 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeART: Anonymous Region Transformer for Variable Multi-Layer Transparent Image Generation
Feb 25, 2025Multi-layer image generation is a fundamental task that enables users to isolate, select, and edit specific image layers, thereby revolutionizing interactions with generative models. In this paper, we introduce the Anonymous Region Transformer (ART), which facilitates the direct generation of variable multi-layer transparent images based on a global text prompt and an anonymous region layout. Inspired by Schema theory suggests that knowledge is organized in frameworks (schemas) that enable people to interpret and learn from new information by linking it to prior knowledge.}, this anonymous region layout allows the generative model to autonomously determine which set of visual tokens should align with which text tokens, which is in contrast to the previously dominant semantic layout for the image generation task. In addition, the layer-wise region crop mechanism, which only selects the visual tokens belonging to each anonymous region, significantly reduces attention computation costs and enables the efficient generation of images with numerous distinct layers (e.g., 50+). When compared to the full attention approach, our method is over 12 times faster and exhibits fewer layer conflicts. Furthermore, we propose a high-quality multi-layer transparent image autoencoder that supports the direct encoding and decoding of the transparency of variable multi-layer images in a joint manner. By enabling precise control and scalable layer generation, ART establishes a new paradigm for interactive content creation.
MM-VID: Advancing Video Understanding with GPT-4V
Oct 30, 2023



We present MM-VID, an integrated system that harnesses the capabilities of GPT-4V, combined with specialized tools in vision, audio, and speech, to facilitate advanced video understanding. MM-VID is designed to address the challenges posed by long-form videos and intricate tasks such as reasoning within hour-long content and grasping storylines spanning multiple episodes. MM-VID uses a video-to-script generation with GPT-4V to transcribe multimodal elements into a long textual script. The generated script details character movements, actions, expressions, and dialogues, paving the way for large language models (LLMs) to achieve video understanding. This enables advanced capabilities, including audio description, character identification, and multimodal high-level comprehension. Experimental results demonstrate the effectiveness of MM-VID in handling distinct video genres with various video lengths. Additionally, we showcase its potential when applied to interactive environments, such as video games and graphic user interfaces.
Neural Voting Field for Camera-Space 3D Hand Pose Estimation
May 07, 2023
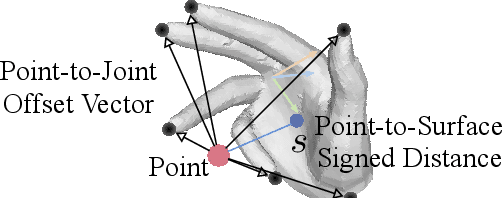
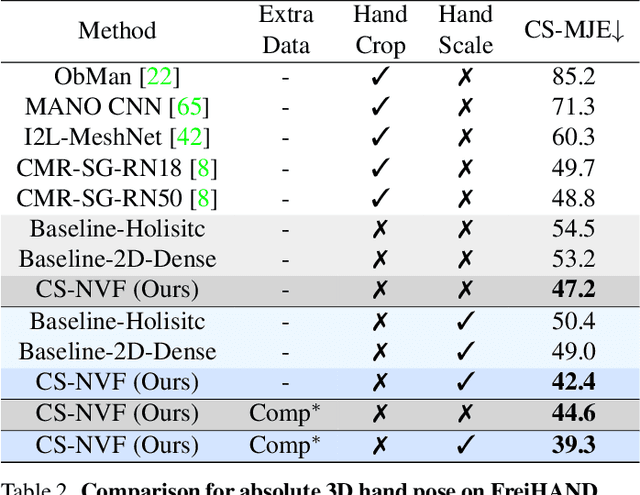
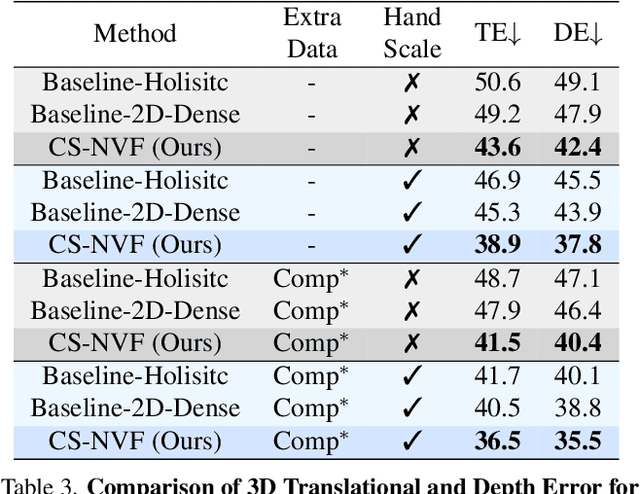
We present a unified framework for camera-space 3D hand pose estimation from a single RGB image based on 3D implicit representation. As opposed to recent works, most of which first adopt holistic or pixel-level dense regression to obtain relative 3D hand pose and then follow with complex second-stage operations for 3D global root or scale recovery, we propose a novel unified 3D dense regression scheme to estimate camera-space 3D hand pose via dense 3D point-wise voting in camera frustum. Through direct dense modeling in 3D domain inspired by Pixel-aligned Implicit Functions for 3D detailed reconstruction, our proposed Neural Voting Field (NVF) fully models 3D dense local evidence and hand global geometry, helping to alleviate common 2D-to-3D ambiguities. Specifically, for a 3D query point in camera frustum and its pixel-aligned image feature, NVF, represented by a Multi-Layer Perceptron, regresses: (i) its signed distance to the hand surface; (ii) a set of 4D offset vectors (1D voting weight and 3D directional vector to each hand joint). Following a vote-casting scheme, 4D offset vectors from near-surface points are selected to calculate the 3D hand joint coordinates by a weighted average. Experiments demonstrate that NVF outperforms existing state-of-the-art algorithms on FreiHAND dataset for camera-space 3D hand pose estimation. We also adapt NVF to the classic task of root-relative 3D hand pose estimation, for which NVF also obtains state-of-the-art results on HO3D dataset.
