 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge5th Place Solution for YouTube-VOS Challenge 2022: Video Object Segmentation
Paper and Code
Jun 20, 2022
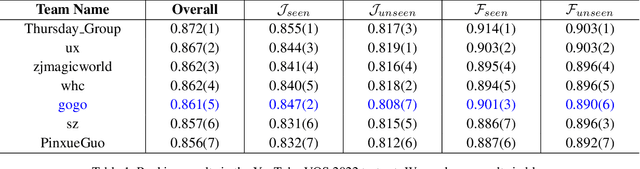
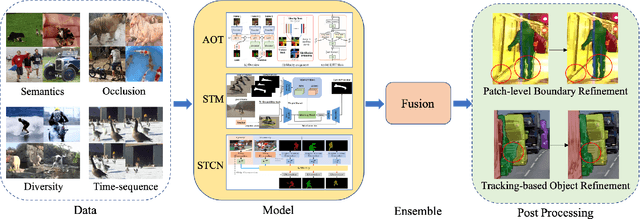

Video object segmentation (VOS) has made significant progress with the rise of deep learning. However, there still exist some thorny problems, for example, similar objects are easily confused and tiny objects are difficult to be found. To solve these problems and further improve the performance of VOS, we propose a simple yet effective solution for this task. In the solution, we first analyze the distribution of the Youtube-VOS dataset and supplement the dataset by introducing public static and video segmentation datasets. Then, we improve three network architectures with different characteristics and train several networks to learn the different characteristics of objects in videos. After that, we use a simple way to integrate all results to ensure that different models complement each other. Finally, subtle post-processing is carried out to ensure accurate video object segmentation with precise boundaries. Extensive experiments on Youtube-VOS dataset show that the proposed solution achieves the state-of-the-art performance with an 86.1% overall score on the YouTube-VOS 2022 test set, which is 5th place on the video object segmentation track of the Youtube-VOS Challenge 2022.