 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTetraJet-v2: Accurate NVFP4 Training for Large Language Models with Oscillation Suppression and Outlier Control
Oct 31, 2025Large Language Models (LLMs) training is prohibitively expensive, driving interest in low-precision fully-quantized training (FQT). While novel 4-bit formats like NVFP4 offer substantial efficiency gains, achieving near-lossless training at such low precision remains challenging. We introduce TetraJet-v2, an end-to-end 4-bit FQT method that leverages NVFP4 for activations, weights, and gradients in all linear layers. We identify two critical issues hindering low-precision LLM training: weight oscillation and outliers. To address these, we propose: 1) an unbiased double-block quantization method for NVFP4 linear layers, 2) OsciReset, an algorithm to suppress weight oscillation, and 3) OutControl, an algorithm to retain outlier accuracy. TetraJet-v2 consistently outperforms prior FP4 training methods on pre-training LLMs across varying model sizes up to 370M and data sizes up to 200B tokens, reducing the performance gap to full-precision training by an average of 51.3%.
LLIA -- Enabling Low-Latency Interactive Avatars: Real-Time Audio-Driven Portrait Video Generation with Diffusion Models
Jun 06, 2025Diffusion-based models have gained wide adoption in the virtual human generation due to their outstanding expressiveness. However, their substantial computational requirements have constrained their deployment in real-time interactive avatar applications, where stringent speed, latency, and duration requirements are paramount. We present a novel audio-driven portrait video generation framework based on the diffusion model to address these challenges. Firstly, we propose robust variable-length video generation to reduce the minimum time required to generate the initial video clip or state transitions, which significantly enhances the user experience. Secondly, we propose a consistency model training strategy for Audio-Image-to-Video to ensure real-time performance, enabling a fast few-step generation. Model quantization and pipeline parallelism are further employed to accelerate the inference speed. To mitigate the stability loss incurred by the diffusion process and model quantization, we introduce a new inference strategy tailored for long-duration video generation. These methods ensure real-time performance and low latency while maintaining high-fidelity output. Thirdly, we incorporate class labels as a conditional input to seamlessly switch between speaking, listening, and idle states. Lastly, we design a novel mechanism for fine-grained facial expression control to exploit our model's inherent capacity. Extensive experiments demonstrate that our approach achieves low-latency, fluid, and authentic two-way communication. On an NVIDIA RTX 4090D, our model achieves a maximum of 78 FPS at a resolution of 384x384 and 45 FPS at a resolution of 512x512, with an initial video generation latency of 140 ms and 215 ms, respectively.
SageAttention2++: A More Efficient Implementation of SageAttention2
May 28, 2025



The efficiency of attention is critical because its time complexity grows quadratically with sequence length. SageAttention2 addresses this by utilizing quantization to accelerate matrix multiplications (Matmul) in attention. To further accelerate SageAttention2, we propose to utilize the faster instruction of FP8 Matmul accumulated in FP16. The instruction is 2x faster than the FP8 Matmul used in SageAttention2. Our experiments show that SageAttention2++ achieves a 3.9x speedup over FlashAttention while maintaining the same attention accuracy as SageAttention2. This means SageAttention2++ effectively accelerates various models, including those for language, image, and video generation, with negligible end-to-end metrics loss. The code will be available at https://github.com/thu-ml/SageAttention.
SageAttention3: Microscaling FP4 Attention for Inference and An Exploration of 8-Bit Training
May 16, 2025The efficiency of attention is important due to its quadratic time complexity. We enhance the efficiency of attention through two key contributions: First, we leverage the new FP4 Tensor Cores in Blackwell GPUs to accelerate attention computation. Our implementation achieves 1038 TOPS on RTX5090, which is a 5x speedup over the fastest FlashAttention on RTX5090. Experiments show that our FP4 attention can accelerate inference of various models in a plug-and-play way. Second, we pioneer low-bit attention to training tasks. Existing low-bit attention works like FlashAttention3 and SageAttention focus only on inference. However, the efficiency of training large models is also important. To explore whether low-bit attention can be effectively applied to training tasks, we design an accurate and efficient 8-bit attention for both forward and backward propagation. Experiments indicate that 8-bit attention achieves lossless performance in fine-tuning tasks but exhibits slower convergence in pretraining tasks. The code will be available at https://github.com/thu-ml/SageAttention.
