 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom SFT to RL: Demystifying the Post-Training Pipeline for LLM-based Vulnerability Detection
Feb 15, 2026The integration of LLMs into vulnerability detection (VD) has shifted the field toward interpretable and context-aware analysis. While post-training methods have shown promise in general coding tasks, their systematic application to VD remains underexplored. In this paper, we present the first comprehensive investigation into the post-training pipeline for LLM-based VD, spanning from cold-start SFT to off-policy preference optimization and on-policy RL, uncovering how data curation, stage interactions, reward mechanisms, and evaluation protocols collectively dictate the efficacy of model training and assessment. Our study identifies practical guidelines and insights: (1) SFT based on rejection sampling greatly outperforms rationalization-based supervision, which can introduce hallucinations due to ground-truth leakage. (2) While increased SFT epochs constantly benefit preference optimization, excessive SFT inhibits self-exploration during RL, ultimately limiting performance gains. (3) Coarse-grained reward signals often mislead RL, whereas fine-grained root-cause judgments ensure reliable credit assignment. Specification-based rewards offer further benefits but incur significant effort in specification generation. (4) Although filtering extremely hard-to-detect vulnerability samples improves RL training efficiency, the cost of performance loss should be considered in practical applications. (5) Models trained under GRPO significantly outperform those using SFT and preference optimization (i.e., DPO and ORPO), as well as a series of zero-shot SOTA LLMs, underscoring the significant potential of on-policy RL for LLM-based VD. (6) In contrast to binary matching that tends to overestimate performance, LLM-as-a-Judge based on root-cause analysis provides a more robust evaluation protocol, although its accuracy varies across judge models with different levels of security expertise.
VULPO: Context-Aware Vulnerability Detection via On-Policy LLM Optimization
Nov 18, 2025The widespread reliance on open-source software dramatically increases the risk of vulnerability exploitation, underscoring the need for effective and scalable vulnerability detection (VD). Existing VD techniques, whether traditional machine learning-based or LLM-based approaches like prompt engineering, supervised fine-tuning, or off-policy preference optimization, remain fundamentally limited in their ability to perform context-aware analysis: They depend on fixed inputs or static preference datasets, cannot adaptively explore repository-level dependencies, and are constrained by function-level benchmarks that overlook critical vulnerability context. This paper introduces Vulnerability-Adaptive Policy Optimization (VULPO), an on-policy LLM reinforcement learning framework for context-aware VD. To support training and evaluation, we first construct ContextVul, a new dataset that augments high-quality function-level samples with lightweight method to extract repository-level context information. We then design multi-dimensional reward structuring that jointly captures prediction correctness, vulnerability localization accuracy, and the semantic relevance of vulnerability analysis, thereby guiding the model toward comprehensive contextual reasoning. To address the asymmetric difficulty of different vulnerability cases and mitigate reward hacking, VULPO incorporates label-level and sample-level difficulty-adaptive reward scaling, encouraging the model to explore challenging cases while maintaining balanced reward distribution. Extensive experiments demonstrate the superiority of our VULPO framework in context-aware VD: Our VULPO-4B substantially outperforms existing VD baselines based on prompt engineering and off-policy optimization, improving F1 by 85% over Qwen3-4B and achieving performance comparable to a 150x larger-scale model, DeepSeek-R1-0528.
Revisiting Pre-trained Language Models for Vulnerability Detection
Jul 22, 2025The rapid advancement of pre-trained language models (PLMs) has demonstrated promising results for various code-related tasks. However, their effectiveness in detecting real-world vulnerabilities remains a critical challenge. % for the security community. While existing empirical studies evaluate PLMs for vulnerability detection (VD), their inadequate consideration in data preparation, evaluation setups, and experimental settings undermines the accuracy and comprehensiveness of evaluations. This paper introduces RevisitVD, an extensive evaluation of 17 PLMs spanning smaller code-specific PLMs and large-scale PLMs using newly constructed datasets. Specifically, we compare the performance of PLMs under both fine-tuning and prompt engineering, assess their effectiveness and generalizability across various training and testing settings, and analyze their robustness against code normalization, abstraction, and semantic-preserving transformations. Our findings reveal that, for VD tasks, PLMs incorporating pre-training tasks designed to capture the syntactic and semantic patterns of code outperform both general-purpose PLMs and those solely pre-trained or fine-tuned on large code corpora. However, these models face notable challenges in real-world scenarios, such as difficulties in detecting vulnerabilities with complex dependencies, handling perturbations introduced by code normalization and abstraction, and identifying semantic-preserving vulnerable code transformations. Also, the truncation caused by the limited context windows of PLMs can lead to a non-negligible amount of labeling errors. This study underscores the importance of thorough evaluations of model performance in practical scenarios and outlines future directions to help enhance the effectiveness of PLMs for realistic VD applications.
