 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePosterOmni: Generalized Artistic Poster Creation via Task Distillation and Unified Reward Feedback
Feb 12, 2026Image-to-poster generation is a high-demand task requiring not only local adjustments but also high-level design understanding. Models must generate text, layout, style, and visual elements while preserving semantic fidelity and aesthetic coherence. The process spans two regimes: local editing, where ID-driven generation, rescaling, filling, and extending must preserve concrete visual entities; and global creation, where layout- and style-driven tasks rely on understanding abstract design concepts. These intertwined demands make image-to-poster a multi-dimensional process coupling entity-preserving editing with concept-driven creation under image-prompt control. To address these challenges, we propose PosterOmni, a generalized artistic poster creation framework that unlocks the potential of a base edit model for multi-task image-to-poster generation. PosterOmni integrates the two regimes, namely local editing and global creation, within a single system through an efficient data-distillation-reward pipeline: (i) constructing multi-scenario image-to-poster datasets covering six task types across entity-based and concept-based creation; (ii) distilling knowledge between local and global experts for supervised fine-tuning; and (iii) applying unified PosterOmni Reward Feedback to jointly align visual entity-preserving and aesthetic preference across all tasks. Additionally, we establish PosterOmni-Bench, a unified benchmark for evaluating both local editing and global creation. Extensive experiments show that PosterOmni significantly enhances reference adherence, global composition quality, and aesthetic harmony, outperforming all open-source baselines and even surpassing several proprietary systems.
PosterCraft: Rethinking High-Quality Aesthetic Poster Generation in a Unified Framework
Jun 12, 2025
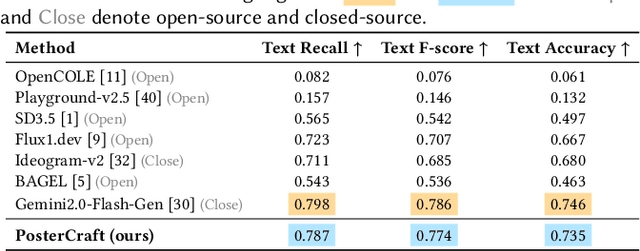
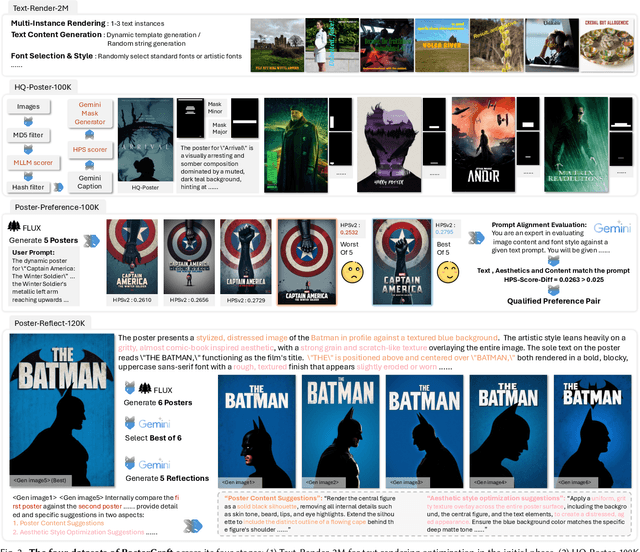
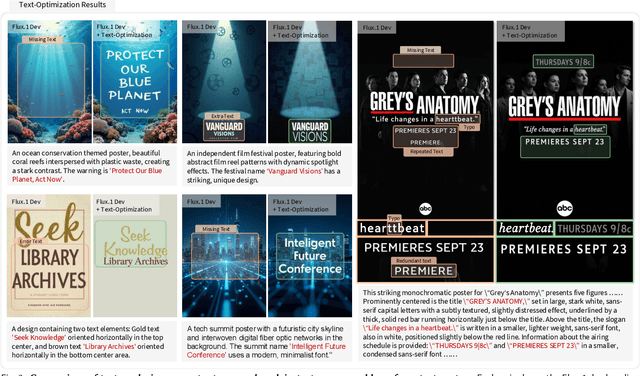
Generating aesthetic posters is more challenging than simple design images: it requires not only precise text rendering but also the seamless integration of abstract artistic content, striking layouts, and overall stylistic harmony. To address this, we propose PosterCraft, a unified framework that abandons prior modular pipelines and rigid, predefined layouts, allowing the model to freely explore coherent, visually compelling compositions. PosterCraft employs a carefully designed, cascaded workflow to optimize the generation of high-aesthetic posters: (i) large-scale