 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMarten: Visual Question Answering with Mask Generation for Multi-modal Document Understanding
Paper and Code
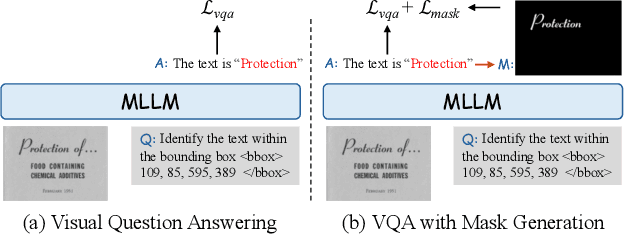
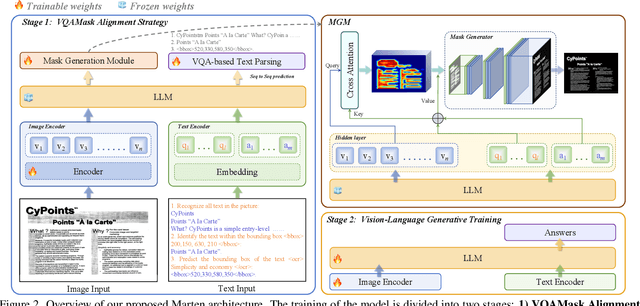
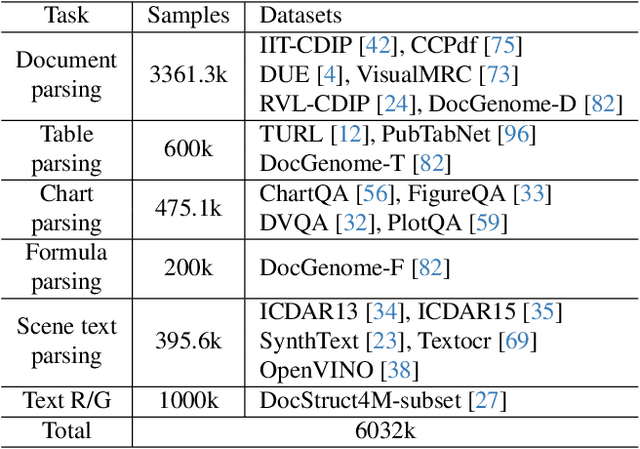
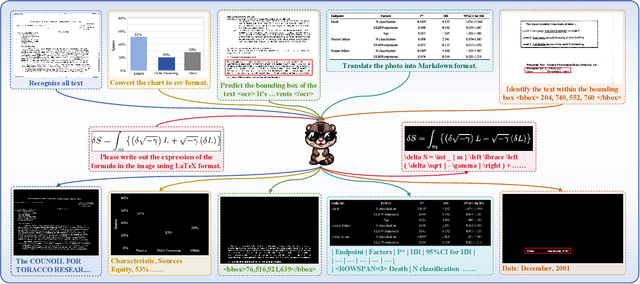
Multi-modal Large Language Models (MLLMs) have introduced a novel dimension to document understanding, i.e., they endow large language models with visual comprehension capabilities; however, how to design a suitable image-text pre-training task for bridging the visual and language modality in document-level MLLMs remains underexplored. In this study, we introduce a novel visual-language alignment method that casts the key issue as a Visual Question Answering with Mask generation (VQAMask) task, optimizing two tasks simultaneously: VQA-based text parsing and mask generation. The former allows the model to implicitly align images and text at the semantic level. The latter introduces an additional mask generator (discarded during inference) to explicitly ensure alignment between visual texts within images and their corresponding image regions at a spatially-aware level. Together, they can prevent model hallucinations when parsing visual text and effectively promote spatially-aware feature representation learning. To support the proposed VQAMask task, we construct a comprehensive image-mask generation pipeline and provide a large-scale dataset with 6M data (MTMask6M). Subsequently, we demonstrate that introducing the proposed mask generation task yields competitive document-level understanding performance. Leveraging the proposed VQAMask, we introduce Marten, a training-efficient MLLM tailored for document-level understanding. Extensive experiments show that our Marten consistently achieves significant improvements among 8B-MLLMs in document-centric tasks. Code and datasets are available at https://github.com/PriNing/Marten.