 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistribution Estimation for Global Data Association via Approximate Bayesian Inference
Sep 19, 2025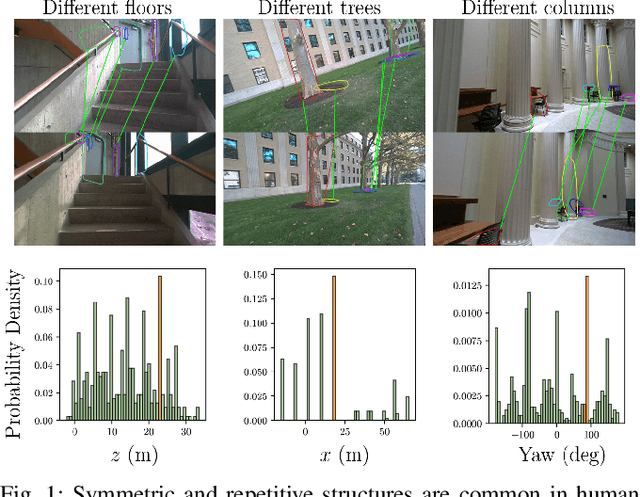
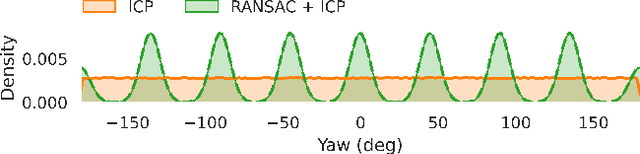

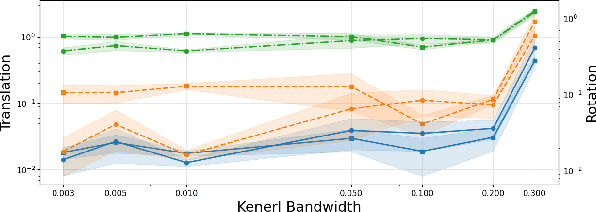
Global data association is an essential prerequisite for robot operation in environments seen at different times or by different robots. Repetitive or symmetric data creates significant challenges for existing methods, which typically rely on maximum likelihood estimation or maximum consensus to produce a single set of associations. However, in ambiguous scenarios, the distribution of solutions to global data association problems is often highly multimodal, and such single-solution approaches frequently fail. In this work, we introduce a data association framework that leverages approximate Bayesian inference to capture multiple solution modes to the data association problem, thereby avoiding premature commitment to a single solution under ambiguity. Our approach represents hypothetical solutions as particles that evolve according to a deterministic or randomized update rule to cover the modes of the underlying solution distribution. Furthermore, we show that our method can incorporate optimization constraints imposed by the data association formulation and directly benefit from GPU-parallelized optimization. Extensive simulated and real-world experiments with highly ambiguous data show that our method correctly estimates the distribution over transformations when registering point clouds or object maps.
Flash Communication: Reducing Tensor Parallelization Bottleneck for Fast Large Language Model Inference
Dec 06, 2024The ever-increasing sizes of large language models necessitate distributed solutions for fast inference that exploit multi-dimensional parallelism, where computational loads are split across various accelerators such as GPU clusters. However, this approach often introduces significant communication overhead, especially on devices with limited bandwidth. In this paper, we introduce \emph{Flash Communication}, a novel low-bit compression technique designed to alleviate the tensor-parallelism communication bottleneck during inference. Our method substantially boosts intra-node communication speed by more than 3x and reduces the \emph{time-to-first-token} by 2x, with nearly no sacrifice in model accuracy. Extensive experiments on various up-to-date LLMs demonstrate the effectiveness of our approach.
Integer Scale: A Free Lunch for Faster Fine-grained Quantization of LLMs
May 23, 2024We introduce Integer Scale, a novel post-training quantization scheme for large language models that effectively resolves the inference bottleneck in current fine-grained quantization approaches while maintaining similar accuracies. Integer Scale is a free lunch as it requires no extra calibration or fine-tuning which will otherwise incur additional costs. It can be used plug-and-play for most fine-grained quantization methods. Its integration results in at most 1.85x end-to-end speed boost over the original counterpart with comparable accuracy. Additionally, due to the orchestration of the proposed Integer Scale and fine-grained quantization, we resolved the quantization difficulty for Mixtral-8x7B and LLaMA-3 models with negligible performance degradation, and it comes with an end-to-end speed boost of 2.13x, and 2.31x compared with their FP16 versions respectively.