text-rendering optimization on our newly introduced Text-Render-2M dataset; (ii) region-aware supervised fine-tuning on HQ-Poster100K; (iii) aesthetic-text-reinforcement learning via best-of-n preference optimization; and (iv) joint vision-language feedback refinement. Each stage is supported by a fully automated data-construction pipeline tailored to its specific needs, enabling robust training without complex architectural modifications. Evaluated on multiple experiments, PosterCraft significantly outperforms open-source baselines in rendering accuracy, layout coherence, and overall visual appeal-approaching the quality of SOTA commercial systems. Our code, models, and datasets can be found in the Project page: https://ephemeral182.github.io/PosterCraft
Marten: Visual Question Answering with Mask Generation for Multi-modal Document Understanding
Mar 18, 2025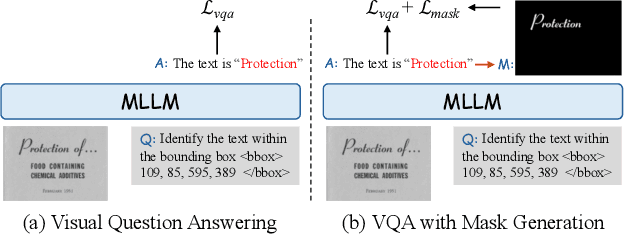
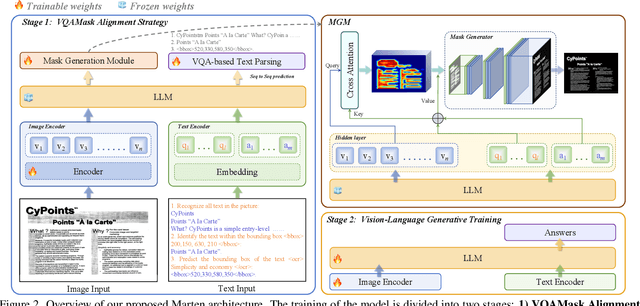
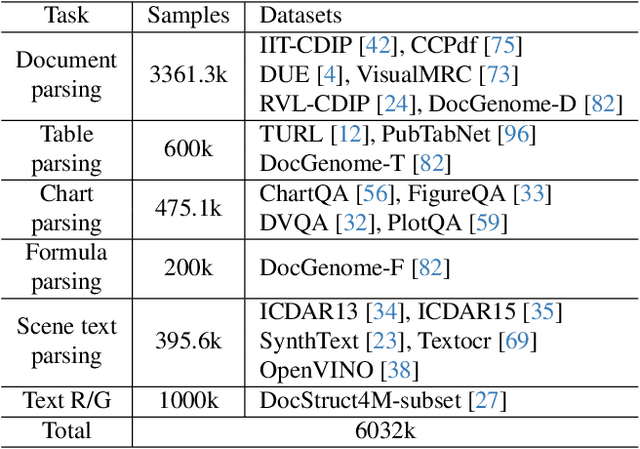
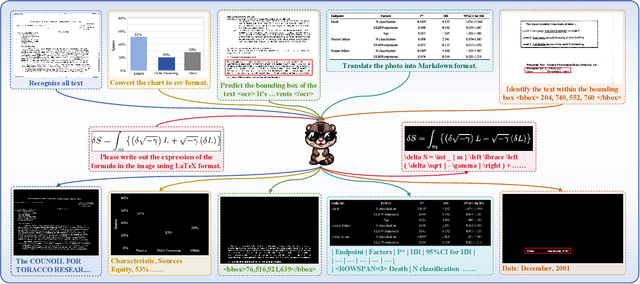
Multi-modal Large Language Models (MLLMs) have introduced a novel dimension to document understanding, i.e., they endow large language models with visual comprehension capabilities; however, how to design a suitable image-text pre-training task for bridging the visual and language modality in document-level MLLMs remains underexplored. In this study, we introduce a novel visual-language alignment method that casts the key issue as a Visual Question Answering with Mask generation (VQAMask) task, optimizing two tasks simultaneously: VQA-based text parsing and mask generation. The former allows the model to implicitly align images and text at the semantic level. The latter introduces an additional mask generator (discarded during inference) to explicitly ensure alignment between visual texts within images and their corresponding image regions at a spatially-aware level. Together, they can prevent model hallucinations when parsing visual text and effectively promote spatially-aware feature representation learning. To support the proposed VQAMask task, we construct a comprehensive image-mask generation pipeline and provide a large-scale dataset with 6M data (MTMask6M). Subsequently, we demonstrate that introducing the proposed mask generation task yields competitive document-level understanding performance. Leveraging the proposed VQAMask, we introduce Marten, a training-efficient MLLM tailored for document-level understanding. Extensive experiments show that our Marten consistently achieves significant improvements among 8B-MLLMs in document-centric tasks. Code and datasets are available at https://github.com/PriNing/Marten.