BEM: Balanced and Entropy-based Mix for Long-Tailed Semi-Supervised Learning
Apr 01, 2024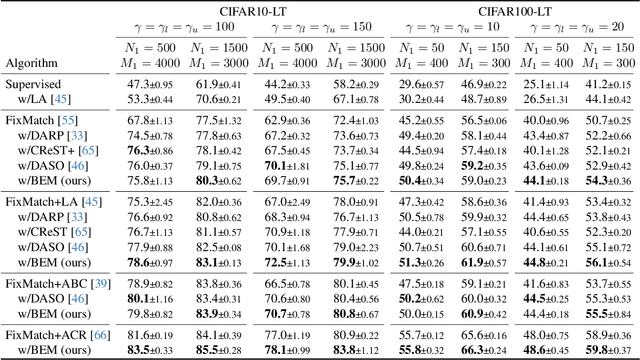
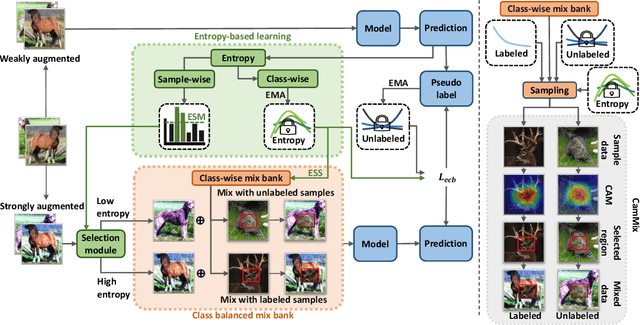
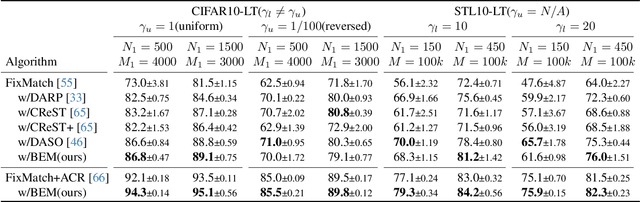

Data mixing methods play a crucial role in semi-supervised learning (SSL), but their application is unexplored in long-tailed semi-supervised learning (LTSSL). The primary reason is that the in-batch mixing manner fails to address class imbalance. Furthermore, existing LTSSL methods mainly focus on re-balancing data quantity but ignore class-wise uncertainty, which is also vital for class balance. For instance, some classes with sufficient samples might still exhibit high uncertainty due to indistinguishable features. To this end, this paper introduces the Balanced and Entropy-based Mix (BEM), a pioneering mixing approach to re-balance the class distribution of both data quantity and uncertainty. Specifically, we first propose a class balanced mix bank to store data of each class for mixing. This bank samples data based on the estimated quantity distribution, thus re-balancing data quantity. Then, we present an entropy-based learning approach to re-balance class-wise uncertainty, including entropy-based sampling strategy, entropy-based selection module, and entropy-based class balanced loss. Our BEM first leverages data mixing for improving LTSSL, and it can also serve as a complement to the existing re-balancing methods. Experimental results show that BEM significantly enhances various LTSSL frameworks and achieves state-of-the-art performances across multiple benchmarks.
EfficientRep:An Efficient Repvgg-style ConvNets with Hardware-aware Neural Network Design
Feb 01, 2023



We present a hardware-efficient architecture of convolutional neural network, which has a repvgg-like architecture. Flops or parameters are traditional metrics to evaluate the efficiency of networks which are not sensitive to hardware including computing ability and memory bandwidth. Thus, how to design a neural network to efficiently use the computing ability and memory bandwidth of hardware is a critical problem. This paper proposes a method how to design hardware-aware neural network. Based on this method, we designed EfficientRep series convolutional networks, which are high-computation hardware(e.g. GPU) friendly and applied in YOLOv6 object detection framework. YOLOv6 has published YOLOv6N/YOLOv6S/YOLOv6M/YOLOv6L models in v1 and v2 versions.
