 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScarletNAS: Bridging the Gap Between Scalability and Fairness in Neural Architecture Search
Paper and Code
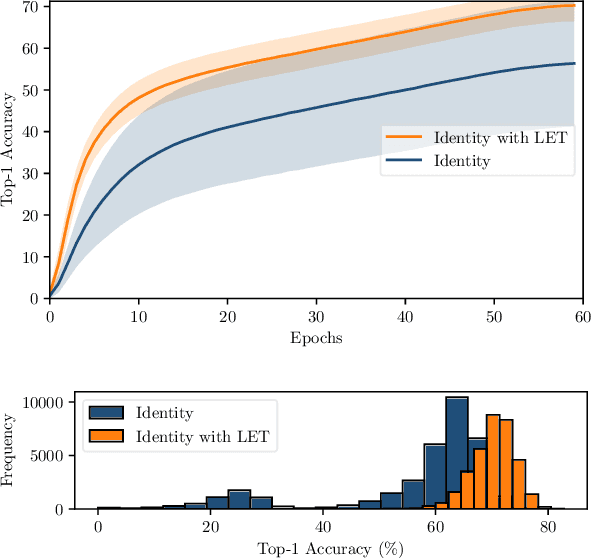

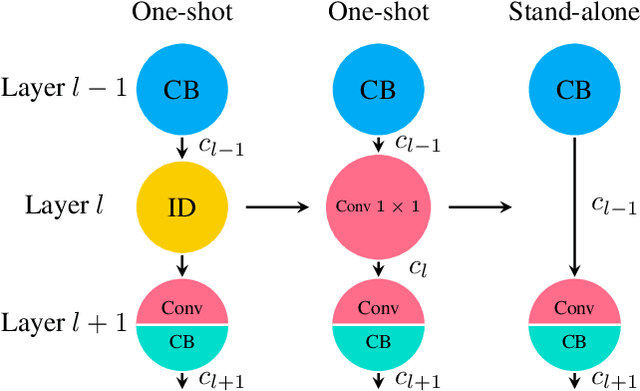

One-shot neural architecture search features fast training of a supernet in a single run. A pivotal issue for this weight-sharing approach is the lacking of scalability. A simple adjustment with identity block renders a scalable supernet but it arouses unstable training, which makes the subsequent model ranking unreliable. In this paper, we introduce linearly equivalent transformation on identity blocks to soothe training perturbation, providing with the proof that such a transformed model is identical with the original one as per representational power. Our overall method is hereby named as SCARLET (SCAlable supeRnet with Linearly Equivalent Transformation). We show through experiments that linearly equivalent transformations can indeed harmonize the supernet training. With an EfficientNet-like search space and a multi-objective reinforced evolutionary backend, it generates a series of competitive models: SCARLET-A achieves 76.9% top-1 accuracy on ImageNet which outperforms EfficientNet-B0 by a large margin; the shallower SCARLET-B exemplifies the proposed scalability which attains the same accuracy 76.3% as EfficientNet-B0 with much fewer FLOPs. Moreover, our manually scaled SCARLET-A2 hits 79.5%, SCARLET-A4 82.3%, which are on par with EfficientNet-B2 and EfficientNet-B4 respectively. The models and evaluation code are released online https://github.com/xiaomi-automl/ScarletNAS .