 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChain-of-Adaptation: Surgical Vision-Language Adaptation with Reinforcement Learning
Mar 20, 2026Conventional fine-tuning on domain-specific datasets can inadvertently alter a model's pretrained multimodal priors, leading to reduced generalization. To address this, we propose Chain-of-Adaptation (CoA), an adaptation framework designed to integrate domain knowledge while maintaining the model's inherent reasoning and perceptual capabilities. CoA introduces a structured reasoning format that enhances domain alignment without sacrificing general multimodal competence by reinforcement learning. Experiments on standard surgical benchmarks, under both in-distribution and out-of-distribution settings, demonstrate that CoA achieves higher accuracy, stronger generalization, and more stable behavior than supervised fine-tuning. Furthermore, ablation studies confirm that CoA effectively preserves the model's core visual-language abilities, providing a reliable pathway for domain specialization in VLMs.
Towards Pretraining Robust ASR Foundation Model with Acoustic-Aware Data Augmentation
May 27, 2025Whisper's robust performance in automatic speech recognition (ASR) is often attributed to its massive 680k-hour training set, an impractical scale for most researchers. In this work, we examine how linguistic and acoustic diversity in training data affect the robustness of the ASR model and reveal that transcription generalization is primarily driven by acoustic variation rather than linguistic richness. We find that targeted acoustic augmentation methods could significantly improve the generalization ability of ASR models, reducing word-error rates by up to 19.24 percent on unseen datasets when training on the 960-hour Librispeech dataset. These findings highlight strategic acoustically focused data augmentation as a promising alternative to massive datasets for building robust ASR models, offering a potential solution to future foundation ASR models when massive human speech data is lacking.
FP64 is All You Need: Rethinking Failure Modes in Physics-Informed Neural Networks
May 16, 2025Physics Informed Neural Networks (PINNs) often exhibit failure modes in which the PDE residual loss converges while the solution error stays large, a phenomenon traditionally blamed on local optima separated from the true solution by steep loss barriers. We challenge this understanding by demonstrate that the real culprit is insufficient arithmetic precision: with standard FP32, the LBFGS optimizer prematurely satisfies its convergence test, freezing the network in a spurious failure phase. Simply upgrading to FP64 rescues optimization, enabling vanilla PINNs to solve PDEs without any failure modes. These results reframe PINN failure modes as precision induced stalls rather than inescapable local minima and expose a three stage training dynamic unconverged, failure, success whose boundaries shift with numerical precision. Our findings emphasize that rigorous arithmetic precision is the key to dependable PDE solving with neural networks.
Combating Partial Perception Deficit in Autonomous Driving with Multimodal LLM Commonsense
Mar 10, 2025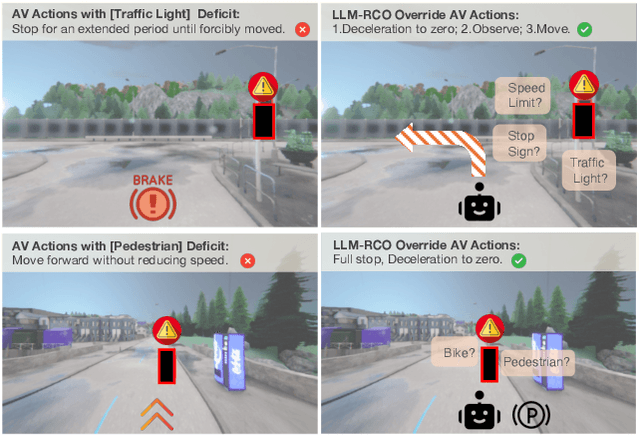
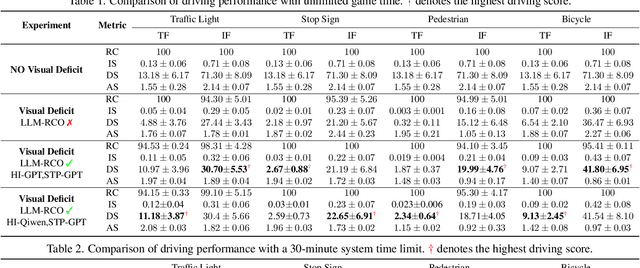
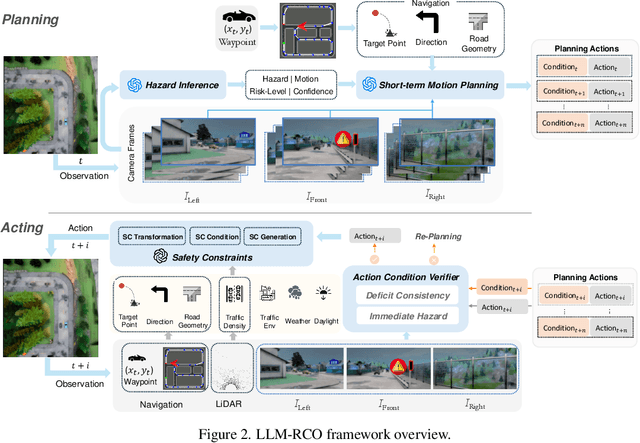