UMIE: Unified Multimodal Information Extraction with Instruction Tuning
Jan 05, 2024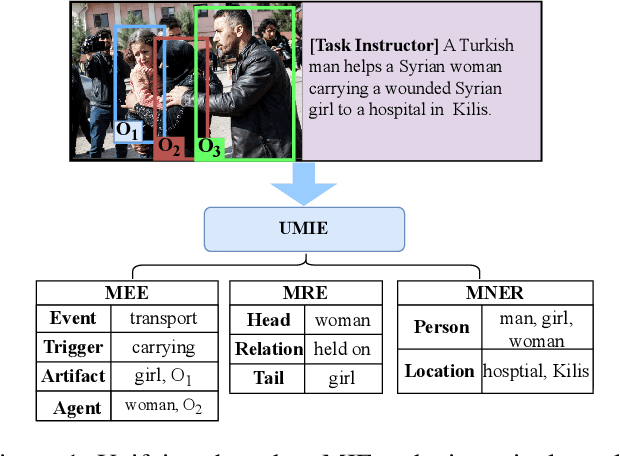

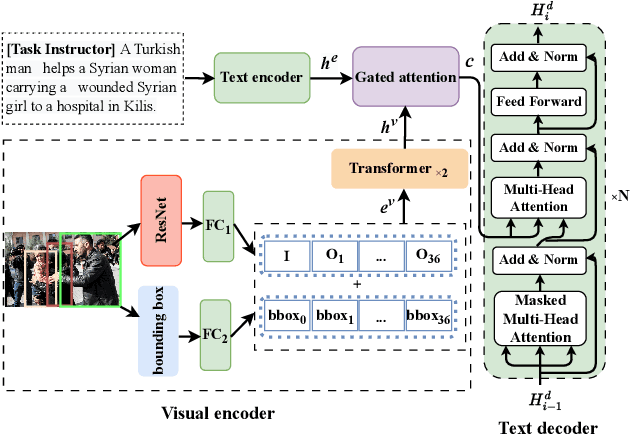

Multimodal information extraction (MIE) gains significant attention as the popularity of multimedia content increases. However, current MIE methods often resort to using task-specific model structures, which results in limited generalizability across tasks and underutilizes shared knowledge across MIE tasks. To address these issues, we propose UMIE, a unified multimodal information extractor to unify three MIE tasks as a generation problem using instruction tuning, being able to effectively extract both textual and visual mentions. Extensive experiments show that our single UMIE outperforms various state-of-the-art (SoTA) methods across six MIE datasets on three tasks. Furthermore, in-depth analysis demonstrates UMIE's strong generalization in the zero-shot setting, robustness to instruction variants, and interpretability. Our research serves as an initial step towards a unified MIE model and initiates the exploration into both instruction tuning and large language models within the MIE domain. Our code, data, and model are available at https://github.com/ZUCC-AI/UMIE
A Speed Odyssey for Deployable Quantization of LLMs
Nov 16, 2023



The large language model era urges faster and less costly inference. Prior model compression works on LLMs tend to undertake a software-centric approach primarily focused on the simulated quantization performance. By neglecting the feasibility of deployment, these approaches are typically disabled in real practice. They used to drastically push down the quantization bit range for a reduced computation which might not be supported by the mainstream hardware, or involve sophisticated algorithms that introduce extra computation or memory access overhead. We argue that pursuing a hardware-centric approach in the construction of quantization algorithms is crucial. In this regard, we are driven to build our compression method on top of hardware awareness, eliminating impractical algorithm choices while maximizing the benefit of hardware acceleration. Our method, OdysseyLLM, comes with a novel W4A8 kernel implementation called FastGEMM and a combined recipe of quantization strategies. Extensive experiments manifest the superiority of our W4A8 method which brings the actual speed boosting up to \textbf{4$\times$} compared to Hugging Face FP16 inference and \textbf{2.23$\times$} vs. the state-of-the-art inference engine TensorRT-LLM in FP16, and \textbf{1.45$\times$} vs. TensorRT-LLM in INT8, yet without substantially harming the performance.
