 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGLM-5: from Vibe Coding to Agentic Engineering
Feb 17, 2026We present GLM-5, a next-generation foundation model designed to transition the paradigm of vibe coding to agentic engineering. Building upon the agentic, reasoning, and coding (ARC) capabilities of its predecessor, GLM-5 adopts DSA to significantly reduce training and inference costs while maintaining long-context fidelity. To advance model alignment and autonomy, we implement a new asynchronous reinforcement learning infrastructure that drastically improves post-training efficiency by decoupling generation from training. Furthermore, we propose novel asynchronous agent RL algorithms that further improve RL quality, enabling the model to learn from complex, long-horizon interactions more effectively. Through these innovations, GLM-5 achieves state-of-the-art performance on major open benchmarks. Most critically, GLM-5 demonstrates unprecedented capability in real-world coding tasks, surpassing previous baselines in handling end-to-end software engineering challenges. Code, models, and more information are available at https://github.com/zai-org/GLM-5.
ChineseEcomQA: A Scalable E-commerce Concept Evaluation Benchmark for Large Language Models
Feb 27, 2025
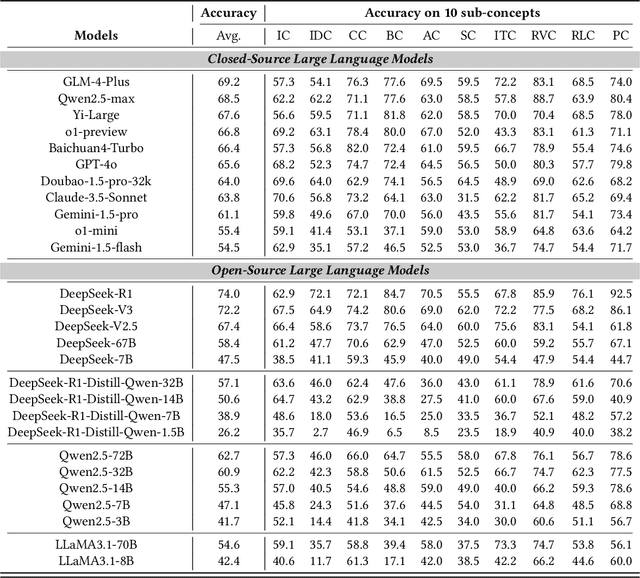
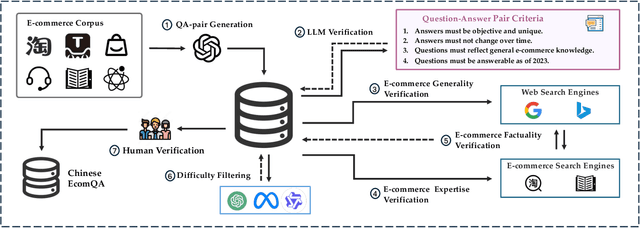

With the increasing use of Large Language Models (LLMs) in fields such as e-commerce, domain-specific concept evaluation benchmarks are crucial for assessing their domain capabilities. Existing LLMs may generate factually incorrect information within the complex e-commerce applications. Therefore, it is necessary to build an e-commerce concept benchmark. Existing benchmarks encounter two primary challenges: (1) handle the heterogeneous and diverse nature of tasks, (2) distinguish between generality and specificity within the e-commerce field. To address these problems, we propose \textbf{ChineseEcomQA}, a scalable question-answering benchmark focused on fundamental e-commerce concepts. ChineseEcomQA is built on three core characteristics: \textbf{Focus on Fundamental Concept}, \textbf{E-commerce Generality} and \textbf{E-commerce Expertise}. Fundamental concepts are designed to be applicable across a diverse array of e-commerce tasks, thus addressing the challenge of heterogeneity and diversity. Additionally, by carefully balancing generality and specificity, ChineseEcomQA effectively differentiates between broad e-commerce concepts, allowing for precise validation of domain capabilities. We achieve this through a scalable benchmark construction process that combines LLM validation, Retrieval-Augmented Generation (RAG) validation, and rigorous manual annotation. Based on ChineseEcomQA, we conduct extensive evaluations on mainstream LLMs and provide some valuable insights. We hope that ChineseEcomQA could guide future domain-specific evaluations, and facilitate broader LLM adoption in e-commerce applications.
