 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBEM: Balanced and Entropy-based Mix for Long-Tailed Semi-Supervised Learning
Apr 01, 2024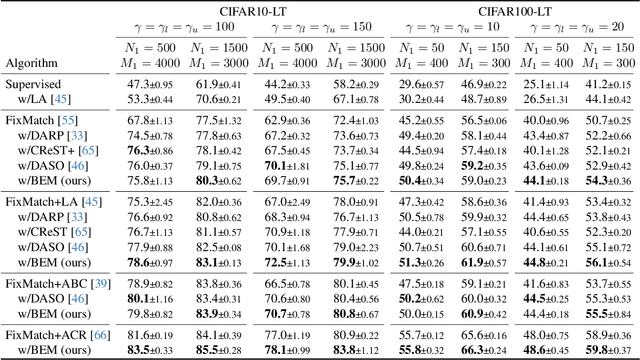
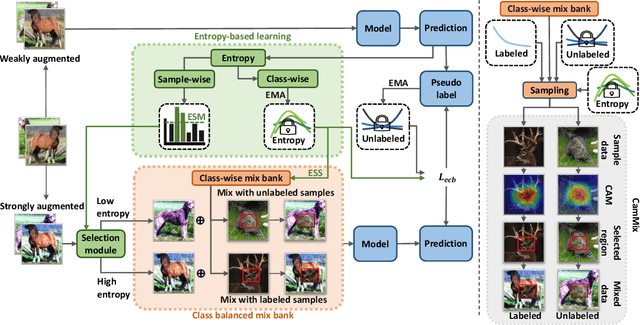
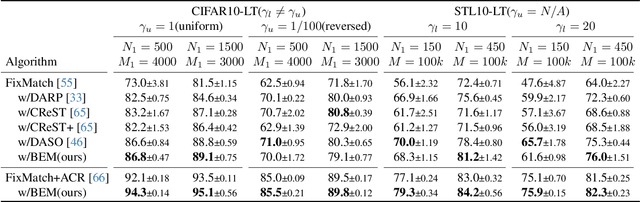

Data mixing methods play a crucial role in semi-supervised learning (SSL), but their application is unexplored in long-tailed semi-supervised learning (LTSSL). The primary reason is that the in-batch mixing manner fails to address class imbalance. Furthermore, existing LTSSL methods mainly focus on re-balancing data quantity but ignore class-wise uncertainty, which is also vital for class balance. For instance, some classes with sufficient samples might still exhibit high uncertainty due to indistinguishable features. To this end, this paper introduces the Balanced and Entropy-based Mix (BEM), a pioneering mixing approach to re-balance the class distribution of both data quantity and uncertainty. Specifically, we first propose a class balanced mix bank to store data of each class for mixing. This bank samples data based on the estimated quantity distribution, thus re-balancing data quantity. Then, we present an entropy-based learning approach to re-balance class-wise uncertainty, including entropy-based sampling strategy, entropy-based selection module, and entropy-based class balanced loss. Our BEM first leverages data mixing for improving LTSSL, and it can also serve as a complement to the existing re-balancing methods. Experimental results show that BEM significantly enhances various LTSSL frameworks and achieves state-of-the-art performances across multiple benchmarks.
Text2Street: Controllable Text-to-image Generation for Street Views
Feb 07, 2024



Text-to-image generation has made remarkable progress with the emergence of diffusion models. However, it is still a difficult task to generate images for street views based on text, mainly because the road topology of street scenes is complex, the traffic status is diverse and the weather condition is various, which makes conventional text-to-image models difficult to deal with. To address these challenges, we propose a novel controllable text-to-image framework, named \textbf{Text2Street}. In the framework, we first introduce the lane-aware road topology generator, which achieves text-to-map generation with the accurate road structure and lane lines armed with the counting adapter, realizing the controllable road topology generation. Then, the position-based object layout generator is proposed to obtain text-to-layout generation through an object-level bounding box diffusion strategy, realizing the controllable traffic object layout generation. Finally, the multiple control image generator is designed to integrate the road topology, object layout and weather description to realize controllable street-view image generation. Extensive experiments show that the proposed approach achieves controllable street-view text-to-image generation and validates the effectiveness of the Text2Street framework for street views.
3rd Place Solution for PVUW Challenge 2023: Video Panoptic Segmentation
Jun 11, 2023



