 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeART: Anonymous Region Transformer for Variable Multi-Layer Transparent Image Generation
Feb 25, 2025Multi-layer image generation is a fundamental task that enables users to isolate, select, and edit specific image layers, thereby revolutionizing interactions with generative models. In this paper, we introduce the Anonymous Region Transformer (ART), which facilitates the direct generation of variable multi-layer transparent images based on a global text prompt and an anonymous region layout. Inspired by Schema theory suggests that knowledge is organized in frameworks (schemas) that enable people to interpret and learn from new information by linking it to prior knowledge.}, this anonymous region layout allows the generative model to autonomously determine which set of visual tokens should align with which text tokens, which is in contrast to the previously dominant semantic layout for the image generation task. In addition, the layer-wise region crop mechanism, which only selects the visual tokens belonging to each anonymous region, significantly reduces attention computation costs and enables the efficient generation of images with numerous distinct layers (e.g., 50+). When compared to the full attention approach, our method is over 12 times faster and exhibits fewer layer conflicts. Furthermore, we propose a high-quality multi-layer transparent image autoencoder that supports the direct encoding and decoding of the transparency of variable multi-layer images in a joint manner. By enabling precise control and scalable layer generation, ART establishes a new paradigm for interactive content creation.
FewViewGS: Gaussian Splatting with Few View Matching and Multi-stage Training
Nov 04, 2024



The field of novel view synthesis from images has seen rapid advancements with the introduction of Neural Radiance Fields (NeRF) and more recently with 3D Gaussian Splatting. Gaussian Splatting became widely adopted due to its efficiency and ability to render novel views accurately. While Gaussian Splatting performs well when a sufficient amount of training images are available, its unstructured explicit representation tends to overfit in scenarios with sparse input images, resulting in poor rendering performance. To address this, we present a 3D Gaussian-based novel view synthesis method using sparse input images that can accurately render the scene from the viewpoints not covered by the training images. We propose a multi-stage training scheme with matching-based consistency constraints imposed on the novel views without relying on pre-trained depth estimation or diffusion models. This is achieved by using the matches of the available training images to supervise the generation of the novel views sampled between the training frames with color, geometry, and semantic losses. In addition, we introduce a locality preserving regularization for 3D Gaussians which removes rendering artifacts by preserving the local color structure of the scene. Evaluation on synthetic and real-world datasets demonstrates competitive or superior performance of our method in few-shot novel view synthesis compared to existing state-of-the-art methods.
Geometry-guided Feature Learning and Fusion for Indoor Scene Reconstruction
Aug 28, 2024



In addition to color and textural information, geometry provides important cues for 3D scene reconstruction. However, current reconstruction methods only include geometry at the feature level thus not fully exploiting the geometric information. In contrast, this paper proposes a novel geometry integration mechanism for 3D scene reconstruction. Our approach incorporates 3D geometry at three levels, i.e. feature learning, feature fusion, and network supervision. First, geometry-guided feature learning encodes geometric priors to contain view-dependent information. Second, a geometry-guided adaptive feature fusion is introduced which utilizes the geometric priors as a guidance to adaptively generate weights for multiple views. Third, at the supervision level, taking the consistency between 2D and 3D normals into account, a consistent 3D normal loss is designed to add local constraints. Large-scale experiments are conducted on the ScanNet dataset, showing that volumetric methods with our geometry integration mechanism outperform state-of-the-art methods quantitatively as well as qualitatively. Volumetric methods with ours also show good generalization on the 7-Scenes and TUM RGB-D datasets.
Ray-Distance Volume Rendering for Neural Scene Reconstruction
Aug 28, 2024Existing methods in neural scene reconstruction utilize the Signed Distance Function (SDF) to model the density function. However, in indoor scenes, the density computed from the SDF for a sampled point may not consistently reflect its real importance in volume rendering, often due to the influence of neighboring objects. To tackle this issue, our work proposes a novel approach for indoor scene reconstruction, which instead parameterizes the density function with the Signed Ray Distance Function (SRDF). Firstly, the SRDF is predicted by the network and transformed to a ray-conditioned density function for volume rendering. We argue that the ray-specific SRDF only considers the surface along the camera ray, from which the derived density function is more consistent to the real occupancy than that from the SDF. Secondly, although SRDF and SDF represent different aspects of scene geometries, their values should share the same sign indicating the underlying spatial occupancy. Therefore, this work introduces a SRDF-SDF consistency loss to constrain the signs of the SRDF and SDF outputs. Thirdly, this work proposes a self-supervised visibility task, introducing the physical visibility geometry to the reconstruction task. The visibility task combines prior from predicted SRDF and SDF as pseudo labels, and contributes to generating more accurate 3D geometry. Our method implemented with different representations has been validated on indoor datasets, achieving improved performance in both reconstruction and view synthesis.
Motion-state Alignment for Video Semantic Segmentation
Apr 18, 2023



