 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHierarchy of extreme-event predictability in turbulence revealed by machine learning
Mar 14, 2026Extreme-event predictability in turbulence is strongly state dependent, yet event-by-event predictability horizons are difficult to quantify without access to governing equations or costly perturbation ensembles. Here we train an autoregressive conditional diffusion model on direct numerical simulations of the two-dimensional Kolmogorov flow and use a CRPS-based skill score to define an event-wise predictability horizon. Enstrophy extremes exhibit a pronounced hierarchy: forecast skill persists from $\approx 1$ to $> 4$ Lyapunov times across events. Spectral filtering shows that these horizons are controlled predominantly by large-scale structures. Extremes are preceded by intense strain cores organizing quadrupolar vortex packets, whose lifetime sharply separates long- from short-horizon events. These results identify coherent-structure persistence as a governing mechanism for the predictability of turbulence extremes and provide a data-driven route to diagnose predictability limits from observations.
XAI4Extremes: An interpretable machine learning framework for understanding extreme-weather precursors under climate change
Mar 11, 2025Extreme weather events are increasing in frequency and intensity due to climate change. This, in turn, is exacting a significant toll in communities worldwide. While prediction skills are increasing with advances in numerical weather prediction and artificial intelligence tools, extreme weather still present challenges. More specifically, identifying the precursors of such extreme weather events and how these precursors may evolve under climate change remain unclear. In this paper, we propose to use post-hoc interpretability methods to construct relevance weather maps that show the key extreme-weather precursors identified by deep learning models. We then compare this machine view with existing domain knowledge to understand whether deep learning models identified patterns in data that may enrich our understanding of extreme-weather precursors. We finally bin these relevant maps into different multi-year time periods to understand the role that climate change is having on these precursors. The experiments are carried out on Indochina heatwaves, but the methodology can be readily extended to other extreme weather events worldwide.
O-Mamba: O-shape State-Space Model for Underwater Image Enhancement
Aug 23, 2024
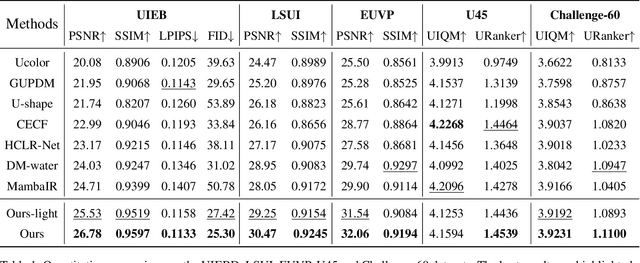
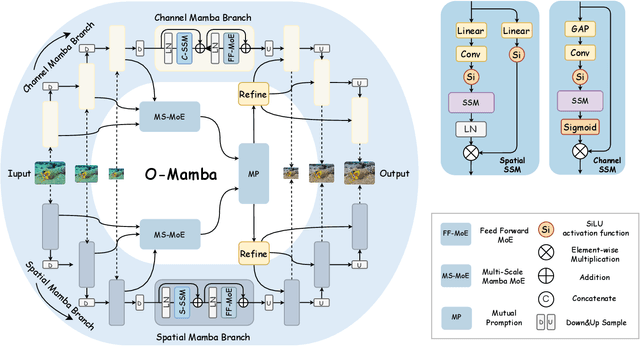
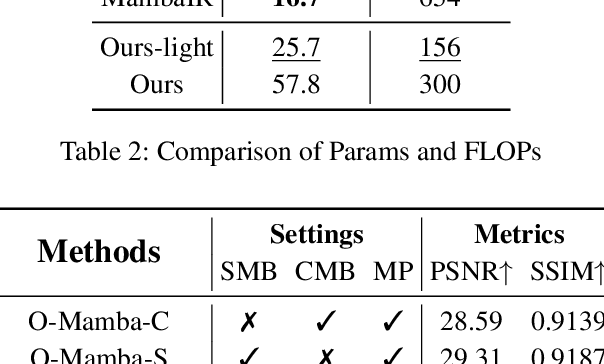
Underwater image enhancement (UIE) face significant challenges due to complex underwater lighting conditions. Recently, mamba-based methods have achieved promising results in image enhancement tasks. However, these methods commonly rely on Vmamba, which focuses only on spatial information modeling and struggles to deal with the cross-color channel dependency problem in underwater images caused by the differential attenuation of light wavelengths, limiting the effective use of deep networks. In this paper, we propose a novel UIE framework called O-mamba. O-mamba employs an O-shaped dual-branch network to separately model spatial and cross-channel information, utilizing the efficient global receptive field of state-space models optimized for underwater images. To enhance information interaction between the two branches and effectively utilize multi-scale information, we design a Multi-scale Bi-mutual Promotion Module. This branch includes MS-MoE for fusing multi-scale information within branches, Mutual Promotion module for interaction between spatial and channel information across branches, and Cyclic Multi-scale optimization strategy to maximize the use of multi-scale information. Extensive experiments demonstrate that our method achieves state-of-the-art (SOTA) results.The code is available at https://github.com/chenydong/O-Mamba.