AIR: Complex Instruction Generation via Automatic Iterative Refinement
Feb 25, 2025



With the development of large language models, their ability to follow simple instructions has significantly improved. However, adhering to complex instructions remains a major challenge. Current approaches to generating complex instructions are often irrelevant to the current instruction requirements or suffer from limited scalability and diversity. Moreover, methods such as back-translation, while effective for simple instruction generation, fail to leverage the rich contents and structures in large web corpora. In this paper, we propose a novel automatic iterative refinement framework to generate complex instructions with constraints, which not only better reflects the requirements of real scenarios but also significantly enhances LLMs' ability to follow complex instructions. The AIR framework consists of two stages: (1)Generate an initial instruction from a document; (2)Iteratively refine instructions with LLM-as-judge guidance by comparing the model's output with the document to incorporate valuable constraints. Finally, we construct the AIR-10K dataset with 10K complex instructions and demonstrate that instructions generated with our approach significantly improve the model's ability to follow complex instructions, outperforming existing methods for instruction generation.
Mitigating Out-of-Entity Errors in Named Entity Recognition: A Sentence-Level Strategy
Dec 11, 2024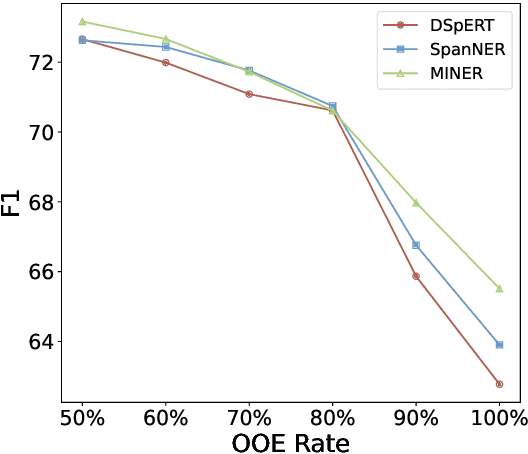
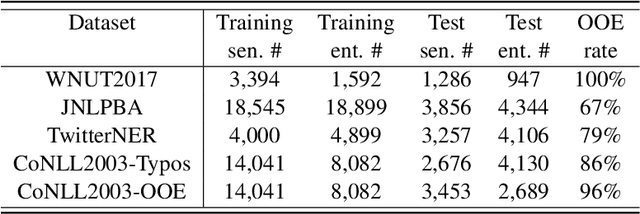
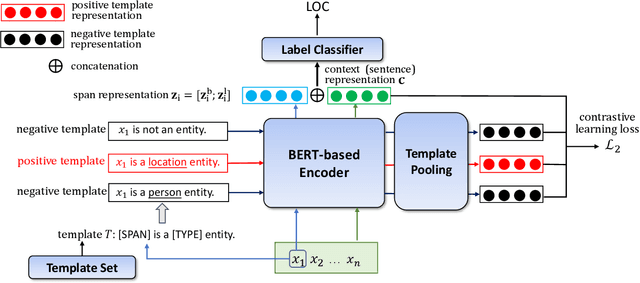
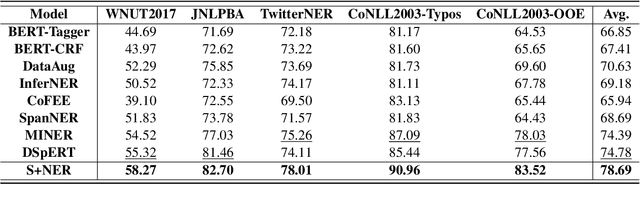
Many previous models of named entity recognition (NER) suffer from the problem of Out-of-Entity (OOE), i.e., the tokens in the entity mentions of the test samples have not appeared in the training samples, which hinders the achievement of satisfactory performance. To improve OOE-NER performance, in this paper, we propose a new framework, namely S+NER, which fully leverages sentence-level information. Our S+NER achieves better OOE-NER performance mainly due to the following two particular designs. 1) It first exploits the pre-trained language model's capability of understanding the target entity's sentence-level context with a template set. 2) Then, it refines the sentence-level representation based on the positive and negative templates, through a contrastive learning strategy and template pooling method, to obtain better NER results. Our extensive experiments on five benchmark datasets have demonstrated that, our S+NER outperforms some state-of-the-art OOE-NER models.