In recent years, video semantic segmentation has made great progress with advanced deep neural networks. However, there still exist two main challenges \ie, information inconsistency and computation cost. To deal with the two difficulties, we propose a novel motion-state alignment framework for video semantic segmentation to keep both motion and state consistency. In the framework, we first construct a motion alignment branch armed with an efficient decoupled transformer to capture dynamic semantics, guaranteeing region-level temporal consistency. Then, a state alignment branch composed of a stage transformer is designed to enrich feature spaces for the current frame to extract static semantics and achieve pixel-level state consistency. Next, by a semantic assignment mechanism, the region descriptor of each semantic category is gained from dynamic semantics and linked with pixel descriptors from static semantics. Benefiting from the alignment of these two kinds of effective information, the proposed method picks up dynamic and static semantics in a targeted way, so that video semantic regions are consistently segmented to obtain precise locations with low computational complexity. Extensive experiments on Cityscapes and CamVid datasets show that the proposed approach outperforms state-of-the-art methods and validates the effectiveness of the motion-state alignment framework.
Perceive, Excavate and Purify: A Novel Object Mining Framework for Instance Segmentation
Apr 18, 2023

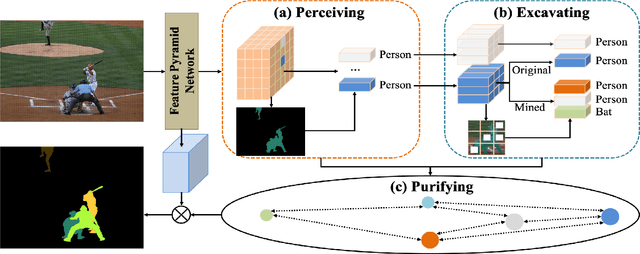
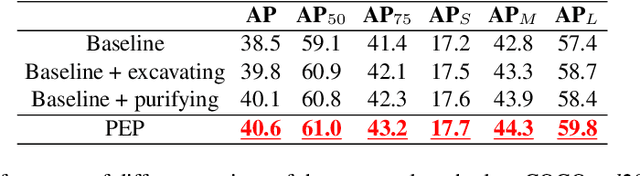
Recently, instance segmentation has made great progress with the rapid development of deep neural networks. However, there still exist two main challenges including discovering indistinguishable objects and modeling the relationship between instances. To deal with these difficulties, we propose a novel object mining framework for instance segmentation. In this framework, we first introduce the semantics perceiving subnetwork to capture pixels that may belong to an obvious instance from the bottom up. Then, we propose an object excavating mechanism to discover indistinguishable objects. In the mechanism, preliminary perceived semantics are regarded as original instances with classifications and locations, and then indistinguishable objects around these original instances are mined, which ensures that hard objects are fully excavated. Next, an instance purifying strategy is put forward to model the relationship between instances, which pulls the similar instances close and pushes away different instances to keep intra-instance similarity and inter-instance discrimination. In this manner, the same objects are combined as the one instance and different objects are distinguished as independent instances. Extensive experiments on the COCO dataset show that the proposed approach outperforms state-of-the-art methods, which validates the effectiveness of the proposed object mining framework.