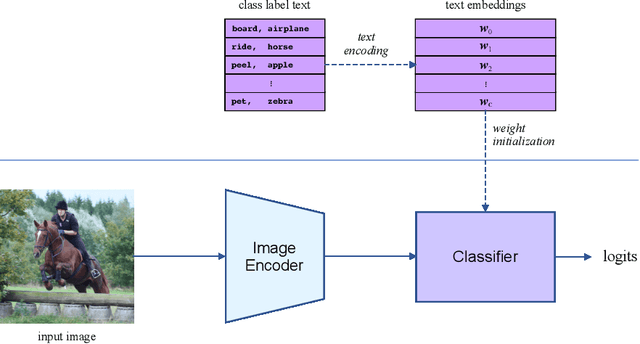

This paper revisits human-object interaction (HOI) recognition at image level without using supervisions of object location and human pose. We name it detection-free HOI recognition, in contrast to the existing detection-supervised approaches which rely on object and keypoint detections to achieve state of the art. With our method, not only the detection supervision is evitable, but superior performance can be achieved by properly using image-text pre-training (such as CLIP) and the proposed Log-Sum-Exp Sign (LSE-Sign) loss function. Specifically, using text embeddings of class labels to initialize the linear classifier is essential for leveraging the CLIP pre-trained image encoder. In addition, LSE-Sign loss facilitates learning from multiple labels on an imbalanced dataset by normalizing gradients over all classes in a softmax format. Surprisingly, our detection-free solution achieves 60.5 mAP on the HICO dataset, outperforming the detection-supervised state of the art by 13.4 mAP
A Unified Transferable Model for ML-Enhanced DBMS
May 06, 2021
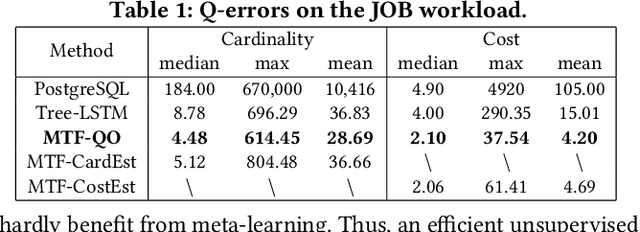
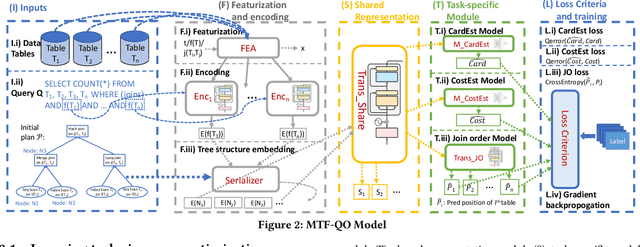
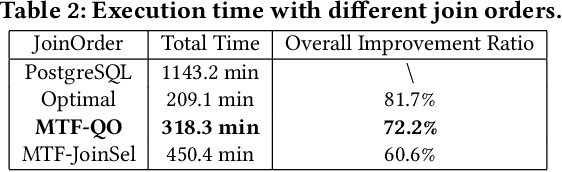
Recently, the database management system (DBMS) community has witnessed the power of machine learning (ML) solutions for DBMS tasks. Despite their promising performance, these existing solutions can hardly be considered satisfactory. First, these ML-based methods in DBMS are not effective enough because they are optimized on each specific task, and cannot explore or understand the intrinsic connections between tasks. Second, the training process has serious limitations that hinder their practicality, because they need to retrain the entire model from scratch for a new DB. Moreover, for each retraining, they require an excessive amount of training data, which is very expensive to acquire and unavailable for a new DB. We propose to explore the transferabilities of the ML methods both across tasks and across DBs to tackle these fundamental drawbacks. In this paper, we propose a unified model MTMLF that uses a multi-task training procedure to capture the transferable knowledge across tasks and a pretrain finetune procedure to distill the transferable meta knowledge across DBs. We believe this paradigm is more suitable for cloud DB service, and has the potential to revolutionize the way how ML is used in DBMS. Furthermore, to demonstrate the predicting power and viability of MTMLF, we provide a concrete and very promising case study on query optimization tasks. Last but not least, we discuss several concrete research opportunities along this line of work.