MPT: Mesh Pre-Training with Transformers for Human Pose and Mesh Reconstruction
Nov 24, 2022We present Mesh Pre-Training (MPT), a new pre-training framework that leverages 3D mesh data such as MoCap data for human pose and mesh reconstruction from a single image. Existing work in 3D pose and mesh reconstruction typically requires image-mesh pairs as the training data, but the acquisition of 2D-to-3D annotations is difficult. In this paper, we explore how to leverage 3D mesh data such as MoCap data, that does not have RGB images, for pre-training. The key idea is that even though 3D mesh data cannot be used for end-to-end training due to a lack of the corresponding RGB images, it can be used to pre-train the mesh regression transformer subnetwork. We observe that such pre-training not only improves the accuracy of mesh reconstruction from a single image, but also enables zero-shot capability. We conduct mesh pre-training using 2 million meshes. Experimental results show that MPT advances the state-of-the-art results on Human3.6M and 3DPW datasets. We also show that MPT enables transformer models to have zero-shot capability of human mesh reconstruction from real images. In addition, we demonstrate the generalizability of MPT to 3D hand reconstruction, achieving state-of-the-art results on FreiHAND dataset.
The Overlooked Classifier in Human-Object Interaction Recognition
Mar 10, 2022
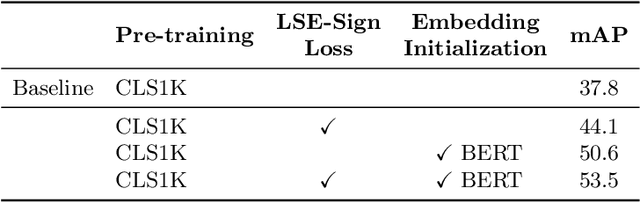

Human-Object Interaction (HOI) recognition is challenging due to two factors: (1) significant imbalance across classes and (2) requiring multiple labels per image. This paper shows that these two challenges can be effectively addressed by improving the classifier with the backbone architecture untouched. Firstly, we encode the semantic correlation among classes into the classification head by initializing the weights with language embeddings of HOIs. As a result, the performance is boosted significantly, especially for the few-shot subset. Secondly, we propose a new loss named LSE-Sign to enhance multi-label learning on a long-tailed dataset. Our simple yet effective method enables detection-free HOI classification, outperforming the state-of-the-arts that require object detection and human pose by a clear margin. Moreover, we transfer the classification model to instance-level HOI detection by connecting it with an off-the-shelf object detector. We achieve state-of-the-art without additional fine-tuning.