Semantic-guided Adversarial Diffusion Model for Self-supervised Shadow Removal
Jul 01, 2024



Existing unsupervised methods have addressed the challenges of inconsistent paired data and tedious acquisition of ground-truth labels in shadow removal tasks. However, GAN-based training often faces issues such as mode collapse and unstable optimization. Furthermore, due to the complex mapping between shadow and shadow-free domains, merely relying on adversarial learning is not enough to capture the underlying relationship between two domains, resulting in low quality of the generated images. To address these problems, we propose a semantic-guided adversarial diffusion framework for self-supervised shadow removal, which consists of two stages. At first stage a semantic-guided generative adversarial network (SG-GAN) is proposed to carry out a coarse result and construct paired synthetic data through a cycle-consistent structure. Then the coarse result is refined with a diffusion-based restoration module (DBRM) to enhance the texture details and edge artifact at second stage. Meanwhile, we propose a multi-modal semantic prompter (MSP) that aids in extracting accurate semantic information from real images and text, guiding the shadow removal network to restore images better in SG-GAN. We conduct experiments on multiple public datasets, and the experimental results demonstrate the effectiveness of our method.
Learning A Physical-aware Diffusion Model Based on Transformer for Underwater Image Enhancement
Mar 03, 2024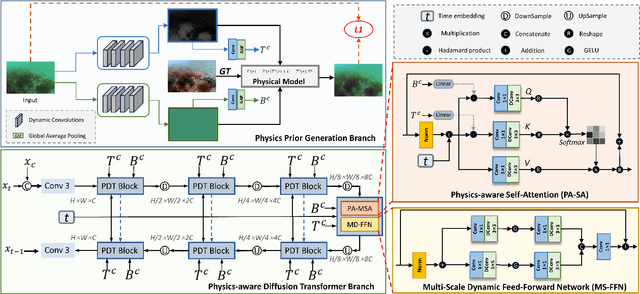

Underwater visuals undergo various complex degradations, inevitably influencing the efficiency of underwater vision tasks. Recently, diffusion models were employed to underwater image enhancement (UIE) tasks, and gained SOTA performance. However, these methods fail to consider the physical properties and underwater imaging mechanisms in the diffusion process, limiting information completion capacity of diffusion models. In this paper, we introduce a novel UIE framework, named PA-Diff, designed to exploiting the knowledge of physics to guide the diffusion process. PA-Diff consists of Physics Prior Generation (PPG) Branch and Physics-aware Diffusion Transformer (PDT) Branch. Our designed PPG branch is a plug-and-play network to produce the physics prior, which can be integrated into any deep framework. With utilizing the physics prior knowledge to guide the diffusion process, PDT branch can obtain underwater-aware ability and model the complex distribution in real-world underwater scenes. Extensive experiments prove that our method achieves best performance on UIE tasks.