Partial perception deficits can compromise autonomous vehicle safety by disrupting environmental understanding. Current protocols typically respond with immediate stops or minimal-risk maneuvers, worsening traffic flow and lacking flexibility for rare driving scenarios. In this paper, we propose LLM-RCO, a framework leveraging large language models to integrate human-like driving commonsense into autonomous systems facing perception deficits. LLM-RCO features four key modules: hazard inference, short-term motion planner, action condition verifier, and safety constraint generator. These modules interact with the dynamic driving environment, enabling proactive and context-aware control actions to override the original control policy of autonomous agents. To improve safety in such challenging conditions, we construct DriveLM-Deficit, a dataset of 53,895 video clips featuring deficits of safety-critical objects, complete with annotations for LLM-based hazard inference and motion planning fine-tuning. Extensive experiments in adverse driving conditions with the CARLA simulator demonstrate that systems equipped with LLM-RCO significantly improve driving performance, highlighting its potential for enhancing autonomous driving resilience against adverse perception deficits. Our results also show that LLMs fine-tuned with DriveLM-Deficit can enable more proactive movements instead of conservative stops in the context of perception deficits.
Towards Understanding Multi-Round Large Language Model Reasoning: Approximability, Learnability and Generalizability
Mar 05, 2025Recent advancements in cognitive science and multi-round reasoning techniques for Large Language Models (LLMs) suggest that iterative thinking processes improve problem-solving performance in complex tasks. Inspired by this, approaches like Chain-of-Thought, debating, and self-refinement have been applied to auto-regressive LLMs, achieving significant successes in tasks such as mathematical reasoning, commonsense reasoning, and multi-hop question answering. Despite these successes, the theoretical basis for how multi-round reasoning enhances problem-solving abilities remains underexplored. In this work, we investigate the approximation, learnability, and generalization properties of multi-round auto-regressive models. We show that Transformers with finite context windows are universal approximators for steps of Turing-computable functions and can approximate any Turing-computable sequence-to-sequence function through multi-round reasoning. We extend PAC learning to sequence generation and demonstrate that multi-round generation is learnable even when the sequence length exceeds the model's context window. Finally, we examine how generalization error propagates across rounds, and show how the aforementioned approaches can help constrain this error, ensuring outputs stay within an expectation boundary. This work sheds light on the systemic theoretical foundations of multi-round sequence learning and reasoning, emphasizing its role in inference complexity.
Recognize Any Surgical Object: Unleashing the Power of Weakly-Supervised Data
Jan 25, 2025



We present RASO, a foundation model designed to Recognize Any Surgical Object, offering robust open-set recognition capabilities across a broad range of surgical procedures and object classes, in both surgical images and videos. RASO leverages a novel weakly-supervised learning framework that generates tag-image-text pairs automatically from large-scale unannotated surgical lecture videos, significantly reducing the need for manual annotations. Our scalable data generation pipeline gatherers to 2,200 surgical procedures and produces 3.6 million tag annotations across 2,066 unique surgical tags. Our experiments show that RASO achieves improvements of 2.9 mAP, 4.5 mAP, 10.6 mAP, and 7.2 mAP on four standard surgical benchmarks respectively in zero-shot settings, and surpasses state-of-the-art models in supervised surgical action recognition tasks. We will open-source our code, model, and dataset to facilitate further research.
