 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Agent Geospatial Copilots for Remote Sensing Workflows
Jan 27, 2025



We present GeoLLM-Squad, a geospatial Copilot that introduces the novel multi-agent paradigm to remote sensing (RS) workflows. Unlike existing single-agent approaches that rely on monolithic large language models (LLM), GeoLLM-Squad separates agentic orchestration from geospatial task-solving, by delegating RS tasks to specialized sub-agents. Built on the open-source AutoGen and GeoLLM-Engine frameworks, our work enables the modular integration of diverse applications, spanning urban monitoring, forestry protection, climate analysis, and agriculture studies. Our results demonstrate that while single-agent systems struggle to scale with increasing RS task complexity, GeoLLM-Squad maintains robust performance, achieving a 17% improvement in agentic correctness over state-of-the-art baselines. Our findings highlight the potential of multi-agent AI in advancing RS workflows.
LLM-dCache: Improving Tool-Augmented LLMs with GPT-Driven Localized Data Caching
Jun 10, 2024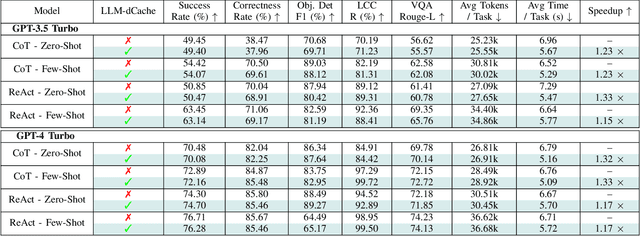


As Large Language Models (LLMs) broaden their capabilities to manage thousands of API calls, they are confronted with complex data operations across vast datasets with significant overhead to the underlying system. In this work, we introduce LLM-dCache to optimize data accesses by treating cache operations as callable API functions exposed to the tool-augmented agent. We grant LLMs the autonomy to manage cache decisions via prompting, seamlessly integrating with existing function-calling mechanisms. Tested on an industry-scale massively parallel platform that spans hundreds of GPT endpoints and terabytes of imagery, our method improves Copilot times by an average of 1.24x across various LLMs and prompting techniques.
Unlearning Climate Misinformation in Large Language Models
May 29, 2024Misinformation regarding climate change is a key roadblock in addressing one of the most serious threats to humanity. This paper investigates factual accuracy in large language models (LLMs) regarding climate information. Using true/false labeled Q&A data for fine-tuning and evaluating LLMs on climate-related claims, we compare open-source models, assessing their ability to generate truthful responses to climate change questions. We investigate the detectability of models intentionally poisoned with false climate information, finding that such poisoning may not affect the accuracy of a model's responses in other domains. Furthermore, we compare the effectiveness of unlearning algorithms, fine-tuning, and Retrieval-Augmented Generation (RAG) for factually grounding LLMs on climate change topics. Our evaluation reveals that unlearning algorithms can be effective for nuanced conceptual claims, despite previous findings suggesting their inefficacy in privacy contexts. These insights aim to guide the development of more factually reliable LLMs and highlight the need for additional work to secure LLMs against misinformation attacks.
GeckOpt: LLM System Efficiency via Intent-Based Tool Selection
Apr 24, 2024

In this preliminary study, we investigate a GPT-driven intent-based reasoning approach to streamline tool selection for large language models (LLMs) aimed at system efficiency. By identifying the intent behind user prompts at runtime, we narrow down the API toolset required for task execution, reducing token consumption by up to 24.6\%. Early results on a real-world, massively parallel Copilot platform with over 100 GPT-4-Turbo nodes show cost reductions and potential towards improving LLM-based system efficiency.
GeoLLM-Engine: A Realistic Environment for Building Geospatial Copilots
Apr 23, 2024



Geospatial Copilots unlock unprecedented potential for performing Earth Observation (EO) applications through natural language instructions. However, existing agents rely on overly simplified single tasks and template-based prompts, creating a disconnect with real-world scenarios. In this work, we present GeoLLM-Engine, an environment for tool-augmented agents with intricate tasks routinely executed by analysts on remote sensing platforms. We enrich our environment with geospatial API tools, dynamic maps/UIs, and external multimodal knowledge bases to properly gauge an agent's proficiency in interpreting realistic high-level natural language commands and its functional correctness in task completions. By alleviating overheads typically associated with human-in-the-loop benchmark curation, we harness our massively parallel engine across 100 GPT-4-Turbo nodes, scaling to over half a million diverse multi-tool tasks and across 1.1 million satellite images. By moving beyond traditional single-task image-caption paradigms, we investigate state-of-the-art agents and prompting techniques against long-horizon prompts.
Evaluating Tool-Augmented Agents in Remote Sensing Platforms
Apr 23, 2024



Tool-augmented Large Language Models (LLMs) have shown impressive capabilities in remote sensing (RS) applications. However, existing benchmarks assume question-answering input templates over predefined image-text data pairs. These standalone instructions neglect the intricacies of realistic user-grounded tasks. Consider a geospatial analyst: they zoom in a map area, they draw a region over which to collect satellite imagery, and they succinctly ask "Detect all objects here". Where is `here`, if it is not explicitly hardcoded in the image-text template, but instead is implied by the system state, e.g., the live map positioning? To bridge this gap, we present GeoLLM-QA, a benchmark designed to capture long sequences of verbal, visual, and click-based actions on a real UI platform. Through in-depth evaluation of state-of-the-art LLMs over a diverse set of 1,000 tasks, we offer insights towards stronger agents for RS applications.