Multi-Agent Geospatial Copilots for Remote Sensing Workflows
Jan 27, 2025



We present GeoLLM-Squad, a geospatial Copilot that introduces the novel multi-agent paradigm to remote sensing (RS) workflows. Unlike existing single-agent approaches that rely on monolithic large language models (LLM), GeoLLM-Squad separates agentic orchestration from geospatial task-solving, by delegating RS tasks to specialized sub-agents. Built on the open-source AutoGen and GeoLLM-Engine frameworks, our work enables the modular integration of diverse applications, spanning urban monitoring, forestry protection, climate analysis, and agriculture studies. Our results demonstrate that while single-agent systems struggle to scale with increasing RS task complexity, GeoLLM-Squad maintains robust performance, achieving a 17% improvement in agentic correctness over state-of-the-art baselines. Our findings highlight the potential of multi-agent AI in advancing RS workflows.
FedCAP: Robust Federated Learning via Customized Aggregation and Personalization
Oct 16, 2024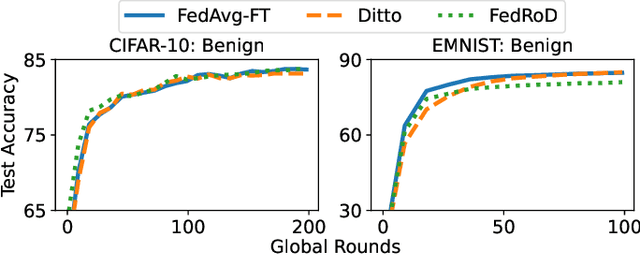
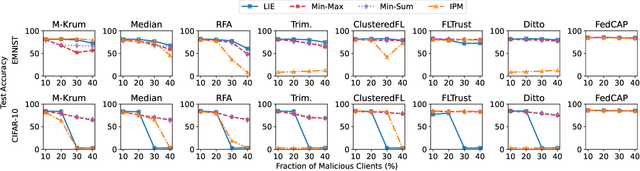
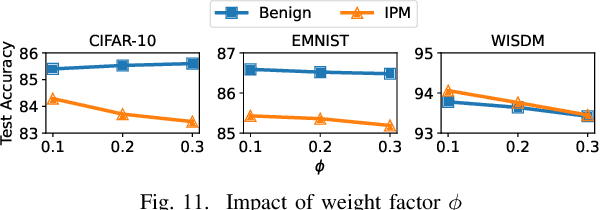
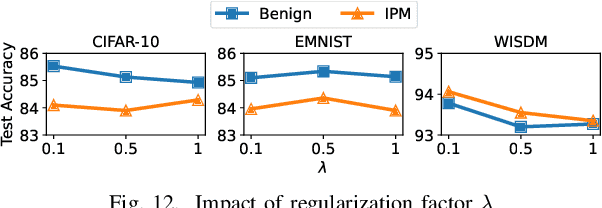
Federated learning (FL), an emerging distributed machine learning paradigm, has been applied to various privacy-preserving scenarios. However, due to its distributed nature, FL faces two key issues: the non-independent and identical distribution (non-IID) of user data and vulnerability to Byzantine threats. To address these challenges, in this paper, we propose FedCAP, a robust FL framework against both data heterogeneity and Byzantine attacks. The core of FedCAP is a model update calibration mechanism to help a server capture the differences in the direction and magnitude of model updates among clients. Furthermore, we design a customized model aggregation rule that facilitates collaborative training among similar clients while accelerating the model deterioration of malicious clients. With a Euclidean norm-based anomaly detection mechanism, the server can quickly identify and permanently remove malicious clients. Moreover, the impact of data heterogeneity and Byzantine attacks can be further mitigated through personalization on the client side. We conduct extensive experiments, comparing multiple state-of-the-art baselines, to demonstrate that FedCAP performs well in several non-IID settings and shows strong robustness under a series of poisoning attacks.
