 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSDM: A Powerful Tool for Evaluating Model Robustness
May 19, 2026Gradient-based attacks are important methods for evaluating model robustness. However, since the proposal of APGD, it has been difficult for such methods to achieve significant breakthroughs. To achieve such an effect, we first analyze the issue of "high-loss non-adversarial examples" that degrades attack performance in previous methods, and prove that this issue arises from inappropriate objectives for adversarial example generation. Subsequently, we reconstruct the objective as "maximizing the difference between the non-ground-truth label probability upper bound and the ground-truth label probability", and proposes a novel and powerful gradient-based attack method named Sequential Difference Maximization (SDM). SDM establishes a three-layer optimization framework of "cycle-stage-step". It adopts the negative probability loss function and the Directional Probability Difference Ratio (DPDR) loss function in the initial and subsequent optimization stages, respectively, and approaches the ideal objective of adversarial example generation via stage-wise sequential optimization. Experiments demonstrate that compared with previous state-of-the-art methods, SDM not only achieves stronger attack performance but also exhibits superior cost-effectiveness. The code is available at https://github.com/X-L-Liu/ICML-SDM.
* 16 pages
3DFill:Reference-guided Image Inpainting by Self-supervised 3D Image Alignment
Nov 09, 2022Most existing image inpainting algorithms are based on a single view, struggling with large holes or the holes containing complicated scenes. Some reference-guided algorithms fill the hole by referring to another viewpoint image and use 2D image alignment. Due to the camera imaging process, simple 2D transformation is difficult to achieve a satisfactory result. In this paper, we propose 3DFill, a simple and efficient method for reference-guided image inpainting. Given a target image with arbitrary hole regions and a reference image from another viewpoint, the 3DFill first aligns the two images by a two-stage method: 3D projection + 2D transformation, which has better results than 2D image alignment. The 3D projection is an overall alignment between images and the 2D transformation is a local alignment focused on the hole region. The entire process of image alignment is self-supervised. We then fill the hole in the target image with the contents of the aligned image. Finally, we use a conditional generation network to refine the filled image to obtain the inpainting result. 3DFill achieves state-of-the-art performance on image inpainting across a variety of wide view shifts and has a faster inference speed than other inpainting models.
Cascade Luminance and Chrominance for Image Retouching: More Like Artist
May 31, 2022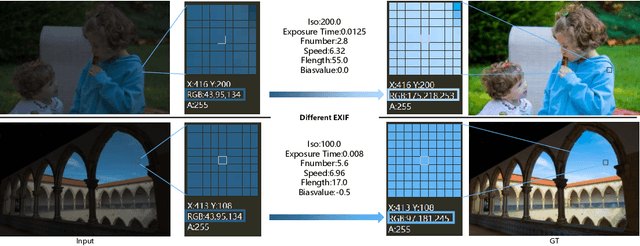

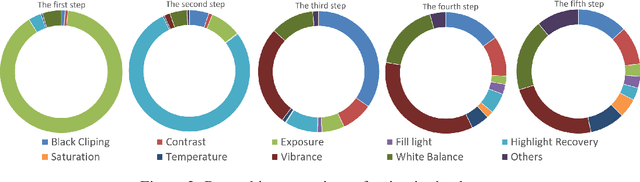

Photo retouching aims to adjust the luminance, contrast, and saturation of the image to make it more human aesthetically desirable. However, artists' actions in photo retouching are difficult to quantitatively analyze. By investigating their retouching behaviors, we propose a two-stage network that brightens images first and then enriches them in the chrominance plane. Six pieces of useful information from image EXIF are picked as the network's condition input. Additionally, hue palette loss is added to make the image more vibrant. Based on the above three aspects, Luminance-Chrominance Cascading Net(LCCNet) makes the machine learning problem of mimicking artists in photo retouching more reasonable. Experiments show that our method is effective on the benchmark MIT-Adobe FiveK dataset, and achieves state-of-the-art performance for both quantitative and qualitative evaluation.