A Token-level Text Image Foundation Model for Document Understanding
Mar 04, 2025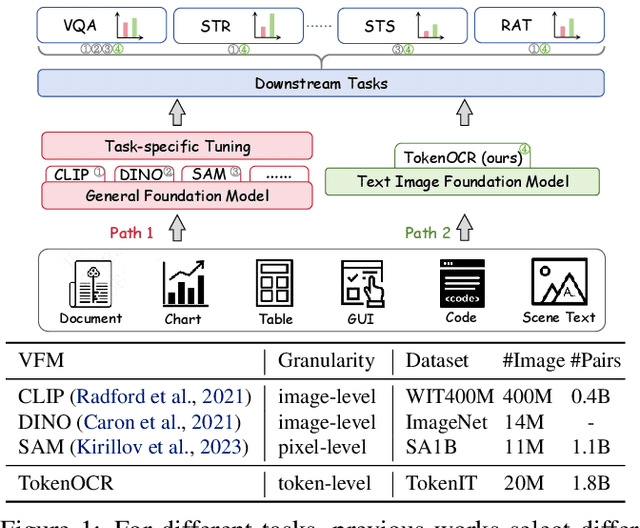
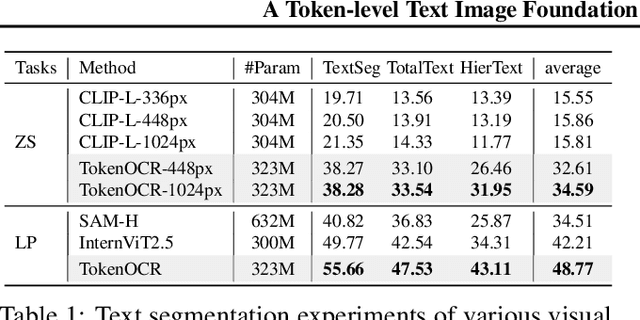
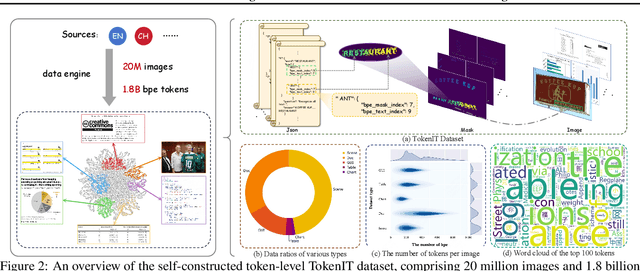
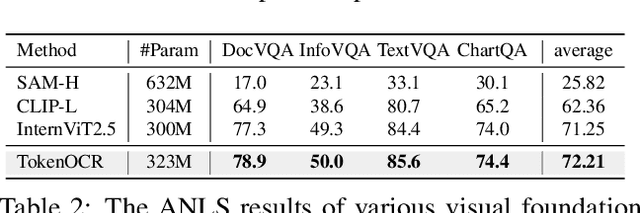
In recent years, general visual foundation models (VFMs) have witnessed increasing adoption, particularly as image encoders for popular multi-modal large language models (MLLMs). However, without semantically fine-grained supervision, these models still encounter fundamental prediction errors in the context of downstream text-image-related tasks, i.e., perception, understanding and reasoning with images containing small and dense texts. To bridge this gap, we develop TokenOCR, the first token-level visual foundation model specifically tailored for text-image-related tasks, designed to support a variety of traditional downstream applications. To facilitate the pretraining of TokenOCR, we also devise a high-quality data production pipeline that constructs the first token-level image text dataset, TokenIT, comprising 20 million images and 1.8 billion token-mask pairs. Furthermore, leveraging this foundation with exceptional image-as-text capability, we seamlessly replace previous VFMs with TokenOCR to construct a document-level MLLM, TokenVL, for VQA-based document understanding tasks. Finally, extensive experiments demonstrate the effectiveness of TokenOCR and TokenVL. Code, datasets, and weights will be available at https://token-family.github.io/TokenOCR_project.
Multimodal Large Language Models for Text-rich Image Understanding: A Comprehensive Review
Feb 23, 2025



The recent emergence of Multi-modal Large Language Models (MLLMs) has introduced a new dimension to the Text-rich Image Understanding (TIU) field, with models demonstrating impressive and inspiring performance. However, their rapid evolution and widespread adoption have made it increasingly challenging to keep up with the latest advancements. To address this, we present a systematic and comprehensive survey to facilitate further research on TIU MLLMs. Initially, we outline the timeline, architecture, and pipeline of nearly all TIU MLLMs. Then, we review the performance of selected models on mainstream benchmarks. Finally, we explore promising directions, challenges, and limitations within the field.