Online Learning via Memory: Retrieval-Augmented Detector Adaptation
Sep 16, 2024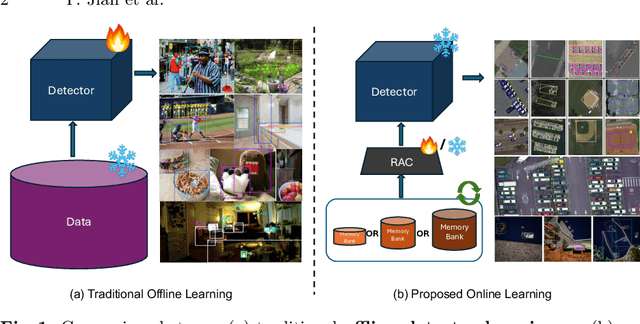
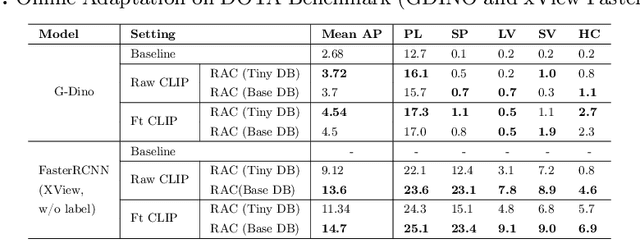
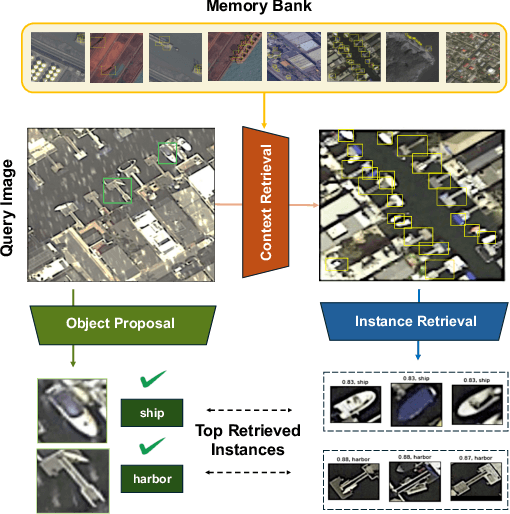
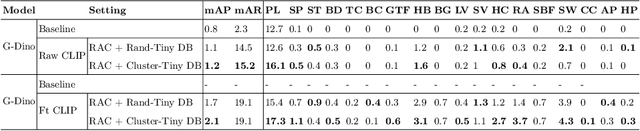
This paper presents a novel way of online adapting any off-the-shelf object detection model to a novel domain without retraining the detector model. Inspired by how humans quickly learn knowledge of a new subject (e.g., memorization), we allow the detector to look up similar object concepts from memory during test time. This is achieved through a retrieval augmented classification (RAC) module together with a memory bank that can be flexibly updated with new domain knowledge. We experimented with various off-the-shelf open-set detector and close-set detectors. With only a tiny memory bank (e.g., 10 images per category) and being training-free, our online learning method could significantly outperform baselines in adapting a detector to novel domains.
LLM-dCache: Improving Tool-Augmented LLMs with GPT-Driven Localized Data Caching
Jun 10, 2024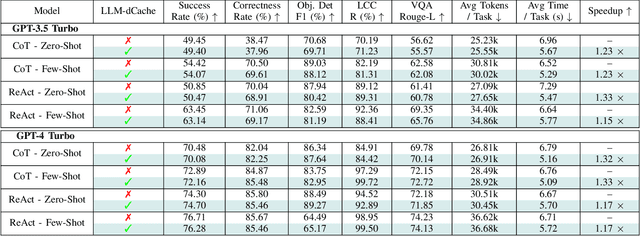


As Large Language Models (LLMs) broaden their capabilities to manage thousands of API calls, they are confronted with complex data operations across vast datasets with significant overhead to the underlying system. In this work, we introduce LLM-dCache to optimize data accesses by treating cache operations as callable API functions exposed to the tool-augmented agent. We grant LLMs the autonomy to manage cache decisions via prompting, seamlessly integrating with existing function-calling mechanisms. Tested on an industry-scale massively parallel platform that spans hundreds of GPT endpoints and terabytes of imagery, our method improves Copilot times by an average of 1.24x across various LLMs and prompting techniques.