Unsupervised Domain Adaptation for Object Detection via Cross-Domain Semi-Supervised Learning
Nov 24, 2019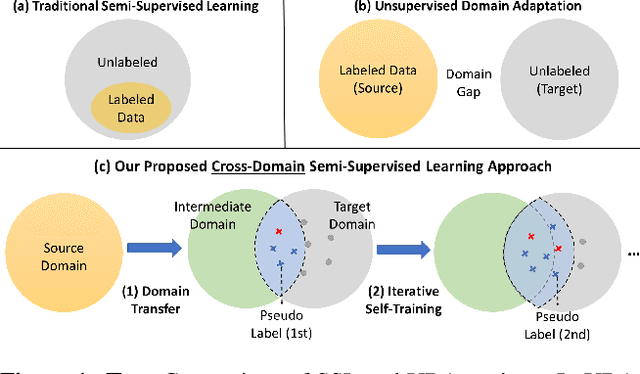
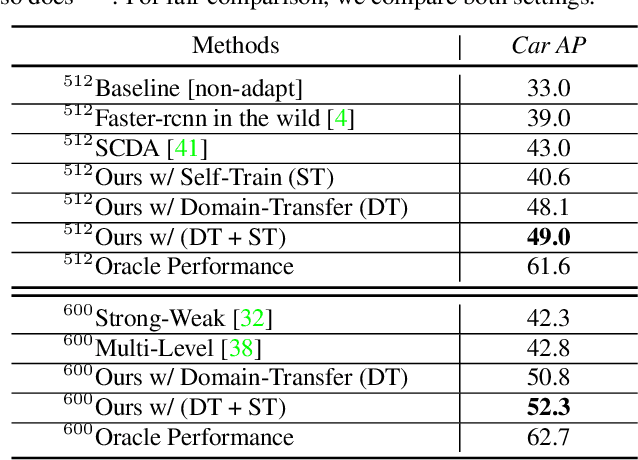
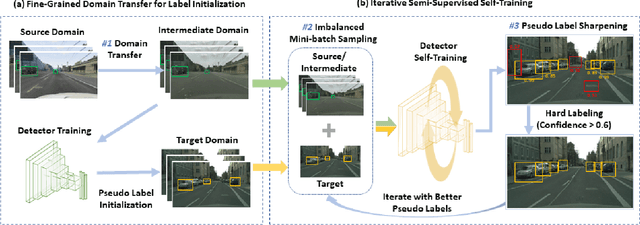
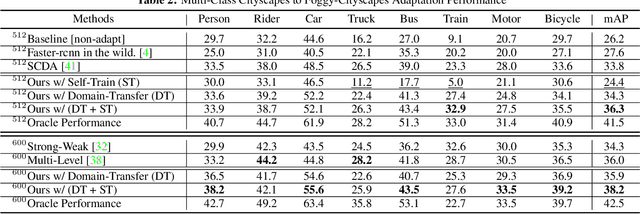
Current state-of-the-art object detectors can have significant performance drop when deployed in the wild due to domain gaps with training data. Unsupervised Domain Adaptation (UDA) is a promising approach to adapt models for new domains/environments without any expensive label cost. However, without ground truth labels, most prior works on UDA for object detection tasks can only perform coarse image-level and/or feature-level adaptation by using adversarial learning methods. In this work, we show that such adversarial-based methods can only reduce the domain style gap, but cannot address the domain content distribution gap that is shown to be important for object detectors. To overcome this limitation, we propose the Cross-Domain Semi-Supervised Learning (CDSSL) framework by leveraging high-quality pseudo labels to learn better representations from the target domain directly. To enable SSL for cross-domain object detection, we propose fine-grained domain transfer, progressive-confidence-based label sharpening and imbalanced sampling strategy to address two challenges: (i) non-identical distribution between source and target domain data, (ii) error amplification/accumulation due to noisy pseudo labeling on the target domain. Experiment results show that our proposed approach consistently achieves new state-of-the-art performance (2.2% - 9.5% better than prior best work on mAP) under various domain gap scenarios. The code will be released.