Decoupling Object Detection from Human-Object Interaction Recognition
Dec 13, 2021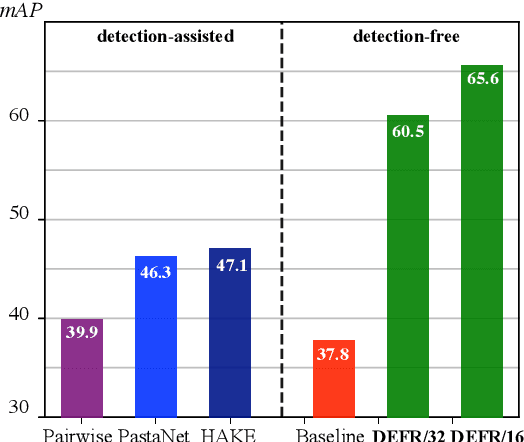

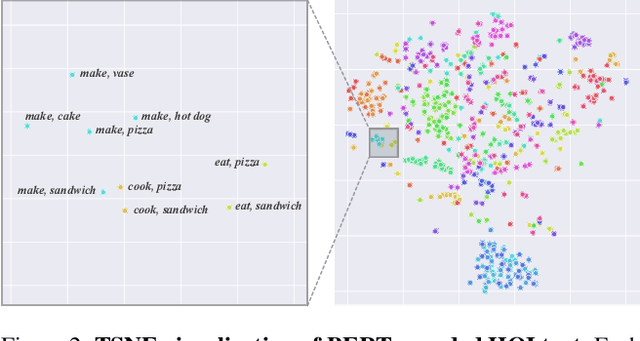
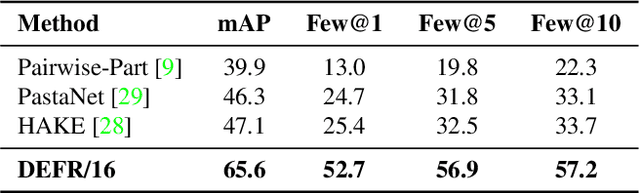
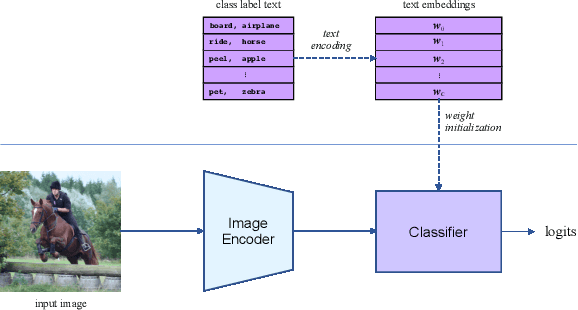
We propose DEFR, a DEtection-FRee method to recognize Human-Object Interactions (HOI) at image level without using object location or human pose. This is challenging as the detector is an integral part of existing methods. In this paper, we propose two findings to boost the performance of the detection-free approach, which significantly outperforms the detection-assisted state of the arts. Firstly, we find it crucial to effectively leverage the semantic correlations among HOI classes. Remarkable gain can be achieved by using language embeddings of HOI labels to initialize the linear classifier, which encodes the structure of HOIs to guide training. Further, we propose Log-Sum-Exp Sign (LSE-Sign) loss to facilitate multi-label learning on a long-tailed dataset by balancing gradients over all classes in a softmax format. Our detection-free approach achieves 65.6 mAP in HOI classification on HICO, outperforming the detection-assisted state of the art (SOTA) by 18.5 mAP, and 52.7 mAP in one-shot classes, surpassing the SOTA by 27.3 mAP. Different from previous work, our classification model (DEFR) can be directly used in HOI detection without any additional training, by connecting to an off-the-shelf object detector whose bounding box output is converted to binary masks for DEFR. Surprisingly, such a simple connection of two decoupled models achieves SOTA performance (32.35 mAP).
Injecting Semantic Concepts into End-to-End Image Captioning
Dec 09, 2021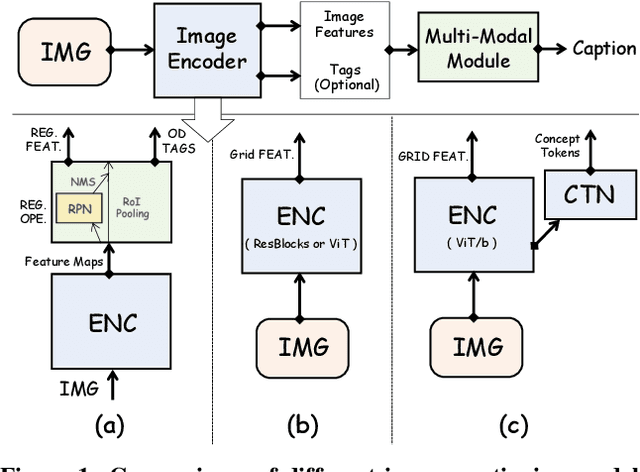
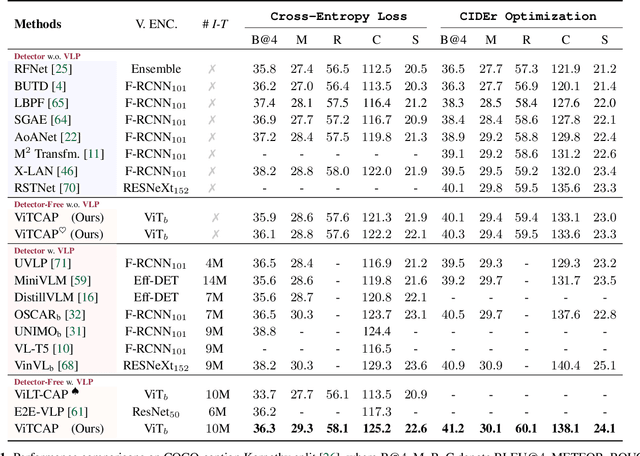
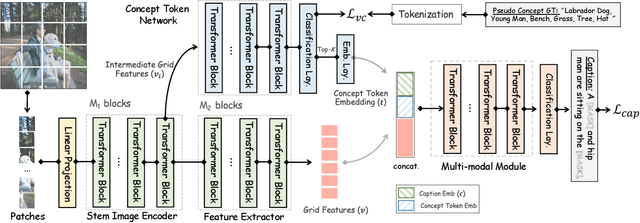
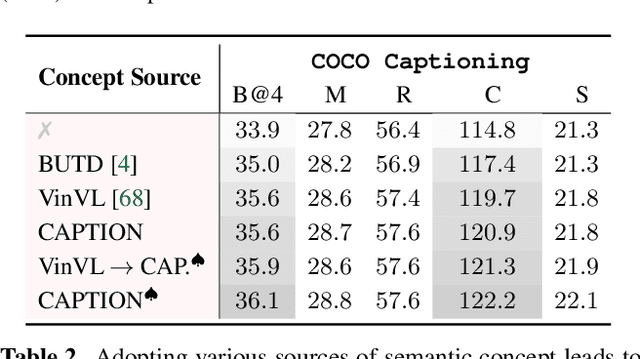
Tremendous progress has been made in recent years in developing better image captioning models, yet most of them rely on a separate object detector to extract regional features. Recent vision-language studies are shifting towards the detector-free trend by leveraging grid representations for more flexible model training and faster inference