Norm Tweaking: High-performance Low-bit Quantization of Large Language Models
Sep 06, 2023As the size of large language models (LLMs) continues to grow, model compression without sacrificing accuracy has become a crucial challenge for deployment. While some quantization methods, such as GPTQ, have made progress in achieving acceptable 4-bit weight-only quantization, attempts at lower bit quantization often result in severe performance degradation. In this paper, we introduce a technique called norm tweaking, which can be used as a plugin in current PTQ methods to achieve high precision while being cost-efficient. Our approach is inspired by the observation that rectifying the quantized activation distribution to match its float counterpart can readily restore accuracy for LLMs. To achieve this, we carefully design a tweaking strategy that includes calibration data generation and channel-wise distance constraint to update the weights of normalization layers for better generalization. We conduct extensive experiments on various datasets using several open-sourced LLMs. Our method demonstrates significant improvements in both weight-only quantization and joint quantization of weights and activations, surpassing existing PTQ methods. On GLM-130B and OPT-66B, our method even achieves the same level of accuracy at 2-bit quantization as their float ones. Our simple and effective approach makes it more practical for real-world applications.
FPTQ: Fine-grained Post-Training Quantization for Large Language Models
Aug 30, 2023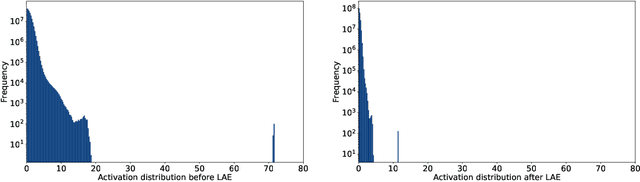



In the era of large-scale language models, the substantial parameter size poses significant challenges for deployment. Being a prevalent compression technique, quantization has emerged as the mainstream practice to tackle this issue, which is mainly centered on two recipes W8A8 and W4A16 (i.e. weights and activations in such bit widths). In this study, we propose a novel W4A8 post-training quantization method for the available open-sourced LLMs, which combines the advantages of both two recipes. Therefore, we can leverage the benefit in the I/O utilization of 4-bit weight quantization and the acceleration due to 8-bit matrix computation. Nevertheless, the W4A8 faces notorious performance degradation. As a remedy, we involve layerwise activation quantization strategies which feature a novel logarithmic equalization for most intractable layers, and we combine them with fine-grained weight quantization. Without whistles and bells, we eliminate the necessity for further fine-tuning and obtain the state-of-the-art W4A8 quantized performance on BLOOM, LLaMA, and LLaMA-2 on standard benchmarks. We confirm that the W4A8 quantization is achievable for the deployment of large language models, fostering their wide-spreading real-world applications.
EAPruning: Evolutionary Pruning for Vision Transformers and CNNs
Oct 01, 2022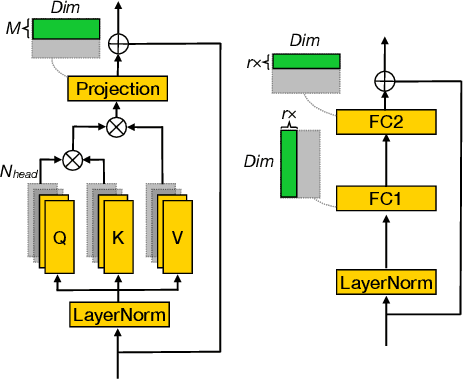
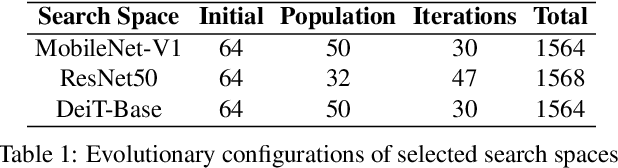
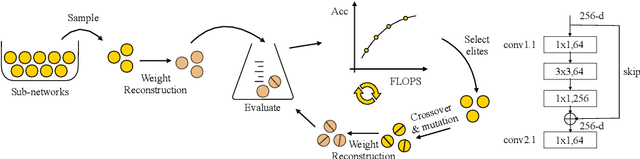
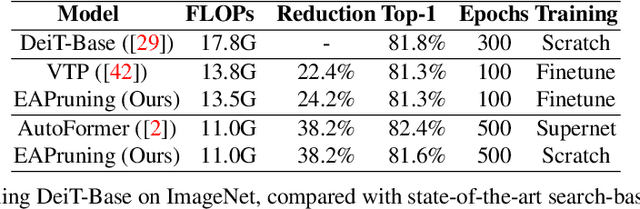
Structured pruning greatly eases the deployment of large neural networks in resource-constrained environments. However, current methods either involve strong domain expertise, require extra hyperparameter tuning, or are restricted only to a specific type of network, which prevents pervasive industrial applications. In this paper, we undertake a simple and effective approach that can be easily applied to both vision transformers and convolutional neural networks. Specifically, we consider pruning as an evolution process of sub-network structures that inherit weights through reconstruction techniques. We achieve a 50% FLOPS reduction for ResNet50 and MobileNetV1, leading to 1.37x and 1.34x speedup respectively. For DeiT-Base, we reach nearly 40% FLOPs reduction and 1.4x speedup. Our code will be made available.