WiS Platform: Enhancing Evaluation of LLM-Based Multi-Agent Systems Through Game-Based Analysis
Dec 04, 2024

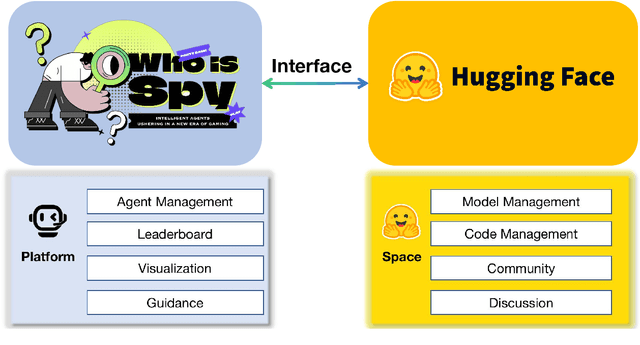
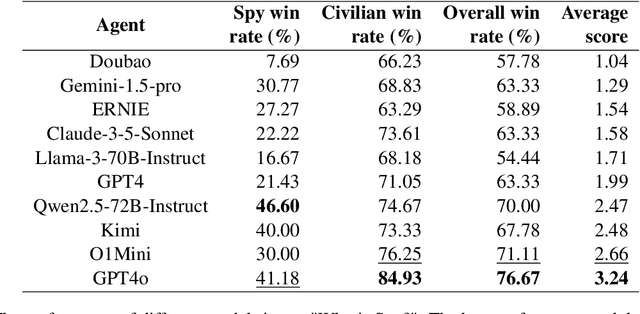
Recent advancements in autonomous multi-agent systems (MAS) based on large language models (LLMs) have enhanced the application scenarios and improved the capability of LLMs to handle complex tasks. Despite demonstrating effectiveness, existing studies still evidently struggle to evaluate, analysis, and reproducibility of LLM-based MAS. In this paper, to facilitate the research on LLM-based MAS, we introduce an open, scalable, and real-time updated platform for accessing and analyzing the LLM-based MAS based on the games Who is Spy?" (WiS). Our platform is featured with three main worths: (1) a unified model evaluate interface that supports models available on Hugging Face; (2) real-time updated leaderboard for model evaluation; (3) a comprehensive evaluation covering game-winning rates, attacking, defense strategies, and reasoning of LLMs. To rigorously test WiS, we conduct extensive experiments coverage of various open- and closed-source LLMs, we find that different agents exhibit distinct and intriguing behaviors in the game. The experimental results demonstrate the effectiveness and efficiency of our platform in evaluating LLM-based MAS. Our platform and its documentation are publicly available at \url{https://whoisspy.ai/}
Chinese SimpleQA: A Chinese Factuality Evaluation for Large Language Models