In order to deal with the task of video panoptic segmentation in the wild, we propose a robust integrated video panoptic segmentation solution. In our solution, we regard the video panoptic segmentation task as a segmentation target querying task, represent both semantic and instance targets as a set of queries, and then combine these queries with video features extracted by neural networks to predict segmentation masks. In order to improve the learning accuracy and convergence speed of the solution, we add additional tasks of video semantic segmentation and video instance segmentation for joint training. In addition, we also add an additional image semantic segmentation model to further improve the performance of semantic classes. In addition, we also add some additional operations to improve the robustness of the model. Extensive experiments on the VIPSeg dataset show that the proposed solution achieves state-of-the-art performance with 50.04\% VPQ on the VIPSeg test set, which is 3rd place on the video panoptic segmentation track of the PVUW Challenge 2023.
Motion-state Alignment for Video Semantic Segmentation
Apr 18, 2023



In recent years, video semantic segmentation has made great progress with advanced deep neural networks. However, there still exist two main challenges \ie, information inconsistency and computation cost. To deal with the two difficulties, we propose a novel motion-state alignment framework for video semantic segmentation to keep both motion and state consistency. In the framework, we first construct a motion alignment branch armed with an efficient decoupled transformer to capture dynamic semantics, guaranteeing region-level temporal consistency. Then, a state alignment branch composed of a stage transformer is designed to enrich feature spaces for the current frame to extract static semantics and achieve pixel-level state consistency. Next, by a semantic assignment mechanism, the region descriptor of each semantic category is gained from dynamic semantics and linked with pixel descriptors from static semantics. Benefiting from the alignment of these two kinds of effective information, the proposed method picks up dynamic and static semantics in a targeted way, so that video semantic regions are consistently segmented to obtain precise locations with low computational complexity. Extensive experiments on Cityscapes and CamVid datasets show that the proposed approach outperforms state-of-the-art methods and validates the effectiveness of the motion-state alignment framework.
Perceive, Excavate and Purify: A Novel Object Mining Framework for Instance Segmentation
Apr 18, 2023

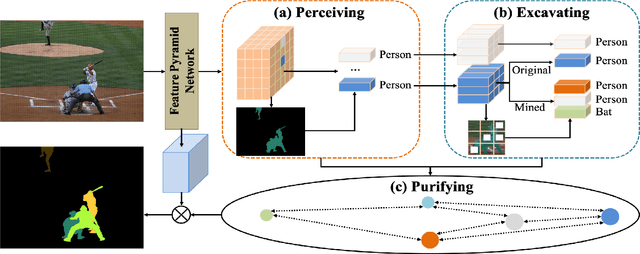
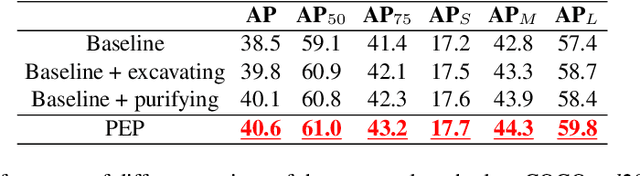
Recently, instance segmentation has made great progress with the rapid development of deep neural networks. However, there still exist two main challenges including discovering indistinguishable objects and modeling the relationship between instances. To deal with these difficulties, we propose a novel object mining framework for instance segmentation. In this framework, we first introduce the semantics perceiving subnetwork to capture pixels that may belong to an obvious instance from the bottom up. Then, we propose an object excavating mechanism to discover indistinguishable objects. In the mechanism, preliminary perceived semantics are regarded as original instances with classifications and locations, and then indistinguishable objects around these original instances are mined, which ensures that hard objects are fully excavated. Next, an instance purifying strategy is put forward to model the relationship between instances, which pulls the similar instances close and pushes away different instances to keep intra-instance similarity and inter-instance discrimination. In this manner, the same objects are combined as the one instance and different objects are distinguished as independent instances. Extensive experiments on the COCO dataset show that the proposed approach outperforms state-of-the-art methods, which validates the effectiveness of the proposed object mining framework.
5th Place Solution for YouTube-VOS Challenge 2022: Video Object Segmentation
Jun 20, 2022
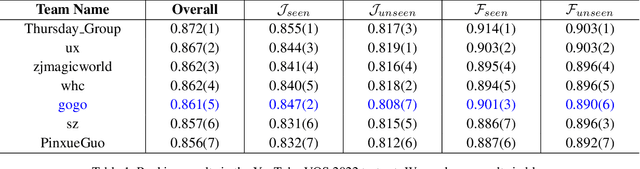
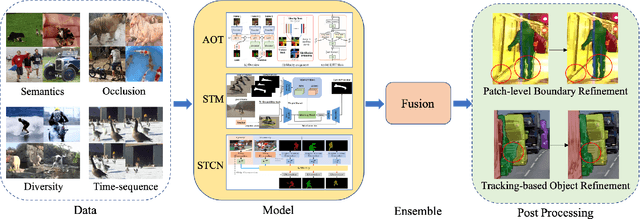