Tiny-Align: Bridging Automatic Speech Recognition and Large Language Model on the Edge
Nov 21, 2024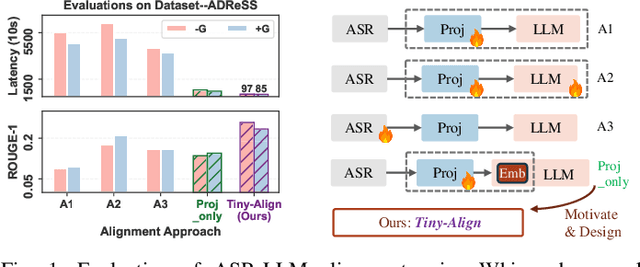
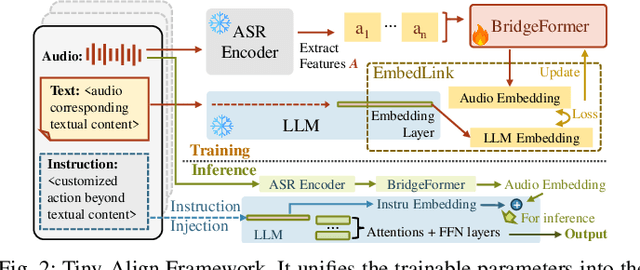
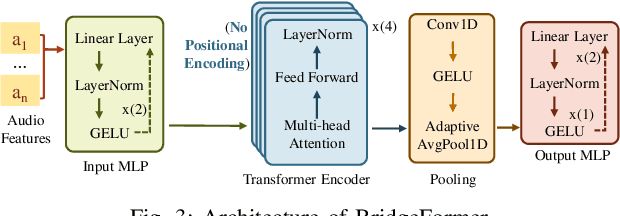
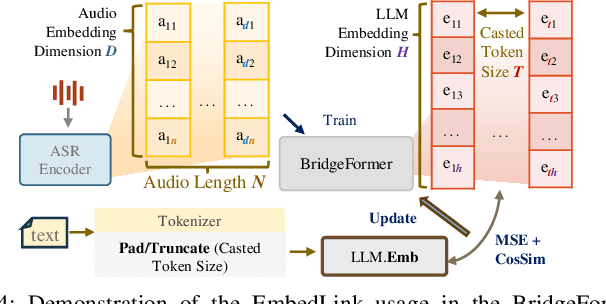
The combination of Large Language Models (LLM) and Automatic Speech Recognition (ASR), when deployed on edge devices (called edge ASR-LLM), can serve as a powerful personalized assistant to enable audio-based interaction for users. Compared to text-based interaction, edge ASR-LLM allows accessible and natural audio interactions. Unfortunately, existing ASR-LLM models are mainly trained in high-performance computing environments and produce substantial model weights, making them difficult to deploy on edge devices. More importantly, to better serve users' personalized needs, the ASR-LLM must be able to learn from each distinct user, given that audio input often contains highly personalized characteristics that necessitate personalized on-device training. Since individually fine-tuning the ASR or LLM often leads to suboptimal results due to modality-specific limitations, end-to-end training ensures seamless integration of audio features and language understanding (cross-modal alignment), ultimately enabling a more personalized and efficient adaptation on edge devices. However, due to the complex training requirements and substantial computational demands of existing approaches, cross-modal alignment between ASR audio and LLM can be challenging on edge devices. In this work, we propose a resource-efficient cross-modal alignment framework that bridges ASR and LLMs on edge devices to handle personalized audio input. Our framework enables efficient ASR-LLM alignment on resource-constrained devices like NVIDIA Jetson Orin (8GB RAM), achieving 50x training time speedup while improving the alignment quality by more than 50\%. To the best of our knowledge, this is the first work to study efficient ASR-LLM alignment on resource-constrained edge devices.
