 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMoGA: Searching Beyond MobileNetV3
Sep 13, 2019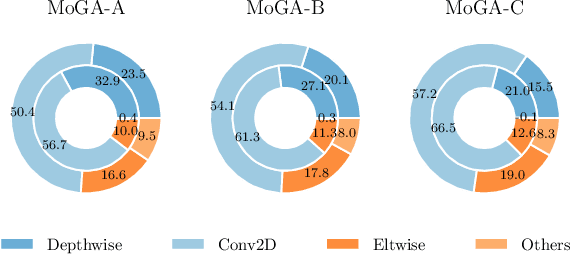

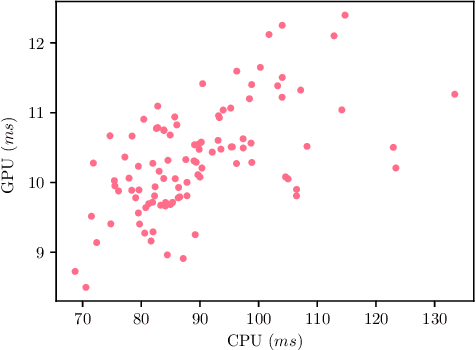
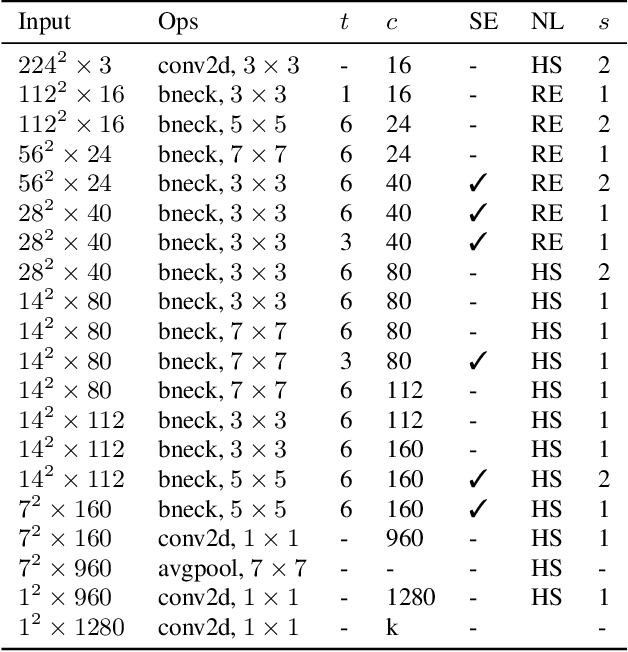
The evolution of MobileNets has laid a solid foundation for neural network applications on mobile end. With the latest MobileNetV3, neural architecture search again claimed its supremacy in network design. Unfortunately, till today all mobile methods mainly focus on CPU latencies instead of GPU, the latter, however, is much preferred in practice for it has faster speed, lower overhead and less interference. Bearing the target hardware in mind, we propose the first Mobile GPU-Aware (MoGA) neural architecture search in order to be precisely tailored for real-world applications. Further, the ultimate objective to devise a mobile network lies in achieving better performance by maximizing the utilization of bounded resources. Urging higher capability while restraining time consumption is not reconcilable. We alleviate the tension by weighted evolution techniques. Moreover, we encourage increasing the number of parameters for higher representational power. With 200x fewer GPU days than MnasNet, we obtain a series of models that outperform MobileNetV3 under the similar latency constraints, i.e., MoGA-A achieves 75.9% top-1 accuracy on ImageNet, MoGA-B meets 75.5% which costs only 0.5 ms more on mobile GPU. MoGA-C best attests GPU-awareness by reaching 75.3% and being slower on CPU but faster on GPU.The models and test code is made available here https://github.com/xiaomi-automl/MoGA.
ScarletNAS: Bridging the Gap Between Scalability and Fairness in Neural Architecture Search
Sep 13, 2019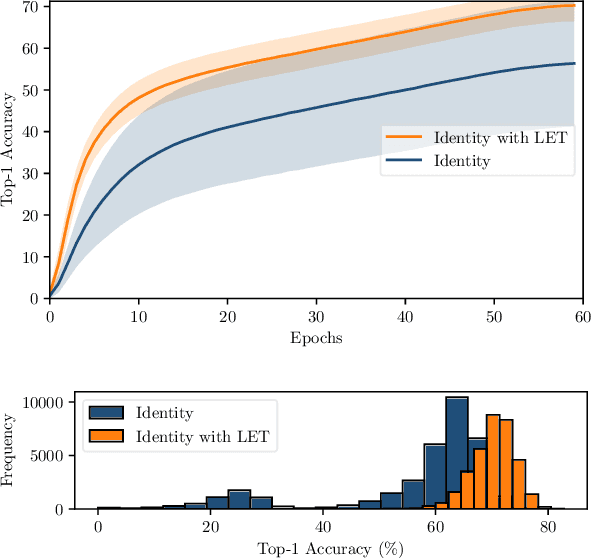

