 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMGA-VQA: Multi-Granularity Alignment for Visual Question Answering
Paper and Code
Jan 25, 2022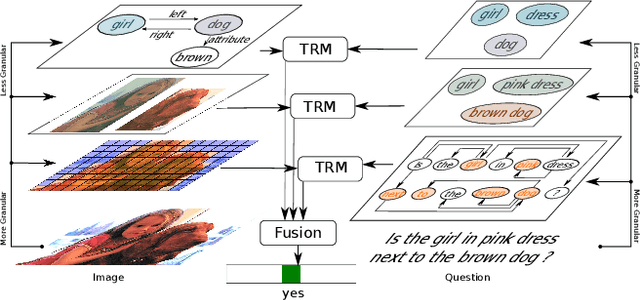



Learning to answer visual questions is a challenging task since the multi-modal inputs are within two feature spaces. Moreover, reasoning in visual question answering requires the model to understand both image and question, and align them in the same space, rather than simply memorize statistics about the question-answer pairs. Thus, it is essential to find component connections between different modalities and within each modality to achieve better attention. Previous works learned attention weights directly on the features. However, the improvement is limited since these two modality features are in two domains: image features are highly diverse, lacking structure and grammatical rules as language, and natural language features have a higher probability of missing detailed information. To better learn the attention between visual and text, we focus on how to construct input stratification and embed structural information to improve the alignment between different level components. We propose Multi-Granularity Alignment architecture for Visual Question Answering task (MGA-VQA), which learns intra- and inter-modality correlations by multi-granularity alignment, and outputs the final result by the decision fusion module. In contrast to previous works, our model splits alignment into different levels to achieve learning better correlations without needing additional data and annotations. The experiments on the VQA-v2 and GQA datasets demonstrate that our model significantly outperforms non-pretrained state-of-the-art methods on both datasets without extra pretraining data and annotations. Moreover, it even achieves better results over the pre-trained methods on GQA.