 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInsCon:Instance Consistency Feature Representation via Self-Supervised Learning
Paper and Code
Mar 15, 2022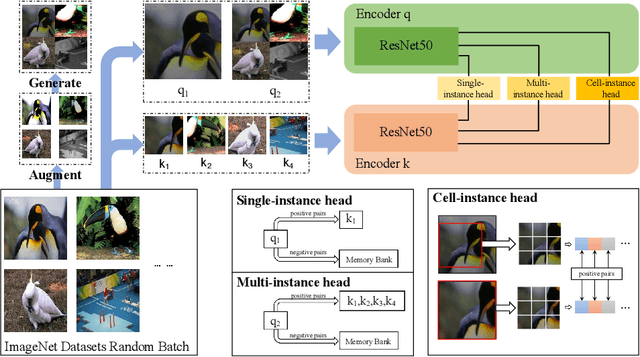
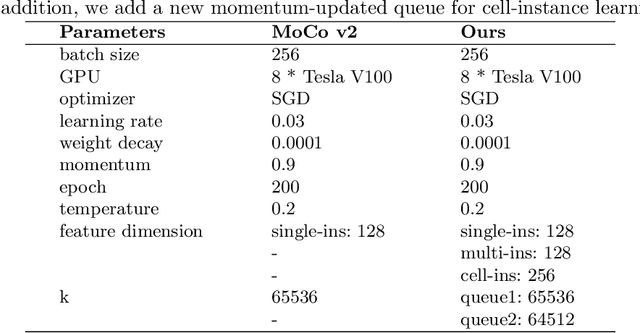
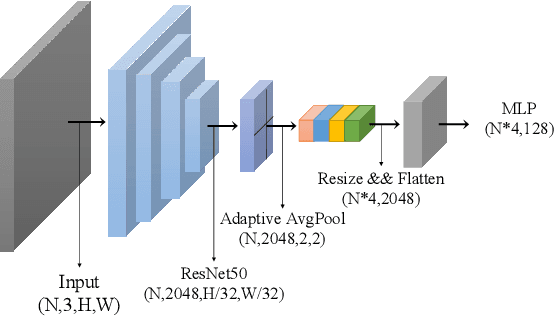
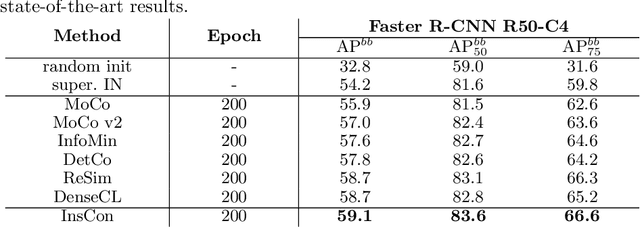
Feature representation via self-supervised learning has reached remarkable success in image-level contrastive learning, which brings impressive performances on image classification tasks. While image-level feature representation mainly focuses on contrastive learning in single instance, it ignores the objective differences between pretext and downstream prediction tasks such as object detection and instance segmentation. In order to fully unleash the power of feature representation on downstream prediction tasks, we propose a new end-to-end self-supervised framework called InsCon, which is devoted to capturing multi-instance information and extracting cell-instance features for object recognition and localization. On the one hand, InsCon builds a targeted learning paradigm that applies multi-instance images as input, aligning the learned feature between corresponding instance views, which makes it more appropriate for multi-instance recognition tasks. On the other hand, InsCon introduces the pull and push of cell-instance, which utilizes cell consistency to enhance fine-grained feature representation for precise boundary localization. As a result, InsCon learns multi-instance consistency on semantic feature representation and cell-instance consistency on spatial feature representation. Experiments demonstrate the method we proposed surpasses MoCo v2 by 1.1% AP^{bb} on COCO object detection and 1.0% AP^{mk} on COCO instance segmentation using Mask R-CNN R50-FPN network structure with 90k iterations, 2.1% APbb on PASCAL VOC objection detection using Faster R-CNN R50-C4 network structure with 24k iterations.