YOLOv6: A Single-Stage Object Detection Framework for Industrial Applications
Sep 07, 2022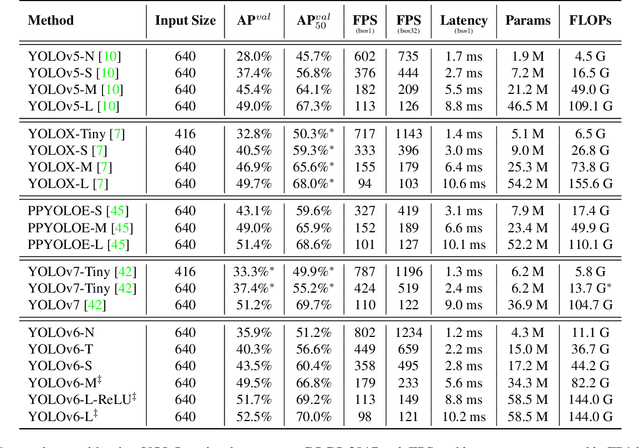
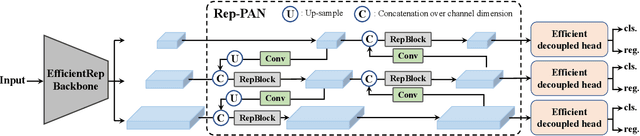
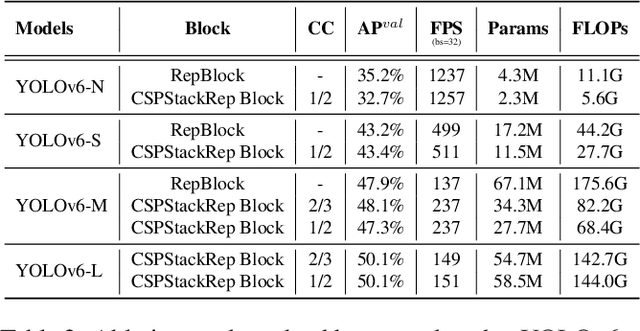
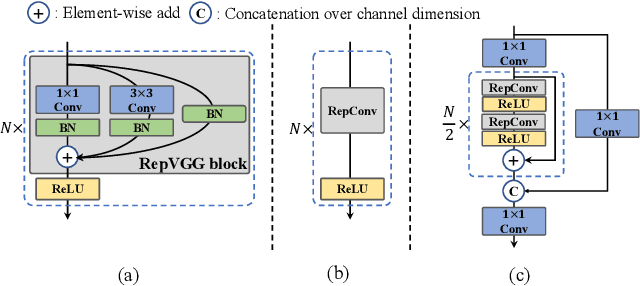
For years, the YOLO series has been the de facto industry-level standard for efficient object detection. The YOLO community has prospered overwhelmingly to enrich its use in a multitude of hardware platforms and abundant scenarios. In this technical report, we strive to push its limits to the next level, stepping forward with an unwavering mindset for industry application. Considering the diverse requirements for speed and accuracy in the real environment, we extensively examine the up-to-date object detection advancements either from industry or academia. Specifically, we heavily assimilate ideas from recent network design, training strategies, testing techniques, quantization, and optimization methods. On top of this, we integrate our thoughts and practice to build a suite of deployment-ready networks at various scales to accommodate diversified use cases. With the generous permission of YOLO authors, we name it YOLOv6. We also express our warm welcome to users and contributors for further enhancement. For a glimpse of performance, our YOLOv6-N hits 35.9% AP on the COCO dataset at a throughput of 1234 FPS on an NVIDIA Tesla T4 GPU. YOLOv6-S strikes 43.5% AP at 495 FPS, outperforming other mainstream detectors at the same scale~(YOLOv5-S, YOLOX-S, and PPYOLOE-S). Our quantized version of YOLOv6-S even brings a new state-of-the-art 43.3% AP at 869 FPS. Furthermore, YOLOv6-M/L also achieves better accuracy performance (i.e., 49.5%/52.3%) than other detectors with a similar inference speed. We carefully conducted experiments to validate the effectiveness of each component. Our code is made available at https://github.com/meituan/YOLOv6.
