 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMachine Learning for Complex Systems with Abnormal Pattern by Exception Maximization Outlier Detection Method
Jul 05, 2024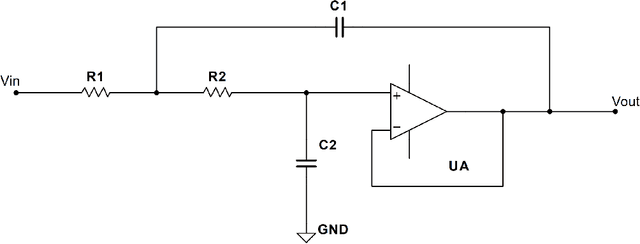
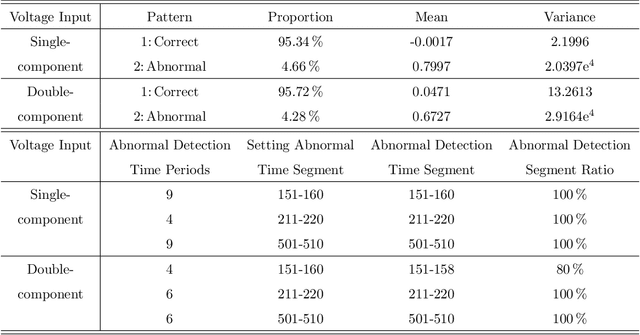
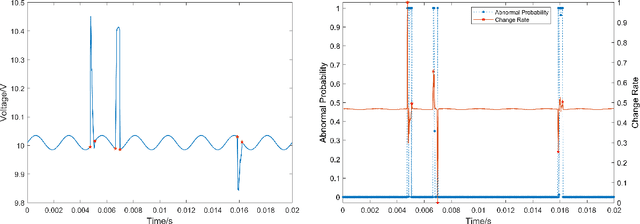

This paper proposes a novel fast online methodology for outlier detection called the exception maximization outlier detection method(EMODM), which employs probabilistic models and statistical algorithms to detect abnormal patterns from the outputs of complex systems. The EMODM is based on a two-state Gaussian mixture model and demonstrates strong performance in probability anomaly detection working on real-time raw data rather than using special prior distribution information. We confirm this using the synthetic data from two numerical cases. For the real-world data, we have detected the short circuit pattern of the circuit system using EMODM by the current and voltage output of a three-phase inverter. The EMODM also found an abnormal period due to COVID-19 in the insured unemployment data of 53 regions in the United States from 2000 to 2024. The application of EMODM to these two real-life datasets demonstrated the effectiveness and accuracy of our algorithm.
Text2Street: Controllable Text-to-image Generation for Street Views
Feb 07, 2024Text-to-image generation has made remarkable progress with the emergence of diffusion models. However, it is still a difficult task to generate images for street views based on text, mainly because the road topology of street scenes is complex, the traffic status is diverse and the weather condition is various, which makes conventional text-to-image models difficult to deal with. To address these challenges, we propose a novel controllable text-to-image framework, named \textbf{Text2Street}. In the framework, we first introduce the lane-aware road topology generator, which achieves text-to-map generation with the accurate road structure and lane lines armed with the counting adapter, realizing the controllable road topology generation. Then, the position-based object layout generator is proposed to obtain text-to-layout generation through an object-level bounding box diffusion strategy, realizing the controllable traffic object layout generation. Finally, the multiple control image generator is designed to integrate the road topology, object layout and weather description to realize controllable street-view image generation. Extensive experiments show that the proposed approach achieves controllable street-view text-to-image generation and validates the effectiveness of the Text2Street framework for street views.
Parameter Identification for Partial Differential Equations with Spatiotemporal Varying Coefficients