Video object segmentation (VOS) has made significant progress with the rise of deep learning. However, there still exist some thorny problems, for example, similar objects are easily confused and tiny objects are difficult to be found. To solve these problems and further improve the performance of VOS, we propose a simple yet effective solution for this task. In the solution, we first analyze the distribution of the Youtube-VOS dataset and supplement the dataset by introducing public static and video segmentation datasets. Then, we improve three network architectures with different characteristics and train several networks to learn the different characteristics of objects in videos. After that, we use a simple way to integrate all results to ensure that different models complement each other. Finally, subtle post-processing is carried out to ensure accurate video object segmentation with precise boundaries. Extensive experiments on Youtube-VOS dataset show that the proposed solution achieves the state-of-the-art performance with an 86.1% overall score on the YouTube-VOS 2022 test set, which is 5th place on the video object segmentation track of the Youtube-VOS Challenge 2022.
InsCon:Instance Consistency Feature Representation via Self-Supervised Learning
Mar 15, 2022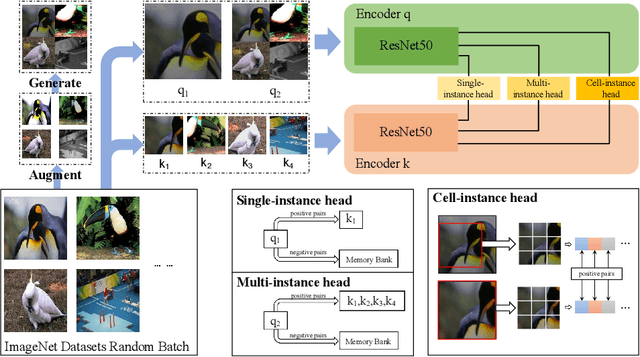
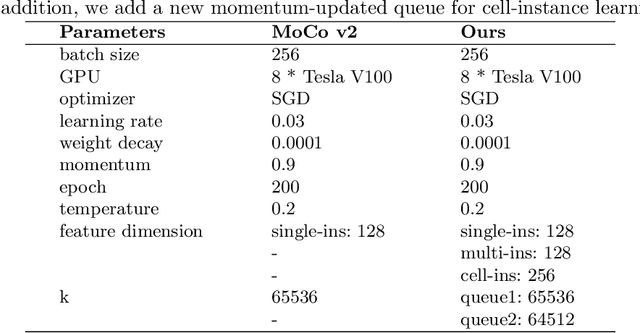
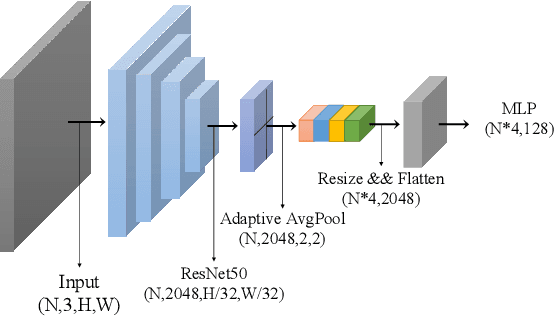
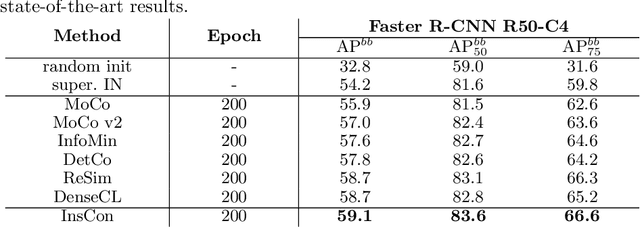
Feature representation via self-supervised learning has reached remarkable success in image-level contrastive learning, which brings impressive performances on image classification tasks. While image-level feature representation mainly focuses on contrastive learning in single instance, it ignores the objective differences between pretext and downstream prediction tasks such as object detection and instance segmentation. In order to fully unleash the power of feature representation on downstream prediction tasks, we propose a new end-to-end self-supervised framework called InsCon, which is devoted to capturing multi-instance information and extracting cell-instance features for object recognition and localization. On the one hand, InsCon builds a targeted learning paradigm that applies multi-instance images as input, aligning the learned feature between corresponding instance views, which makes it more appropriate for multi-instance recognition tasks. On the other hand, InsCon introduces the pull and push of cell-instance, which utilizes cell consistency to enhance fine-grained feature representation for precise boundary localization. As a result, InsCon learns multi-instance consistency on semantic feature representation and cell-instance consistency on spatial feature representation. Experiments demonstrate the method we proposed surpasses MoCo v2 by 1.1% AP^{bb} on COCO object detection and 1.0% AP^{mk} on COCO instance segmentation using Mask R-CNN R50-FPN network structure with 90k iterations, 2.1% APbb on PASCAL VOC objection detection using Faster R-CNN R50-C4 network structure with 24k iterations.
Exploring Driving-aware Salient Object Detection via Knowledge Transfer
May 18, 2021
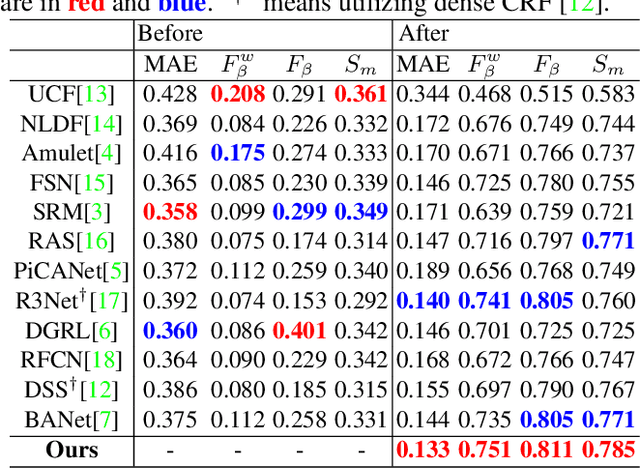