MoCoViT: Mobile Convolutional Vision Transformer
May 26, 2022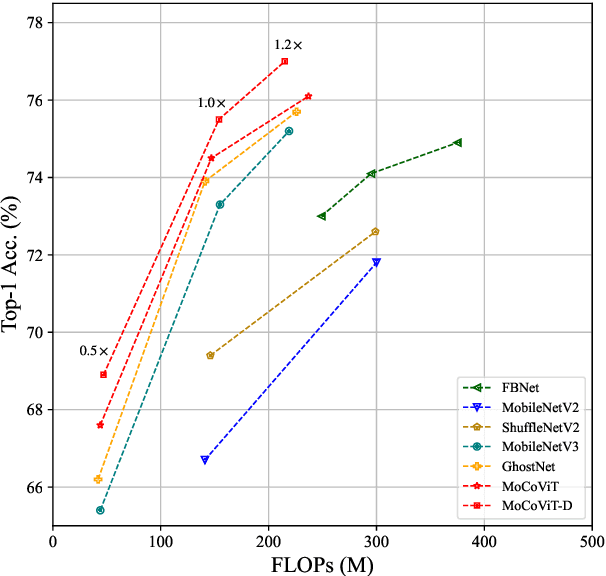
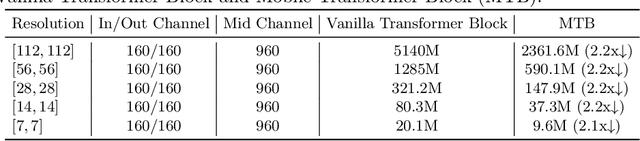
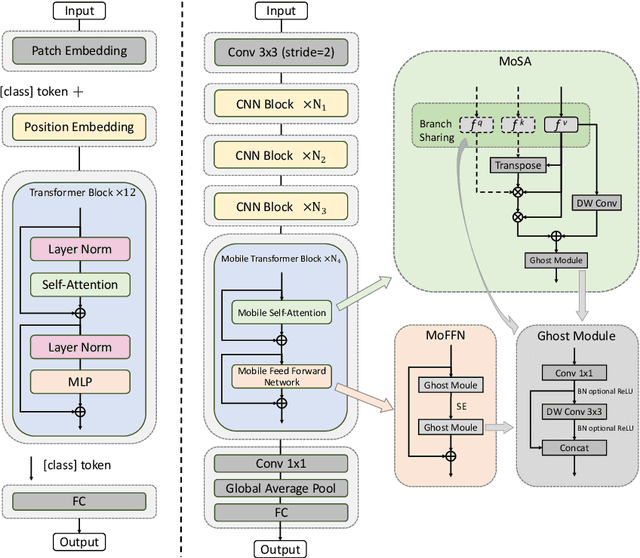
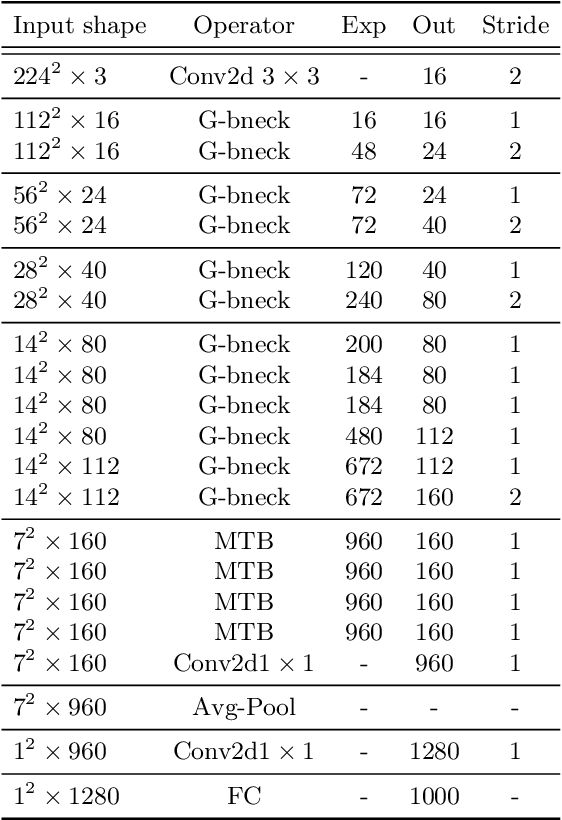
Recently, Transformer networks have achieved impressive results on a variety of vision tasks. However, most of them are computationally expensive and not suitable for real-world mobile applications. In this work, we present Mobile Convolutional Vision Transformer (MoCoViT), which improves in performance and efficiency by introducing transformer into mobile convolutional networks to leverage the benefits of both architectures. Different from recent works on vision transformer, the mobile transformer block in MoCoViT is carefully designed for mobile devices and is very lightweight, accomplished through two primary modifications: the Mobile Self-Attention (MoSA) module and the Mobile Feed Forward Network (MoFFN). MoSA simplifies the calculation of the attention map through Branch Sharing scheme while MoFFN serves as a mobile version of MLP in the transformer, further reducing the computation by a large margin. Comprehensive experiments verify that our proposed MoCoViT family outperform state-of-the-art portable CNNs and transformer neural architectures on various vision tasks. On ImageNet classification, it achieves 74.5% top-1 accuracy at 147M FLOPs, gaining 1.2% over MobileNetV3 with less computations. And on the COCO object detection task, MoCoViT outperforms GhostNet by 2.1 AP in RetinaNet framework.