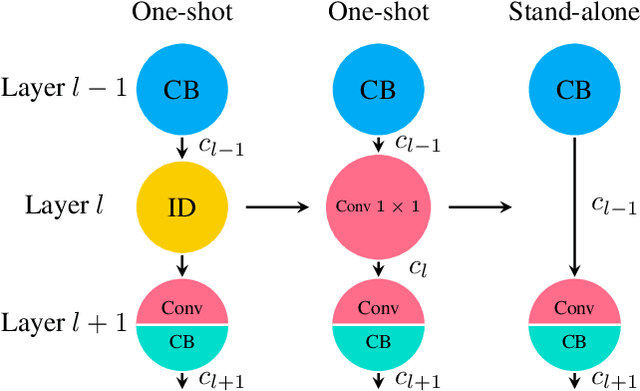

One-shot neural architecture search features fast training of a supernet in a single run. A pivotal issue for this weight-sharing approach is the lacking of scalability. A simple adjustment with identity block renders a scalable supernet but it arouses unstable training, which makes the subsequent model ranking unreliable. In this paper, we introduce linearly equivalent transformation on identity blocks to soothe training perturbation, providing with the proof that such a transformed model is identical with the original one as per representational power. Our overall method is hereby named as SCARLET (SCAlable supeRnet with Linearly Equivalent Transformation). We show through experiments that linearly equivalent transformations can indeed harmonize the supernet training. With an EfficientNet-like search space and a multi-objective reinforced evolutionary backend, it generates a series of competitive models: SCARLET-A achieves 76.9% top-1 accuracy on ImageNet which outperforms EfficientNet-B0 by a large margin; the shallower SCARLET-B exemplifies the proposed scalability which attains the same accuracy 76.3% as EfficientNet-B0 with much fewer FLOPs. Moreover, our manually scaled SCARLET-A2 hits 79.5%, SCARLET-A4 82.3%, which are on par with EfficientNet-B2 and EfficientNet-B4 respectively. The models and evaluation code are released online https://github.com/xiaomi-automl/ScarletNAS .
FairNAS: Rethinking Evaluation Fairness of Weight Sharing Neural Architecture Search
Aug 14, 2019


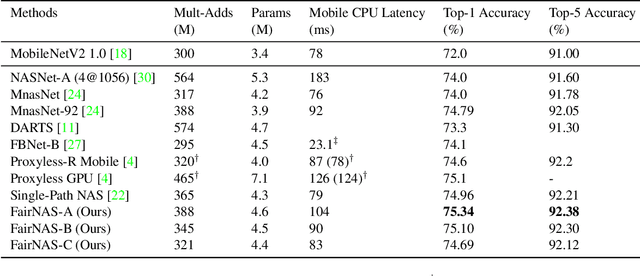
The ability to rank models by its real strength is the key to Neural Architecture Search. Traditional approaches adopt an incomplete training for such purpose which is still very costly. One-shot methods are thus devised to cut the expense by reusing the same set of weights. However, it is uncertain whether shared weights are truly effective. It is also unclear if a picked model is better because of its vigorous representational power or simply because it is overtrained. In order to remove the suspicion, we propose a novel idea called Fair Neural Architecture Search (FairNAS), in which a strict fairness constraint is enforced for fair inheritance and training. In this way, our supernet exhibits nice convergence and very high training accuracy. The performance of any sampled model loaded with shared weights from the supernet strongly correlates with that of stand-alone counterpart when trained fully. This result dramatically improves the searching efficiency, with a multi-objective reinforced evolutionary search backend, our pipeline generated a new set of state-of-the-art architectures on ImageNet: FairNAS-A attains 75.34% top-1 validation accuracy on ImageNet, FairNAS-B 75.10%, FairNAS-C 74.69%, even with lower multi-adds and/or fewer number of parameters compared with others. The models and their evaluation code are made publicly available online http://github.com/fairnas/FairNAS.
Fast, Accurate and Lightweight Super-Resolution with Neural Architecture Search
Jan 24, 2019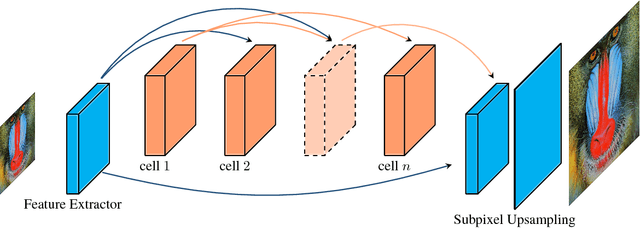
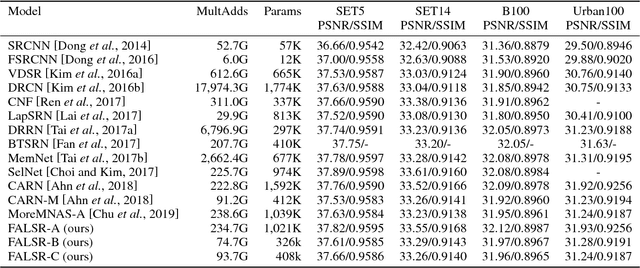