Wavelet-based Fourier Information Interaction with Frequency Diffusion Adjustment for Underwater Image Restoration
Nov 28, 2023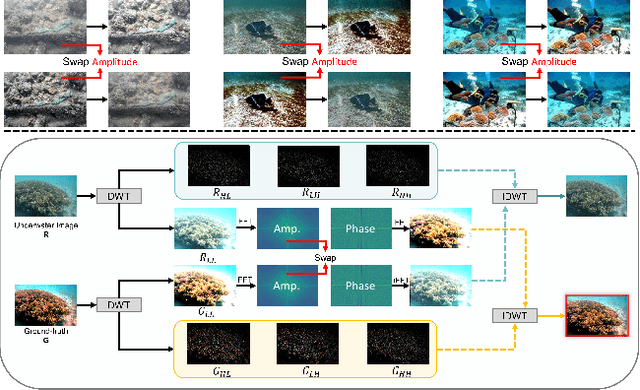
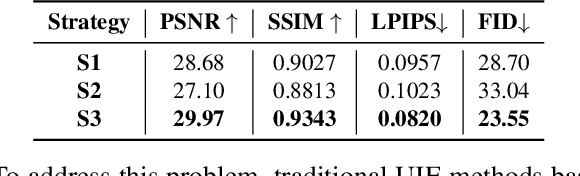
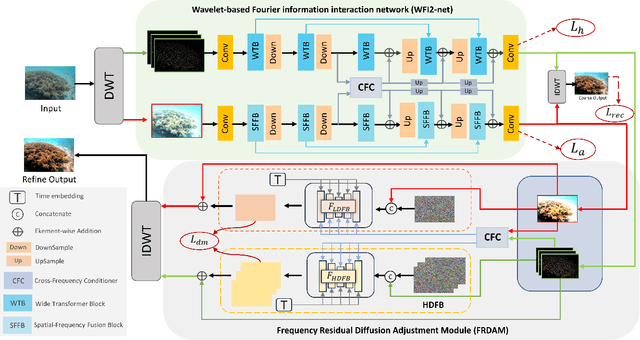
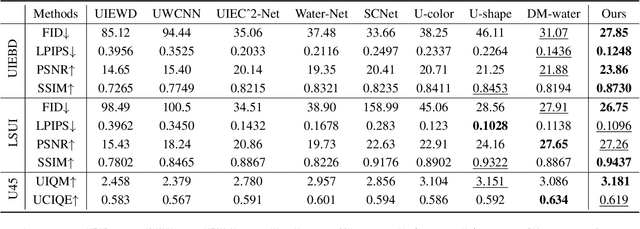
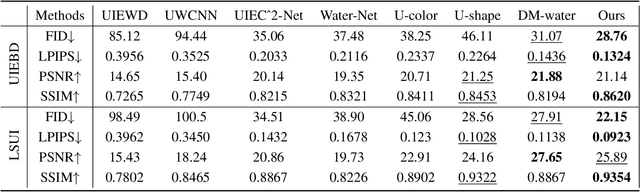
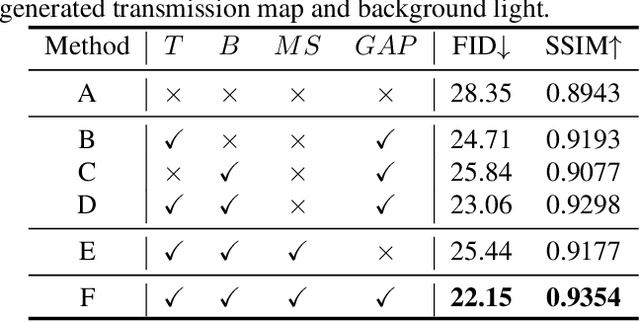
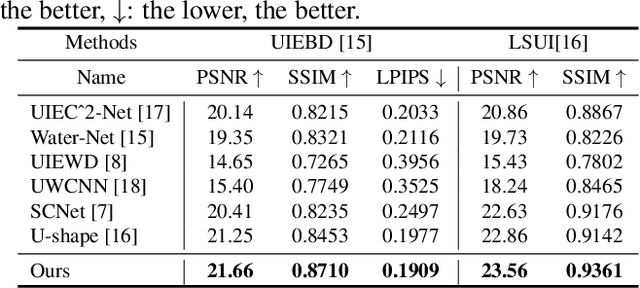
Underwater images are subject to intricate and diverse degradation, inevitably affecting the effectiveness of underwater visual tasks. However, most approaches primarily operate in the raw pixel space of images, which limits the exploration of the frequency characteristics of underwater images, leading to an inadequate utilization of deep models' representational capabilities in producing high-quality images. In this paper, we introduce a novel Underwater Image Enhancement (UIE) framework, named WF-Diff, designed to fully leverage the characteristics of frequency domain information and diffusion models. WF-Diff consists of two detachable networks: Wavelet-based Fourier information interaction network (WFI2-net) and Frequency Residual Diffusion Adjustment Module (FRDAM). With our full exploration of the frequency domain information, WFI2-net aims to achieve preliminary enhancement of frequency information in the wavelet space. Our proposed FRDAM can further refine the high- and low-frequency information of the initial enhanced images, which can be viewed as a plug-and-play universal module to adjust the detail of the underwater images. With the above techniques, our algorithm can show SOTA performance on real-world underwater image datasets, and achieves competitive performance in visual quality.