ScalableViT: Rethinking the Context-oriented Generalization of Vision Transformer
Mar 21, 2022

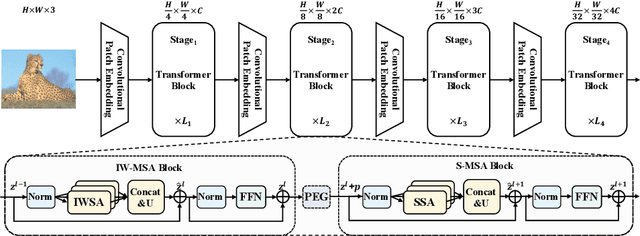
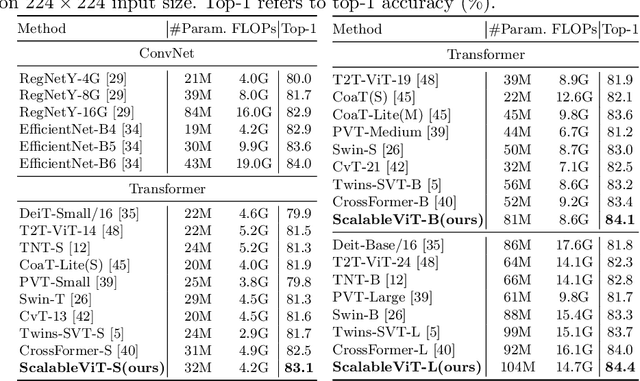
The vanilla self-attention mechanism inherently relies on pre-defined and steadfast computational dimensions. Such inflexibility restricts it from possessing context-oriented generalization that can bring more contextual cues and global representations. To mitigate this issue, we propose a Scalable Self-Attention (SSA) mechanism that leverages two scaling factors to release dimensions of query, key, and value matrix while unbinding them with the input. This scalability fetches context-oriented generalization and enhances object sensitivity, which pushes the whole network into a more effective trade-off state between accuracy and cost. Furthermore, we propose an Interactive Window-based Self-Attention (IWSA), which establishes interaction between non-overlapping regions by re-merging independent value tokens and aggregating spatial information from adjacent windows. By stacking the SSA and IWSA alternately, the Scalable Vision Transformer (ScalableViT) achieves state-of-the-art performance in general-purpose vision tasks. For example, ScalableViT-S outperforms Twins-SVT-S by 1.4% and Swin-T by 1.8% on ImageNet-1K classification.