InstructOCR: Instruction Boosting Scene Text Spotting
Dec 20, 2024In the field of scene text spotting, previous OCR methods primarily relied on image encoders and pre-trained text information, but they often overlooked the advantages of incorporating human language instructions. To address this gap, we propose InstructOCR, an innovative instruction-based scene text spotting model that leverages human language instructions to enhance the understanding of text within images. Our framework employs both text and image encoders during training and inference, along with instructions meticulously designed based on text attributes. This approach enables the model to interpret text more accurately and flexibly. Extensive experiments demonstrate the effectiveness of our model and we achieve state-of-the-art results on widely used benchmarks. Furthermore, the proposed framework can be seamlessly applied to scene text VQA tasks. By leveraging instruction strategies during pre-training, the performance on downstream VQA tasks can be significantly improved, with a 2.6% increase on the TextVQA dataset and a 2.1% increase on the ST-VQA dataset. These experimental results provide insights into the benefits of incorporating human language instructions for OCR-related tasks.
Focus on BEV: Self-calibrated Cycle View Transformation for Monocular Birds-Eye-View Segmentation
Oct 21, 2024



Birds-Eye-View (BEV) segmentation aims to establish a spatial mapping from the perspective view to the top view and estimate the semantic maps from monocular images. Recent studies have encountered difficulties in view transformation due to the disruption of BEV-agnostic features in image space. To tackle this issue, we propose a novel FocusBEV framework consisting of $(i)$ a self-calibrated cross view transformation module to suppress the BEV-agnostic image areas and focus on the BEV-relevant areas in the view transformation stage, $(ii)$ a plug-and-play ego-motion-based temporal fusion module to exploit the spatiotemporal structure consistency in BEV space with a memory bank, and $(iii)$ an occupancy-agnostic IoU loss to mitigate both semantic and positional uncertainties. Experimental evidence demonstrates that our approach achieves new state-of-the-art on two popular benchmarks,\ie, 29.2\% mIoU on nuScenes and 35.2\% mIoU on Argoverse.
Text2Street: Controllable Text-to-image Generation for Street Views
Feb 07, 2024



Text-to-image generation has made remarkable progress with the emergence of diffusion models. However, it is still a difficult task to generate images for street views based on text, mainly because the road topology of street scenes is complex, the traffic status is diverse and the weather condition is various, which makes conventional text-to-image models difficult to deal with. To address these challenges, we propose a novel controllable text-to-image framework, named \textbf{Text2Street}. In the framework, we first introduce the lane-aware road topology generator, which achieves text-to-map generation with the accurate road structure and lane lines armed with the counting adapter, realizing the controllable road topology generation. Then, the position-based object layout generator is proposed to obtain text-to-layout generation through an object-level bounding box diffusion strategy, realizing the controllable traffic object layout generation. Finally, the multiple control image generator is designed to integrate the road topology, object layout and weather description to realize controllable street-view image generation. Extensive experiments show that the proposed approach achieves controllable street-view text-to-image generation and validates the effectiveness of the Text2Street framework for street views.
3rd Place Solution for PVUW Challenge 2023: Video Panoptic Segmentation
Jun 11, 2023



In order to deal with the task of video panoptic segmentation in the wild, we propose a robust integrated video panoptic segmentation solution. In our solution, we regard the video panoptic segmentation task as a segmentation target querying task, represent both semantic and instance targets as a set of queries, and then combine these queries with video features extracted by neural networks to predict segmentation masks. In order to improve the learning accuracy and convergence speed of the solution, we add additional tasks of video semantic segmentation and video instance segmentation for joint training. In addition, we also add an additional image semantic segmentation model to further improve the performance of semantic classes. In addition, we also add some additional operations to improve the robustness of the model. Extensive experiments on the VIPSeg dataset show that the proposed solution achieves state-of-the-art performance with 50.04\% VPQ on the VIPSeg test set, which is 3rd place on the video panoptic segmentation track of the PVUW Challenge 2023.
Motion-state Alignment for Video Semantic Segmentation
Apr 18, 2023



In recent years, video semantic segmentation has made great progress with advanced deep neural networks. However, there still exist two main challenges \ie, information inconsistency and computation cost. To deal with the two difficulties, we propose a novel motion-state alignment framework for video semantic segmentation to keep both motion and state consistency. In the framework, we first construct a motion alignment branch armed with an efficient decoupled transformer to capture dynamic semantics, guaranteeing region-level temporal consistency. Then, a state alignment branch composed of a stage transformer is designed to enrich feature spaces for the current frame to extract static semantics and achieve pixel-level state consistency. Next, by a semantic assignment mechanism, the region descriptor of each semantic category is gained from dynamic semantics and linked with pixel descriptors from static semantics. Benefiting from the alignment of these two kinds of effective information, the proposed method picks up dynamic and static semantics in a targeted way, so that video semantic regions are consistently segmented to obtain precise locations with low computational complexity. Extensive experiments on Cityscapes and CamVid datasets show that the proposed approach outperforms state-of-the-art methods and validates the effectiveness of the motion-state alignment framework.