Recently, general salient object detection (SOD) has made great progress with the rapid development of deep neural networks. However, task-aware SOD has hardly been studied due to the lack of task-specific datasets. In this paper, we construct a driving task-oriented dataset where pixel-level masks of salient objects have been annotated. Comparing with general SOD datasets, we find that the cross-domain knowledge difference and task-specific scene gap are two main challenges to focus the salient objects when driving. Inspired by these findings, we proposed a baseline model for the driving task-aware SOD via a knowledge transfer convolutional neural network. In this network, we construct an attentionbased knowledge transfer module to make up the knowledge difference. In addition, an efficient boundary-aware feature decoding module is introduced to perform fine feature decoding for objects in the complex task-specific scenes. The whole network integrates the knowledge transfer and feature decoding modules in a progressive manner. Experiments show that the proposed dataset is very challenging, and the proposed method outperforms 12 state-of-the-art methods on the dataset, which facilitates the development of task-aware SOD.
Structure Guided Lane Detection
May 12, 2021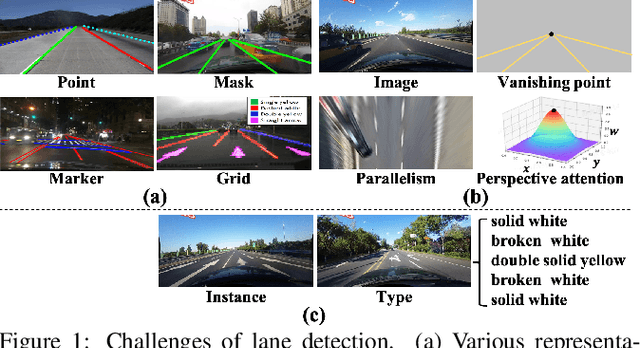
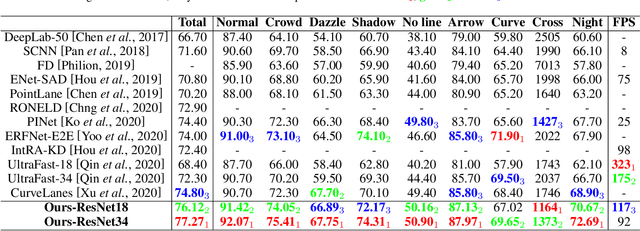
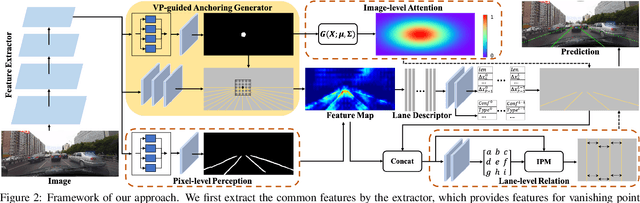
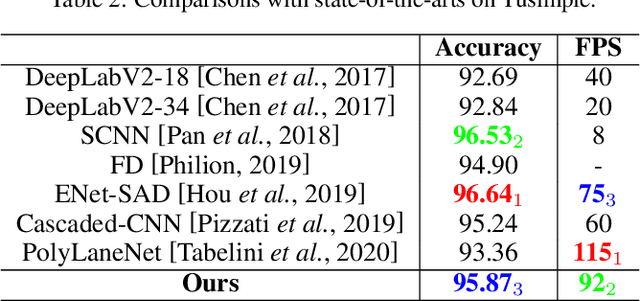
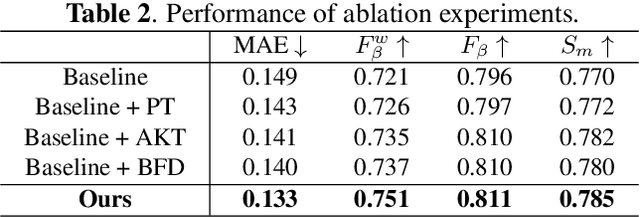
Recently, lane detection has made great progress with the rapid development of deep neural networks and autonomous driving. However, there exist three mainly problems including characterizing lanes, modeling the structural relationship between scenes and lanes, and supporting more attributes (e.g., instance and type) of lanes. In this paper, we propose a novel structure guided framework to solve these problems simultaneously. In the framework, we first introduce a new lane representation to characterize each instance. Then a topdown vanishing point guided anchoring mechanism is proposed to produce intensive anchors, which efficiently capture various lanes. Next, multi-level structural constraints are used to improve the perception of lanes. In the process, pixel-level perception with binary segmentation is introduced to promote features around anchors and restore lane details from bottom up, a lane-level relation is put forward to model structures (i.e., parallel) around lanes, and an image-level attention is used to adaptively attend different regions of the image from the perspective of scenes. With the help of structural guidance, anchors are effectively classified and regressed to obtain precise locations and shapes. Extensive experiments on public benchmark datasets show that the proposed approach outperforms state-of-the-art methods with 117 FPS on a single GPU.
Salient Object Detection with Purificatory Mechanism and Structural Similarity Loss
Dec 18, 2019