A Matrix-in-matrix Neural Network for Image Super Resolution
Mar 19, 2019
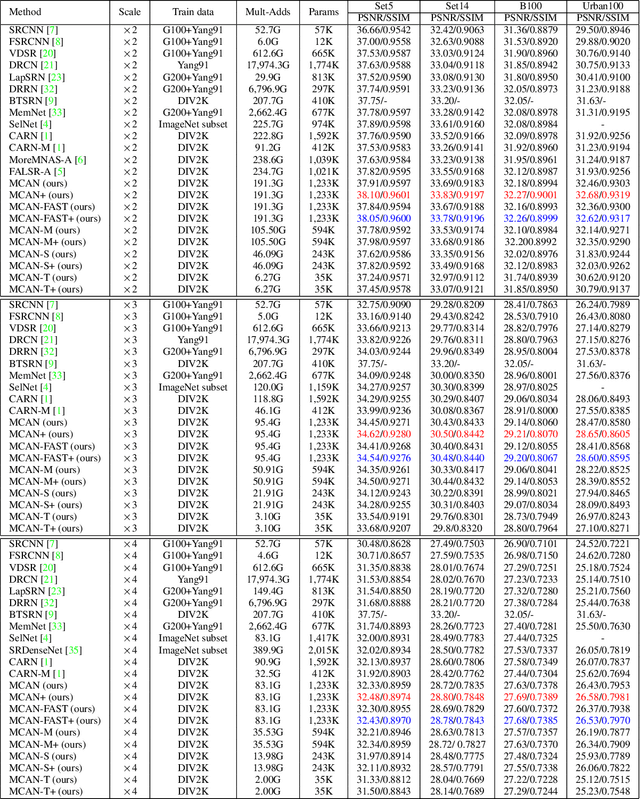
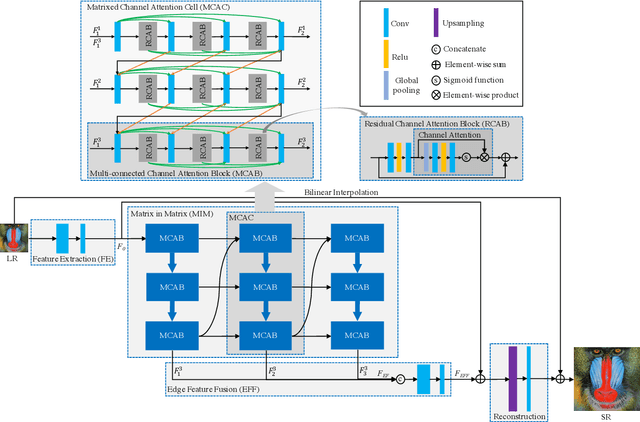
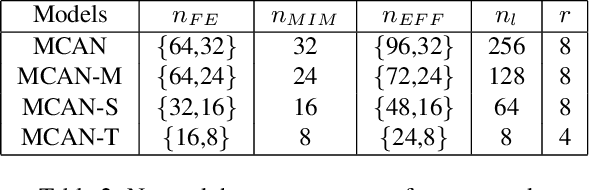
In recent years, deep learning methods have achieved impressive results with higher peak signal-to-noise ratio in single image super-resolution (SISR) tasks by utilizing deeper layers. However, their application is quite limited since they require high computing power. In addition, most of the existing methods rarely take full advantage of the intermediate features which are helpful for restoration. To address these issues, we propose a moderate-size SISR net work named matrixed channel attention network (MCAN) by constructing a matrix ensemble of multi-connected channel attention blocks (MCAB). Several models of different sizes are released to meet various practical requirements. Conclusions can be drawn from our extensive benchmark experiments that the proposed models achieve better performance with much fewer multiply-adds and parameters. Our models will be made publicly available.
