 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVisual Query Answering by Entity-Attribute Graph Matching and Reasoning
Paper and Code
Mar 16, 2019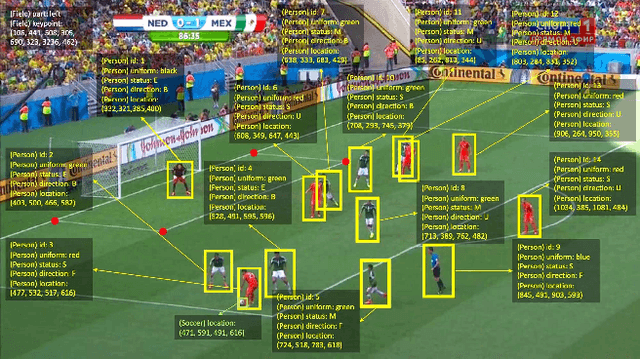
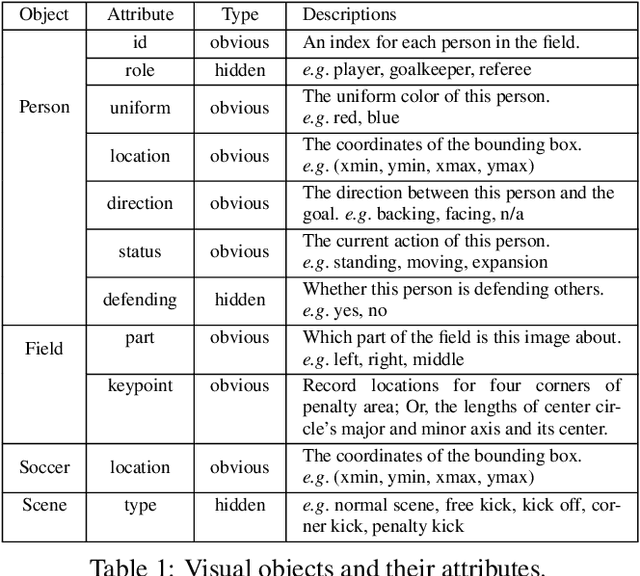

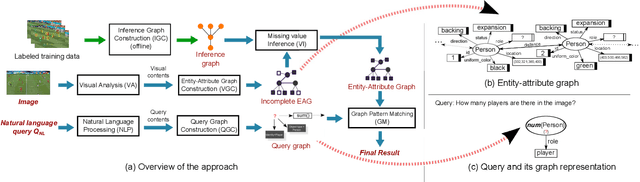
Visual Query Answering (VQA) is of great significance in offering people convenience: one can raise a question for details of objects, or high-level understanding about the scene, over an image. This paper proposes a novel method to address the VQA problem. In contrast to prior works, our method that targets single scene VQA, replies on graph-based techniques and involves reasoning. In a nutshell, our approach is centered on three graphs. The first graph, referred to as inference graph GI , is constructed via learning over labeled data. The other two graphs, referred to as query graph Q and entity-attribute graph GEA, are generated from natural language query Qnl and image Img, that are issued from users, respectively. As GEA often does not take sufficient information to answer Q, we develop techniques to infer missing information of GEA with GI . Based on GEA and Q, we provide techniques to find matches of Q in GEA, as the answer of Qnl in Img. Unlike commonly used VQA methods that are based on end-to-end neural networks, our graph-based method shows well-designed reasoning capability, and thus is highly interpretable. We also create a dataset on soccer match (Soccer-VQA) with rich annotations. The experimental results show that our approach outperforms the state-of-the-art method and has high potential for future investigation.