Infinite-Dimensional Feature Interaction
May 22, 2024



The past neural network design has largely focused on feature representation space dimension and its capacity scaling (e.g., width, depth), but overlooked the feature interaction space scaling. Recent advancements have shown shifted focus towards element-wise multiplication to facilitate higher-dimensional feature interaction space for better information transformation. Despite this progress, multiplications predominantly capture low-order interactions, thus remaining confined to a finite-dimensional interaction space. To transcend this limitation, classic kernel methods emerge as a promising solution to engage features in an infinite-dimensional space. We introduce InfiNet, a model architecture that enables feature interaction within an infinite-dimensional space created by RBF kernel. Our experiments reveal that InfiNet achieves new state-of-the-art, owing to its capability to leverage infinite-dimensional interactions, significantly enhancing model performance.
QuadraNet V2: Efficient and Sustainable Training of High-Order Neural Networks with Quadratic Adaptation
May 06, 2024

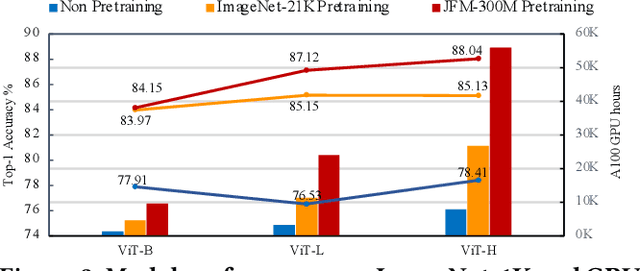

Machine learning is evolving towards high-order models that necessitate pre-training on extensive datasets, a process associated with significant overheads. Traditional models, despite having pre-trained weights, are becoming obsolete due to architectural differences that obstruct the effective transfer and initialization of these weights. To address these challenges, we introduce a novel framework, QuadraNet V2, which leverages quadratic neural networks to create efficient and sustainable high-order learning models. Our method initializes the primary term of the quadratic neuron using a standard neural network, while the quadratic term is employed to adaptively enhance the learning of data non-linearity or shifts. This integration of pre-trained primary terms with quadratic terms, which possess advanced modeling capabilities, significantly augments the information characterization capacity of the high-order network. By utilizing existing pre-trained weights, QuadraNet V2 reduces the required GPU hours for training by 90\% to 98.4\% compared to training from scratch, demonstrating both efficiency and effectiveness.
Out-of-Distribution Detection via Deep Multi-Comprehension Ensemble
Mar 24, 2024



Recent research underscores the pivotal role of the Out-of-Distribution (OOD) feature representation field scale in determining the efficacy of models in OOD detection. Consequently, the adoption of model ensembles has emerged as a prominent strategy to augment this feature representation field, capitalizing on anticipated model diversity. However, our introduction of novel qualitative and quantitative model ensemble evaluation methods, specifically Loss Basin/Barrier Visualization and the Self-Coupling Index, reveals a critical drawback in existing ensemble methods. We find that these methods incorporate weights that are affine-transformable, exhibiting limited variability and thus failing to achieve the desired diversity in feature representation. To address this limitation, we elevate the dimensions of traditional model ensembles, incorporating various factors such as different weight initializations, data holdout, etc., into distinct supervision tasks. This innovative approach, termed Multi-Comprehension (MC) Ensemble, leverages diverse training tasks to generate distinct comprehensions of the data and labels, thereby extending the feature representation field. Our experimental results demonstrate the superior performance of the MC Ensemble strategy in OOD detection compared to both the naive Deep Ensemble method and a standalone model of comparable size. This underscores the effectiveness of our proposed approach in enhancing the model's capability to detect instances outside its training distribution.