Fast, Accurate and Lightweight Super-Resolution with Neural Architecture Search
Jan 24, 2019
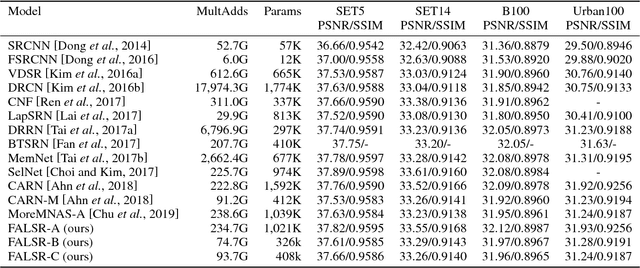

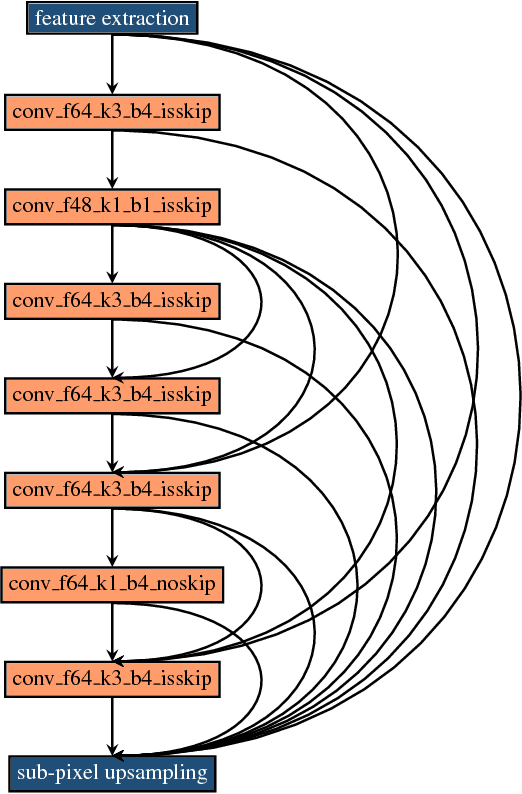
Deep convolution neural networks demonstrate impressive results in the super-resolution domain. A series of studies concentrate on improving peak signal noise ratio (PSNR) by using much deeper layers, which are not friendly to constrained resources. Pursuing a trade-off between the restoration capacity and the simplicity of models is still non-trivial. Recent contributions are struggling to manually maximize this balance, while our work achieves the same goal automatically with neural architecture search. Specifically, we handle super-resolution with a multi-objective approach. We also propose an elastic search tactic at both micro and macro level, based on a hybrid controller that profits from evolutionary computation and reinforcement learning. Quantitative experiments help us to draw a conclusion that our generated models dominate most of the state-of-the-art methods with respect to the individual FLOPS.
Multi-Objective Reinforced Evolution in Mobile Neural Architecture Search
Jan 16, 2019

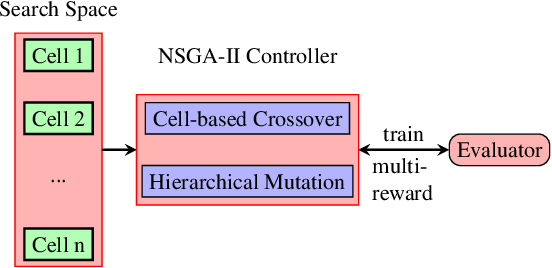
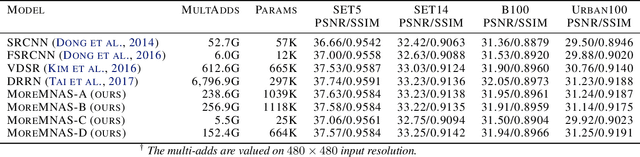
Fabricating neural models for a wide range of mobile devices demands for a specific design of networks due to highly constrained resources. Both evolution algorithms (EA) and reinforced learning methods (RL) have been dedicated to solve neural architecture search problems. However, these combinations usually concentrate on a single objective such as the error rate of image classification. They also fail to harness the very benefits from both sides. In this paper, we present a new multi-objective oriented algorithm called MoreMNAS (Multi-Objective Reinforced Evolution in Mobile Neural Architecture Search) by leveraging good virtues from both EA and RL. In particular, we incorporate a variant of multi-objective genetic algorithm NSGA-II, in which the search space is composed of various cells so that crossovers and mutations can be performed at the cell level. Moreover, reinforced control is mixed with a natural mutating process to regulate arbitrary mutation, maintaining a delicate balance between exploration and exploitation. Therefore, not only does our method prevent the searched models from degrading during the evolution process, but it also makes better use of learned knowledge. Our experiments conducted in Super-resolution domain (SR) deliver rivalling models compared to some state-of-the-art methods with fewer FLOPS.