ScarletNAS: Bridging the Gap Between Scalability and Fairness in Neural Architecture Search
Sep 13, 2019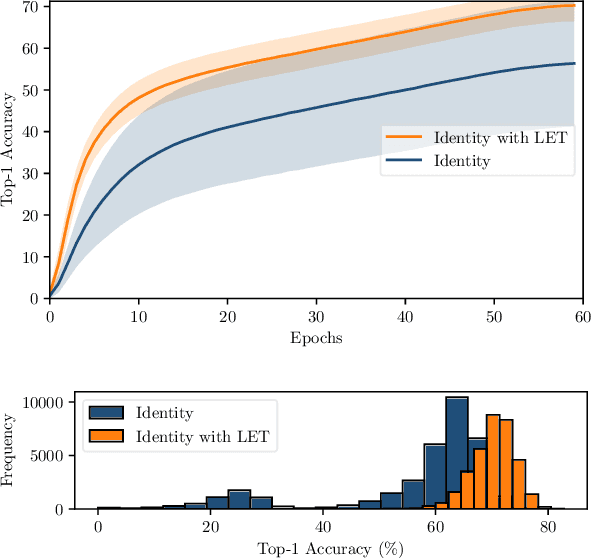

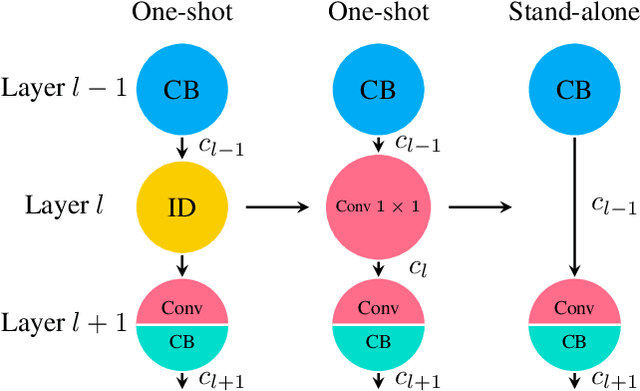

One-shot neural architecture search features fast training of a supernet in a single run. A pivotal issue for this weight-sharing approach is the lacking of scalability. A simple adjustment with identity block renders a scalable supernet but it arouses unstable training, which makes the subsequent model ranking unreliable. In this paper, we introduce linearly equivalent transformation on identity blocks to soothe training perturbation, providing with the proof that such a transformed model is identical with the original one as per representational power. Our overall method is hereby named as SCARLET (SCAlable supeRnet with Linearly Equivalent Transformation). We show through experiments that linearly equivalent transformations can indeed harmonize the supernet training. With an EfficientNet-like search space and a multi-objective reinforced evolutionary backend, it generates a series of competitive models: SCARLET-A achieves 76.9% top-1 accuracy on ImageNet which outperforms EfficientNet-B0 by a large margin; the shallower SCARLET-B exemplifies the proposed scalability which attains the same accuracy 76.3% as EfficientNet-B0 with much fewer FLOPs. Moreover, our manually scaled SCARLET-A2 hits 79.5%, SCARLET-A4 82.3%, which are on par with EfficientNet-B2 and EfficientNet-B4 respectively. The models and evaluation code are released online https://github.com/xiaomi-automl/ScarletNAS .