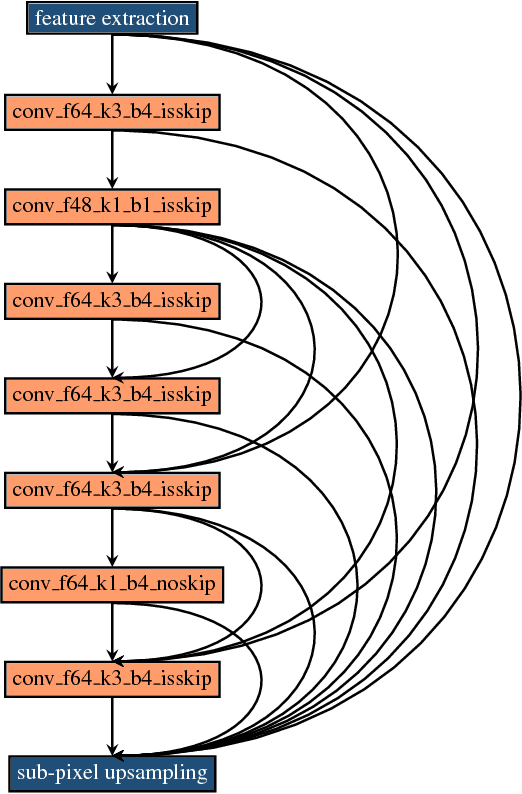
Deep convolution neural networks demonstrate impressive results in the super-resolution domain. A series of studies concentrate on improving peak signal noise ratio (PSNR) by using much deeper layers, which are not friendly to constrained resources. Pursuing a trade-off between the restoration capacity and the simplicity of models is still non-trivial. Recent contributions are struggling to manually maximize this balance, while our work achieves the same goal automatically with neural architecture search. Specifically, we handle super-resolution with a multi-objective approach. We also propose an elastic search tactic at both micro and macro level, based on a hybrid controller that profits from evolutionary computation and reinforcement learning. Quantitative experiments help us to draw a conclusion that our generated models dominate most of the state-of-the-art methods with respect to the individual FLOPS.
Multi-Objective Reinforced Evolution in Mobile Neural Architecture Search
Jan 16, 2019

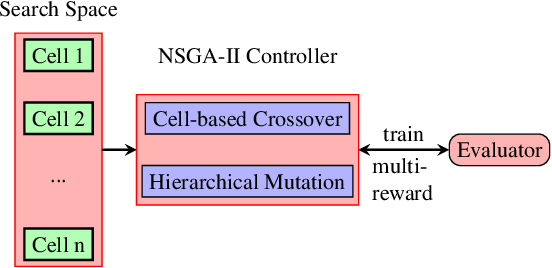
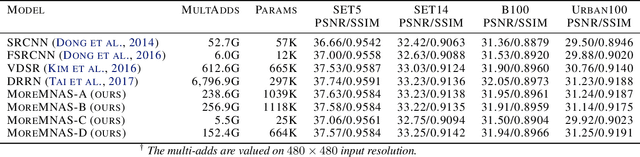
Fabricating neural models for a wide range of mobile devices demands for a specific design of networks due to highly constrained resources. Both evolution algorithms (EA) and reinforced learning methods (RL) have been dedicated to solve neural architecture search problems. However, these combinations usually concentrate on a single objective such as the error rate of image classification. They also fail to harness the very benefits from both sides. In this paper, we present a new multi-objective oriented algorithm called MoreMNAS (Multi-Objective Reinforced Evolution in Mobile Neural Architecture Search) by leveraging good virtues from both EA and RL. In particular, we incorporate a variant of multi-objective genetic algorithm NSGA-II, in which the search space is composed of various cells so that crossovers and mutations can be performed at the cell level. Moreover, reinforced control is mixed with a natural mutating process to regulate arbitrary mutation, maintaining a delicate balance between exploration and exploitation. Therefore, not only does our method prevent the searched models from degrading during the evolution process, but it also makes better use of learned knowledge. Our experiments conducted in Super-resolution domain (SR) deliver rivalling models compared to some state-of-the-art methods with fewer FLOPS.