 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMoGA: Searching Beyond MobileNetV3
Paper and Code
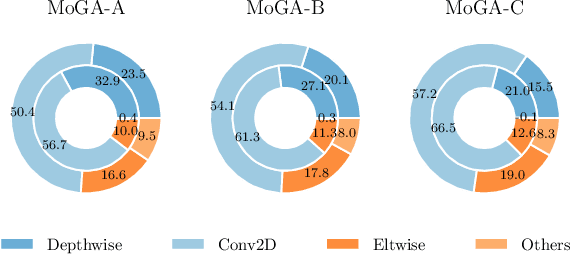

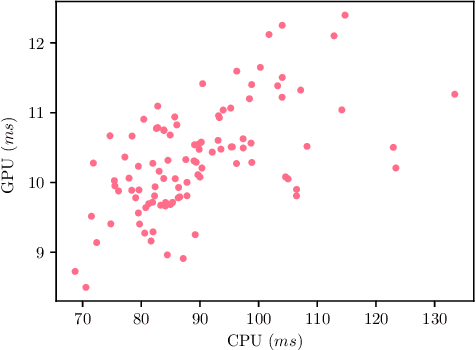
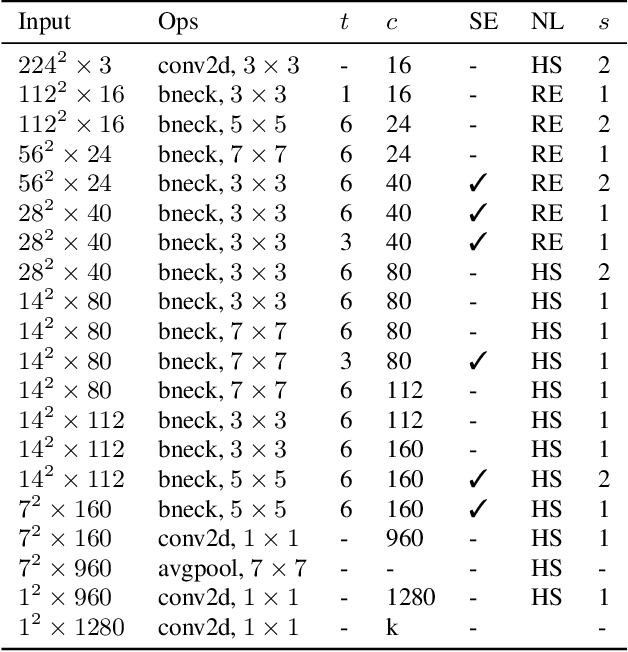
The evolution of MobileNets has laid a solid foundation for neural network applications on mobile end. With the latest MobileNetV3, neural architecture search again claimed its supremacy in network design. Unfortunately, till today all mobile methods mainly focus on CPU latencies instead of GPU, the latter, however, is much preferred in practice for it has faster speed, lower overhead and less interference. Bearing the target hardware in mind, we propose the first Mobile GPU-Aware (MoGA) neural architecture search in order to be precisely tailored for real-world applications. Further, the ultimate objective to devise a mobile network lies in achieving better performance by maximizing the utilization of bounded resources. Urging higher capability while restraining time consumption is not reconcilable. We alleviate the tension by weighted evolution techniques. Moreover, we encourage increasing the number of parameters for higher representational power. With 200x fewer GPU days than MnasNet, we obtain a series of models that outperform MobileNetV3 under the similar latency constraints, i.e., MoGA-A achieves 75.9% top-1 accuracy on ImageNet, MoGA-B meets 75.5% which costs only 0.5 ms more on mobile GPU. MoGA-C best attests GPU-awareness by reaching 75.3% and being slower on CPU but faster on GPU.The models and test code is made available here https://github.com/xiaomi-automl/MoGA.