 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDASK: Distribution Rehearsing via Adaptive Style Kernel Learning for Exemplar-Free Lifelong Person Re-Identification
Dec 12, 2024



Lifelong person re-identification (LReID) is an important but challenging task that suffers from catastrophic forgetting due to significant domain gaps between training steps. Existing LReID approaches typically rely on data replay and knowledge distillation to mitigate this issue. However, data replay methods compromise data privacy by storing historical exemplars, while knowledge distillation methods suffer from limited performance due to the cumulative forgetting of undistilled knowledge. To overcome these challenges, we propose a novel paradigm that models and rehearses the distribution of the old domains to enhance knowledge consolidation during the new data learning, possessing a strong anti-forgetting capacity without storing any exemplars. Specifically, we introduce an exemplar-free LReID method called Distribution Rehearsing via Adaptive Style Kernel Learning (DASK). DASK includes a Distribution Rehearser Learning mechanism that learns to transform arbitrary distribution data into the current data style at each learning step. To enhance the style transfer capacity of DRL, an Adaptive Kernel Prediction network is explored to achieve an instance-specific distribution adjustment. Additionally, we design a Distribution Rehearsing-driven LReID Training module, which rehearses old distribution based on the new data via the old AKPNet model, achieving effective new-old knowledge accumulation under a joint knowledge consolidation scheme. Experimental results show our DASK outperforms the existing methods by 3.6%-6.8% and 4.5%-6.5% on anti-forgetting and generalization capacity, respectively. Our code is available at https://github.com/zhoujiahuan1991/AAAI2025-DASK
MGA-VQA: Multi-Granularity Alignment for Visual Question Answering
Jan 25, 2022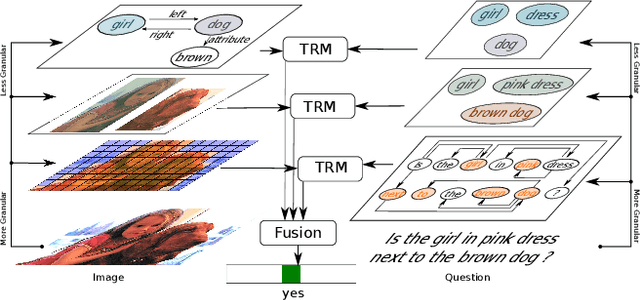