YOLOv6 v3.0: A Full-Scale Reloading
Jan 13, 2023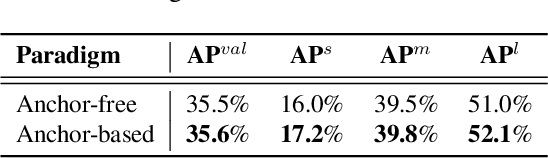
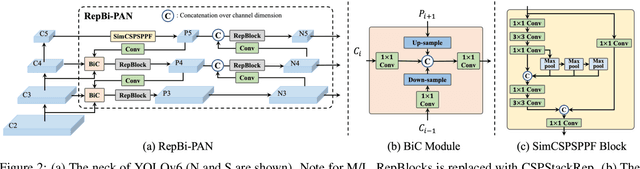
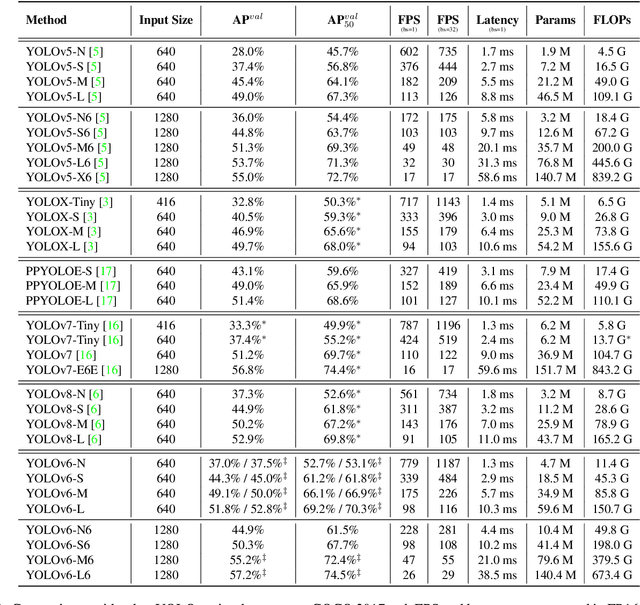
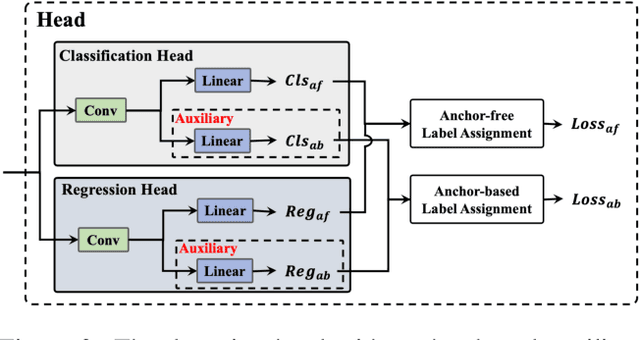
The YOLO community has been in high spirits since our first two releases! By the advent of Chinese New Year 2023, which sees the Year of the Rabbit, we refurnish YOLOv6 with numerous novel enhancements on the network architecture and the training scheme. This release is identified as YOLOv6 v3.0. For a glimpse of performance, our YOLOv6-N hits 37.5% AP on the COCO dataset at a throughput of 1187 FPS tested with an NVIDIA Tesla T4 GPU. YOLOv6-S strikes 45.0% AP at 484 FPS, outperforming other mainstream detectors at the same scale (YOLOv5-S, YOLOv8-S, YOLOX-S and PPYOLOE-S). Whereas, YOLOv6-M/L also achieve better accuracy performance (50.0%/52.8% respectively) than other detectors at a similar inference speed. Additionally, with an extended backbone and neck design, our YOLOv6-L6 achieves the state-of-the-art accuracy in real-time. Extensive experiments are carefully conducted to validate the effectiveness of each improving component. Our code is made available at https://github.com/meituan/YOLOv6.
Semi-MAE: Masked Autoencoders for Semi-supervised Vision Transformers
Jan 04, 2023



Vision Transformer (ViT) suffers from data scarcity in semi-supervised learning (SSL). To alleviate this issue, inspired by masked autoencoder (MAE), which is a data-efficient self-supervised learner, we propose Semi-MAE, a pure ViT-based SSL framework consisting of a parallel MAE branch to assist the visual representation learning and make the pseudo labels more accurate. The MAE branch is designed as an asymmetric architecture consisting of a lightweight decoder and a shared-weights encoder. We feed the weakly-augmented unlabeled data with a high masking ratio to the MAE branch and reconstruct the missing pixels. Semi-MAE achieves 75.9% top-1 accuracy on ImageNet with 10% labels, surpassing prior state-of-the-art in semi-supervised image classification. In addition, extensive experiments demonstrate that Semi-MAE can be readily used for other ViT models and masked image modeling methods.