speed. However, such development is primarily focused on image understanding tasks, and remains less investigated for the caption generation task. In this paper, we are concerned with a better-performing detector-free image captioning model, and propose a pure vision transformer-based image captioning model, dubbed as ViTCAP, in which grid representations are used without extracting the regional features. For improved performance, we introduce a novel Concept Token Network (CTN) to predict the semantic concepts and then incorporate them into the end-to-end captioning. In particular, the CTN is built on the basis of a vision transformer and is designed to predict the concept tokens through a classification task, from which the rich semantic information contained greatly benefits the captioning task. Compared with the previous detector-based models, ViTCAP drastically simplifies the architectures and at the same time achieves competitive performance on various challenging image captioning datasets. In particular, ViTCAP reaches 138.1 CIDEr scores on COCO-caption Karpathy-split, 93.8 and 108.6 CIDEr scores on nocaps, and Google-CC captioning datasets, respectively.
Generating Realistic Geology Conditioned on Physical Measurements with Generative Adversarial Networks
Jul 05, 2018
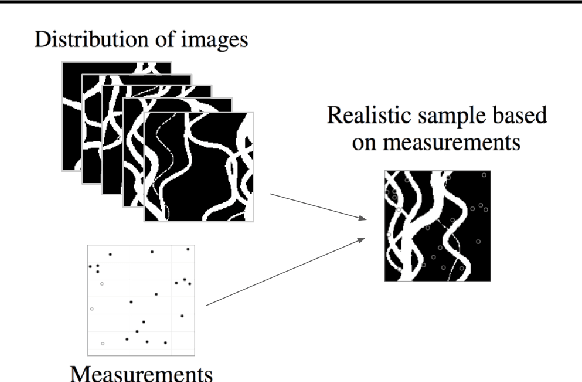
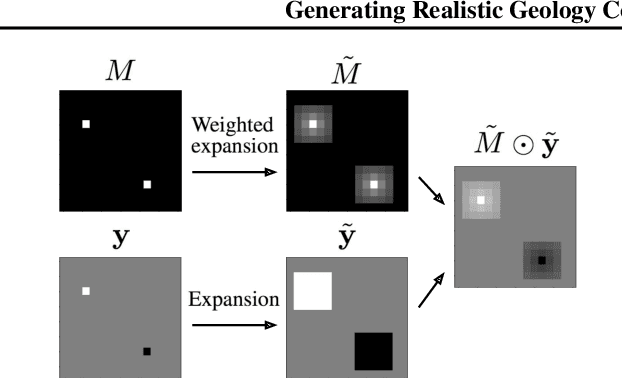

An important problem in geostatistics is to build models of the subsurface of the Earth given physical measurements at sparse spatial locations. Typically, this is done using spatial interpolation methods or by reproducing patterns from a reference image. However, these algorithms fail to produce realistic patterns and do not exhibit the wide range of uncertainty inherent in the prediction of geology. In this paper, we show how semantic inpainting with Generative Adversarial Networks can be used to generate varied realizations of geology which honor physical measurements while matching the expected geological patterns. In contrast to other algorithms, our method scales well with the number of data points and mimics a distribution of patterns as opposed to a single pattern or image. The generated conditional samples are state of the art.