Learning to answer visual questions is a challenging task since the multi-modal inputs are within two feature spaces. Moreover, reasoning in visual question answering requires the model to understand both image and question, and align them in the same space, rather than simply memorize statistics about the question-answer pairs. Thus, it is essential to find component connections between different modalities and within each modality to achieve better attention. Previous works learned attention weights directly on the features. However, the improvement is limited since these two modality features are in two domains: image features are highly diverse, lacking structure and grammatical rules as language, and natural language features have a higher probability of missing detailed information. To better learn the attention between visual and text, we focus on how to construct input stratification and embed structural information to improve the alignment between different level components. We propose Multi-Granularity Alignment architecture for Visual Question Answering task (MGA-VQA), which learns intra- and inter-modality correlations by multi-granularity alignment, and outputs the final result by the decision fusion module. In contrast to previous works, our model splits alignment into different levels to achieve learning better correlations without needing additional data and annotations. The experiments on the VQA-v2 and GQA datasets demonstrate that our model significantly outperforms non-pretrained state-of-the-art methods on both datasets without extra pretraining data and annotations. Moreover, it even achieves better results over the pre-trained methods on GQA.
SA-VQA: Structured Alignment of Visual and Semantic Representations for Visual Question Answering
Jan 25, 2022Visual Question Answering (VQA) attracts much attention from both industry and academia. As a multi-modality task, it is challenging since it requires not only visual and textual understanding, but also the ability to align cross-modality representations. Previous approaches extensively employ entity-level alignments, such as the correlations between the visual regions and their semantic labels, or the interactions across question words and object features. These attempts aim to improve the cross-modality representations, while ignoring their internal relations. Instead, we propose to apply structured alignments, which work with graph representation of visual and textual content, aiming to capture the deep connections between the visual and textual modalities. Nevertheless, it is nontrivial to represent and integrate graphs for structured alignments. In this work, we attempt to solve this issue by first converting different modality entities into sequential nodes and the adjacency graph, then incorporating them for structured alignments. As demonstrated in our experimental results, such a structured alignment improves reasoning performance. In addition, our model also exhibits better interpretability for each generated answer. The proposed model, without any pretraining, outperforms the state-of-the-art methods on GQA dataset, and beats the non-pretrained state-of-the-art methods on VQA-v2 dataset.
Visual Query Answering by Entity-Attribute Graph Matching and Reasoning
Mar 16, 2019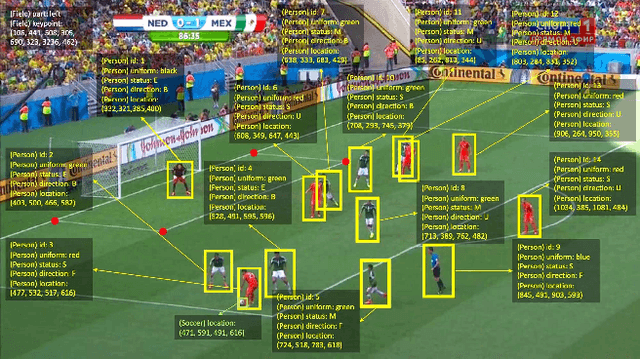
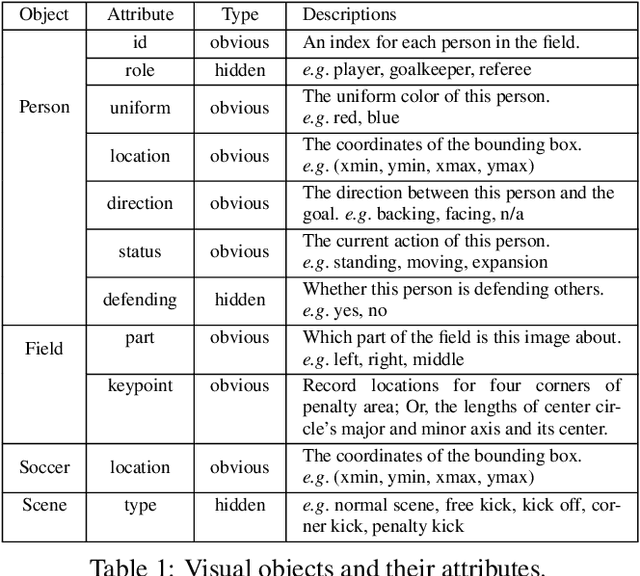

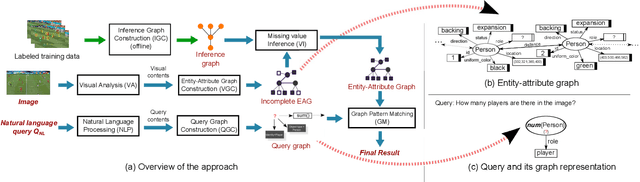
Visual Query Answering (VQA) is of great significance in offering people convenience: one can raise a question for details of objects, or high-level understanding about the scene, over an image. This paper proposes a novel method to address the VQA problem. In contrast to prior works, our method that targets single scene VQA, replies on graph-based techniques and involves reasoning. In a nutshell, our approach is centered on three graphs. The first graph, referred to as inference graph GI , is constructed via learning over labeled data. The other two graphs, referred to as query graph Q and entity-attribute graph GEA, are generated from natural language query Qnl and image Img, that are issued from users, respectively. As GEA often does not take sufficient information to answer Q, we develop techniques to infer missing information of GEA with GI . Based on GEA and Q, we provide techniques to find matches of Q in GEA, as the answer of Qnl in Img. Unlike commonly used VQA methods that are based on end-to-end neural networks, our graph-based method shows well-designed reasoning capability, and thus is highly interpretable. We also create a dataset on soccer match (Soccer-VQA) with rich annotations. The experimental results show that our approach outperforms the state-of-the-art method and has high potential for future investigation.