YOLOv6: A Single-Stage Object Detection Framework for Industrial Applications
Sep 07, 2022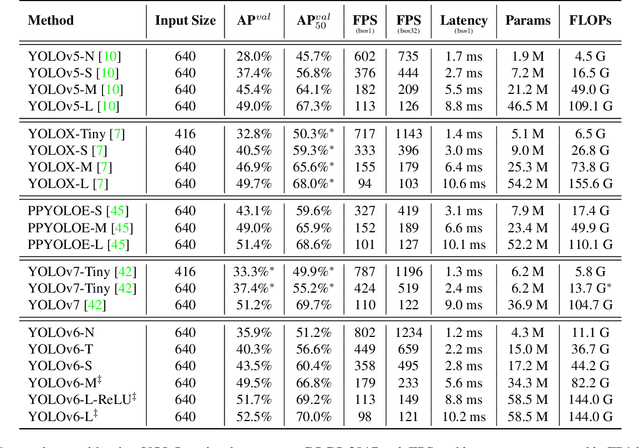
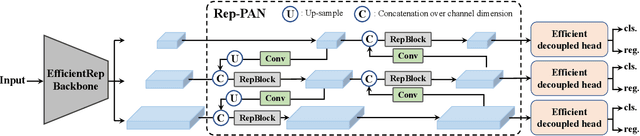
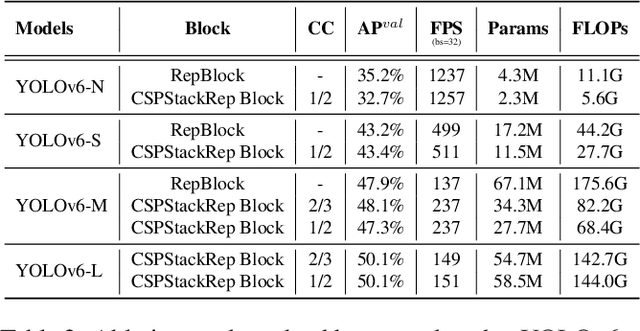
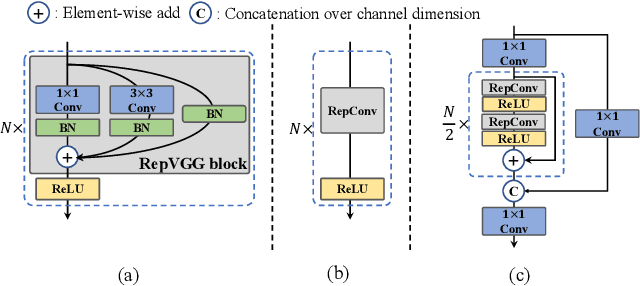
For years, the YOLO series has been the de facto industry-level standard for efficient object detection. The YOLO community has prospered overwhelmingly to enrich its use in a multitude of hardware platforms and abundant scenarios. In this technical report, we strive to push its limits to the next level, stepping forward with an unwavering mindset for industry application. Considering the diverse requirements for speed and accuracy in the real environment, we extensively examine the up-to-date object detection advancements either from industry or academia. Specifically, we heavily assimilate ideas from recent network design, training strategies, testing techniques, quantization, and optimization methods. On top of this, we integrate our thoughts and practice to build a suite of deployment-ready networks at various scales to accommodate diversified use cases. With the generous permission of YOLO authors, we name it YOLOv6. We also express our warm welcome to users and contributors for further enhancement. For a glimpse of performance, our YOLOv6-N hits 35.9% AP on the COCO dataset at a throughput of 1234 FPS on an NVIDIA Tesla T4 GPU. YOLOv6-S strikes 43.5% AP at 495 FPS, outperforming other mainstream detectors at the same scale~(YOLOv5-S, YOLOX-S, and PPYOLOE-S). Our quantized version of YOLOv6-S even brings a new state-of-the-art 43.3% AP at 869 FPS. Furthermore, YOLOv6-M/L also achieves better accuracy performance (i.e., 49.5%/52.3%) than other detectors with a similar inference speed. We carefully conducted experiments to validate the effectiveness of each component. Our code is made available at https://github.com/meituan/YOLOv6.