Toward Sufficient Spatial-Frequency Interaction for Gradient-aware Underwater Image Enhancement
Sep 08, 2023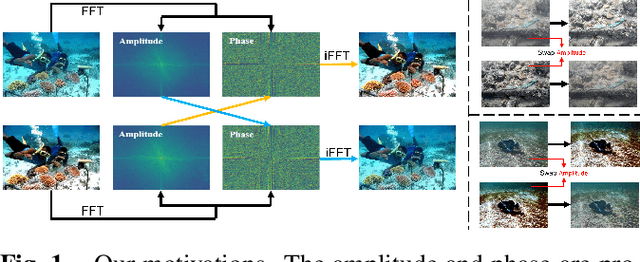
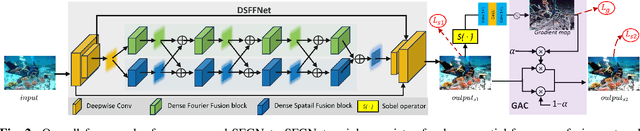
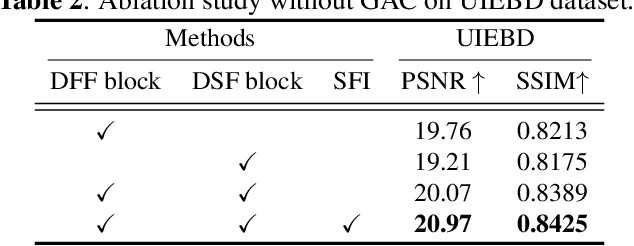
Underwater images suffer from complex and diverse degradation, which inevitably affects the performance of underwater visual tasks. However, most existing learning-based Underwater image enhancement (UIE) methods mainly restore such degradations in the spatial domain, and rarely pay attention to the fourier frequency information. In this paper, we develop a novel UIE framework based on spatial-frequency interaction and gradient maps, namely SFGNet, which consists of two stages. Specifically, in the first stage, we propose a dense spatial-frequency fusion network (DSFFNet), mainly including our designed dense fourier fusion block and dense spatial fusion block, achieving sufficient spatial-frequency interaction by cross connections between these two blocks. In the second stage, we propose a gradient-aware corrector (GAC) to further enhance perceptual details and geometric structures of images by gradient map. Experimental results on two real-world underwater image datasets show that our approach can successfully enhance underwater images, and achieves competitive performance in visual quality improvement.