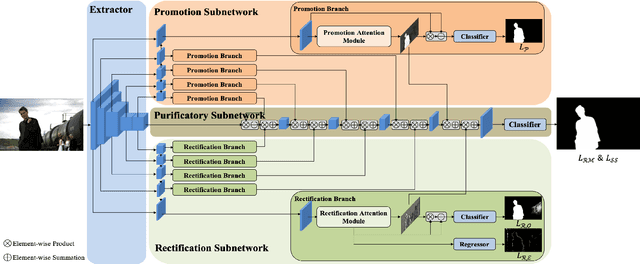

By the aid of attention mechanisms to weight the image features adaptively, recent advanced deep learning-based salient object detection models encourage the predicted results to approximate the ground-truth masks with as large predictable areas as possible. However, these methods do not pay enough attention to small areas prone to misprediction. In this way, it is still tough to accurately locate salient objects due to the existence of regions with indistinguishable foreground and background and regions with complex or fine structures. To address these problems, we propose a novel network with purificatory mechanism and structural similarity loss. Specifically, in order to better locate preliminary salient objects, we first introduce the promotion attention, which is based on spatial and channel attention mechanisms to promote attention to salient regions. Subsequently, for the purpose of restoring the indistinguishable regions that can be regarded as error-prone regions of one model, we propose the rectification attention, which is learned from the areas of wrong prediction and guide the network to focus on error-prone regions thus rectifying errors. Through these two attentions, we use the Purificatory Mechanism to impose strict weights with different regions of the whole salient objects and purify results from hard-to-distinguish regions, thus accurately predicting the locations and details of salient objects. In addition to paying different attention to these hard-to-distinguish regions, we also consider the structural constraints on complex regions and propose the Structural Similarity Loss. The proposed loss models the region-level pair-wise relationship between regions to assist these regions to calibrate their own saliency values. In experiments, the proposed approach efficiently outperforms 19 state-of-the-art methods on six datasets with a notable margin.