Large Language Models have Intrinsic Self-Correction Ability
Jun 21, 2024
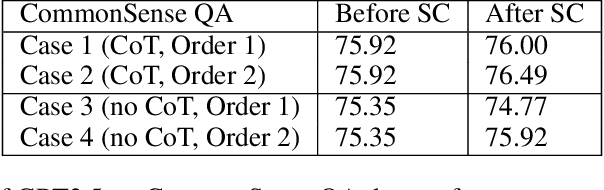
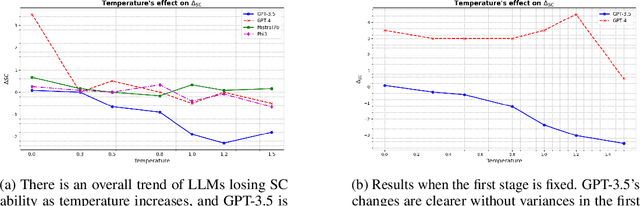
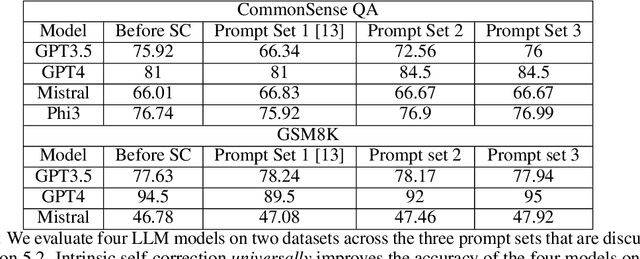
Large language models (LLMs) have attracted significant attention for their remarkable abilities in various natural language processing tasks, but they suffer from hallucinations that will cause performance degradation. One promising solution to improve the LLMs' performance is to ask LLMs to revise their answer after generation, a technique known as self-correction. Among the two types of self-correction, intrinsic self-correction is considered a promising direction because it does not utilize external knowledge. However, recent works doubt the validity of LLM's ability to conduct intrinsic self-correction. In this paper, we present a novel perspective on the intrinsic self-correction capabilities of LLMs through theoretical analyses and empirical experiments. In addition, we identify two critical factors for successful self-correction: zero temperature and fair prompts. Leveraging these factors, we demonstrate that intrinsic self-correction ability is exhibited across multiple existing LLMs. Our findings offer insights into the fundamental theories underlying the self-correction behavior of LLMs and remark on the importance of unbiased prompts and zero temperature settings in harnessing their full potential.
PI-Whisper: An Adaptive and Incremental ASR Framework for Diverse and Evolving Speaker Characteristics
Jun 21, 2024



As edge-based automatic speech recognition (ASR) technologies become increasingly prevalent for the development of intelligent and personalized assistants, three important challenges must be addressed for these resource-constrained ASR models, i.e., adaptivity, incrementality, and inclusivity. We propose a novel ASR framework, PI-Whisper, in this work and show how it can improve an ASR's recognition capabilities adaptively by identifying different speakers' characteristics in real-time, how such an adaption can be performed incrementally without repetitive retraining, and how it can improve the equity and fairness for diverse speaker groups. More impressively, our proposed PI-Whisper framework attains all of these nice properties while still achieving state-of-the-art accuracy with up to 13.7% reduction of the word error rate (WER) with linear scalability with respect to computing resources.
Infinite-Dimensional Feature Interaction
May 22, 2024



The past neural network design has largely focused on feature representation space dimension and its capacity scaling (e.g., width, depth), but overlooked the feature interaction space scaling. Recent advancements have shown shifted focus towards element-wise multiplication to facilitate higher-dimensional feature interaction space for better information transformation. Despite this progress, multiplications predominantly capture low-order interactions, thus remaining confined to a finite-dimensional interaction space. To transcend this limitation, classic kernel methods emerge as a promising solution to engage features in an infinite-dimensional space. We introduce InfiNet, a model architecture that enables feature interaction within an infinite-dimensional space created by RBF kernel. Our experiments reveal that InfiNet achieves new state-of-the-art, owing to its capability to leverage infinite-dimensional interactions, significantly enhancing model performance.