Super-Resolution by Predicting Offsets: An Ultra-Efficient Super-Resolution Network for Rasterized Images
Oct 09, 2022
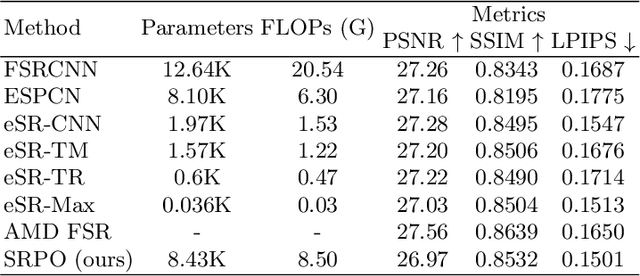
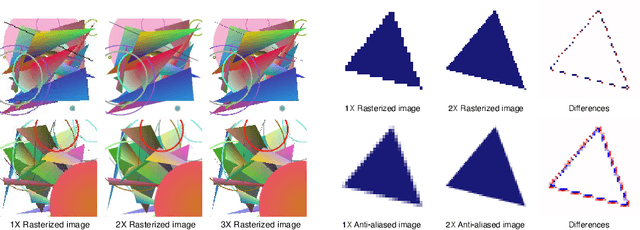
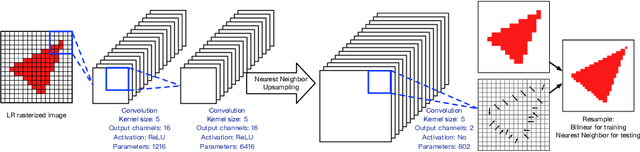
Rendering high-resolution (HR) graphics brings substantial computational costs. Efficient graphics super-resolution (SR) methods may achieve HR rendering with small computing resources and have attracted extensive research interests in industry and research communities. We present a new method for real-time SR for computer graphics, namely Super-Resolution by Predicting Offsets (SRPO). Our algorithm divides the image into two parts for processing, i.e., sharp edges and flatter areas. For edges, different from the previous SR methods that take the anti-aliased images as inputs, our proposed SRPO takes advantage of the characteristics of rasterized images to conduct SR on the rasterized images. To complement the residual between HR and low-resolution (LR) rasterized images, we train an ultra-efficient network to predict the offset maps to move the appropriate surrounding pixels to the new positions. For flat areas, we found simple interpolation methods can already generate reasonable output. We finally use a guided fusion operation to integrate the sharp edges generated by the network and flat areas by the interpolation method to get the final SR image. The proposed network only contains 8,434 parameters and can be accelerated by network quantization. Extensive experiments show that the proposed SRPO can achieve superior visual effects at a smaller computational cost than the existing state-of-the-art methods.
Cascade Luminance and Chrominance for Image Retouching: More Like Artist
May 31, 2022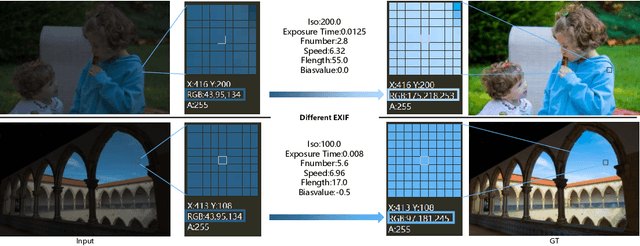

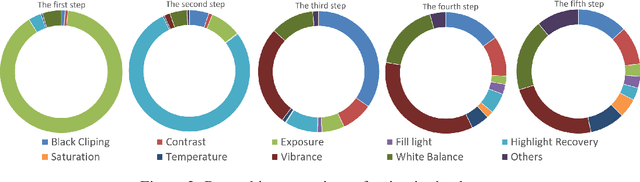

Photo retouching aims to adjust the luminance, contrast, and saturation of the image to make it more human aesthetically desirable. However, artists' actions in photo retouching are difficult to quantitatively analyze. By investigating their retouching behaviors, we propose a two-stage network that brightens images first and then enriches them in the chrominance plane. Six pieces of useful information from image EXIF are picked as the network's condition input. Additionally, hue palette loss is added to make the image more vibrant. Based on the above three aspects, Luminance-Chrominance Cascading Net(LCCNet) makes the machine learning problem of mimicking artists in photo retouching more reasonable. Experiments show that our method is effective on the benchmark MIT-Adobe FiveK dataset, and achieves state-of-the-art performance for both quantitative and qualitative evaluation.