Jun 30, 2023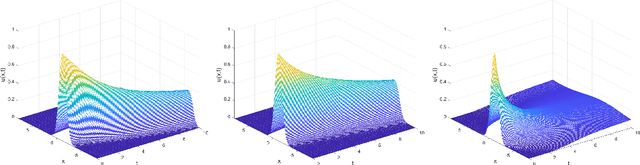
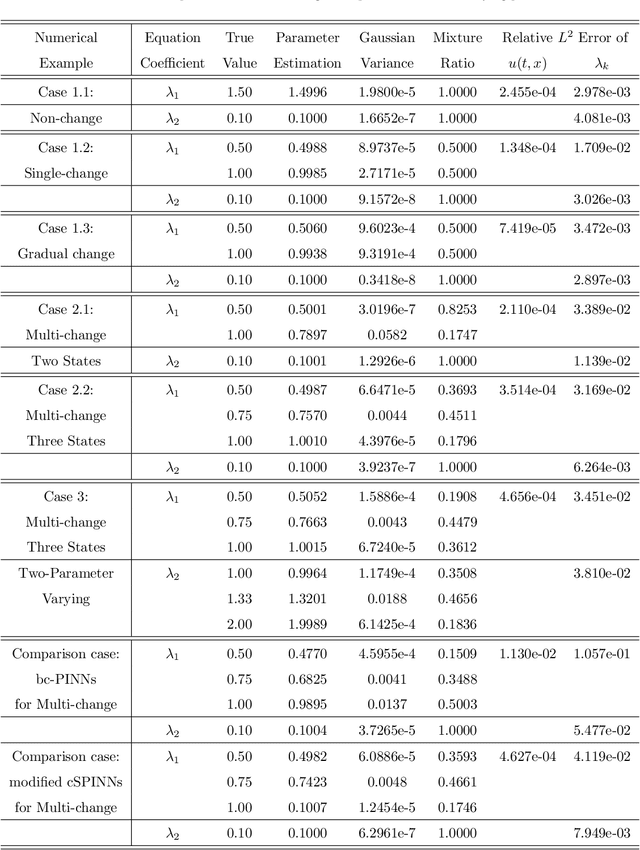
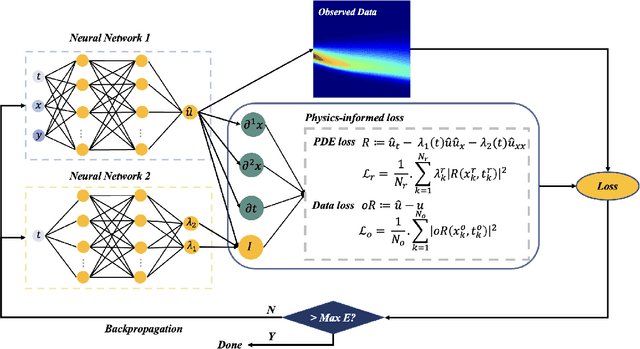
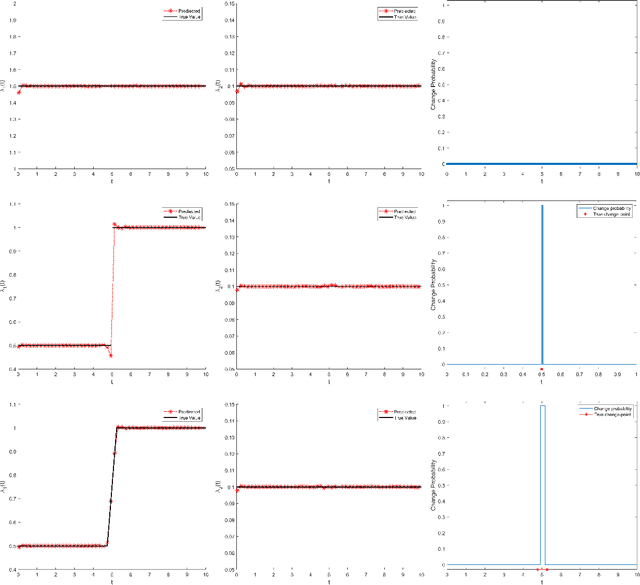
To comprehend complex systems with multiple states, it is imperative to reveal the identity of these states by system outputs. Nevertheless, the mathematical models describing these systems often exhibit nonlinearity so that render the resolution of the parameter inverse problem from the observed spatiotemporal data a challenging endeavor. Starting from the observed data obtained from such systems, we propose a novel framework that facilitates the investigation of parameter identification for multi-state systems governed by spatiotemporal varying parametric partial differential equations. Our framework consists of two integral components: a constrained self-adaptive physics-informed neural network, encompassing a sub-network, as our methodology for parameter identification, and a finite mixture model approach to detect regions of probable parameter variations. Through our scheme, we can precisely ascertain the unknown varying parameters of the complex multi-state system, thereby accomplishing the inversion of the varying parameters. Furthermore, we have showcased the efficacy of our framework on two numerical cases: the 1D Burgers' equation with time-varying parameters and the 2D wave equation with a space-varying parameter.
5th Place Solution for YouTube-VOS Challenge 2022: Video Object Segmentation
Jun 20, 2022
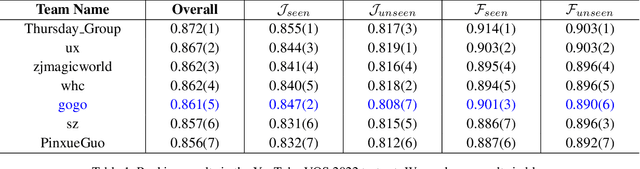
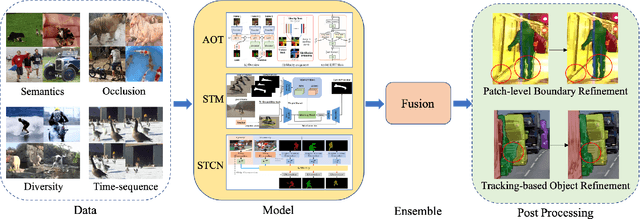

Video object segmentation (VOS) has made significant progress with the rise of deep learning. However, there still exist some thorny problems, for example, similar objects are easily confused and tiny objects are difficult to be found. To solve these problems and further improve the performance of VOS, we propose a simple yet effective solution for this task. In the solution, we first analyze the distribution of the Youtube-VOS dataset and supplement the dataset by introducing public static and video segmentation datasets. Then, we improve three network architectures with different characteristics and train several networks to learn the different characteristics of objects in videos. After that, we use a simple way to integrate all results to ensure that different models complement each other. Finally, subtle post-processing is carried out to ensure accurate video object segmentation with precise boundaries. Extensive experiments on Youtube-VOS dataset show that the proposed solution achieves the state-of-the-art performance with an 86.1% overall score on the YouTube-VOS 2022 test set, which is 5th place on the video object segmentation track of the Youtube-VOS Challenge 2022.