Nov 13, 2024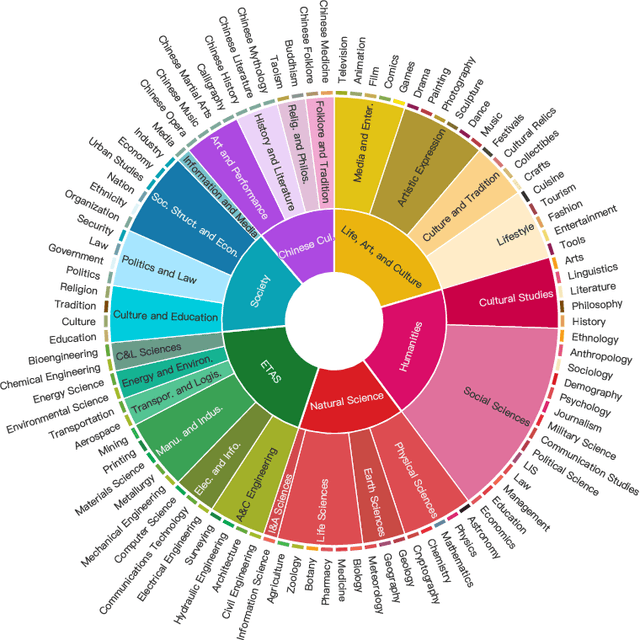


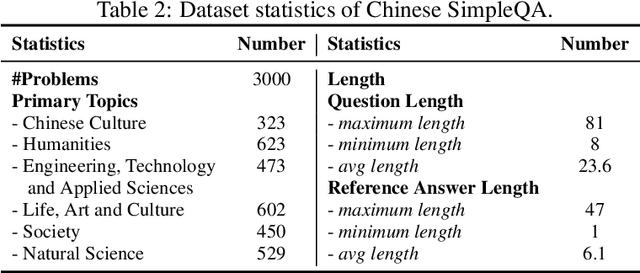
New LLM evaluation benchmarks are important to align with the rapid development of Large Language Models (LLMs). In this work, we present Chinese SimpleQA, the first comprehensive Chinese benchmark to evaluate the factuality ability of language models to answer short questions, and Chinese SimpleQA mainly has five properties (i.e., Chinese, Diverse, High-quality, Static, Easy-to-evaluate). Specifically, first, we focus on the Chinese language over 6 major topics with 99 diverse subtopics. Second, we conduct a comprehensive quality control process to achieve high-quality questions and answers, where the reference answers are static and cannot be changed over time. Third, following SimpleQA, the questions and answers are very short, and the grading process is easy-to-evaluate based on OpenAI API. Based on Chinese SimpleQA, we perform a comprehensive evaluation on the factuality abilities of existing LLMs. Finally, we hope that Chinese SimpleQA could guide the developers to better understand the Chinese factuality abilities of their models and facilitate the growth of foundation models.
Wavelet-based Fourier Information Interaction with Frequency Diffusion Adjustment for Underwater Image Restoration
Nov 28, 2023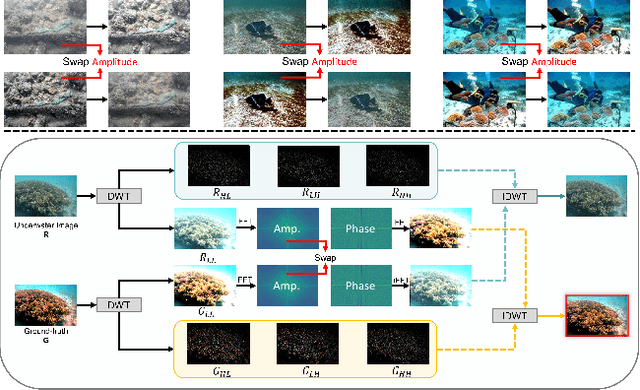
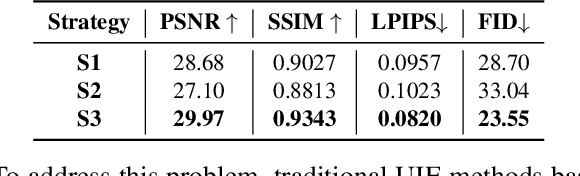
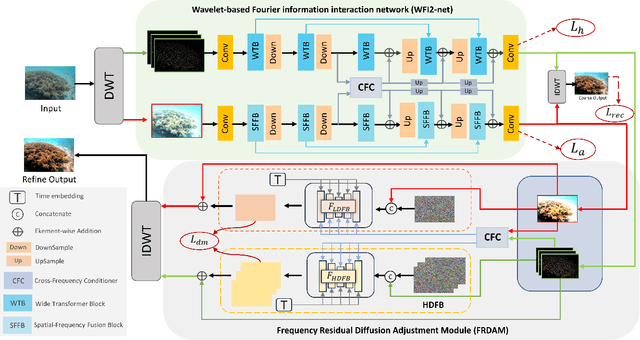
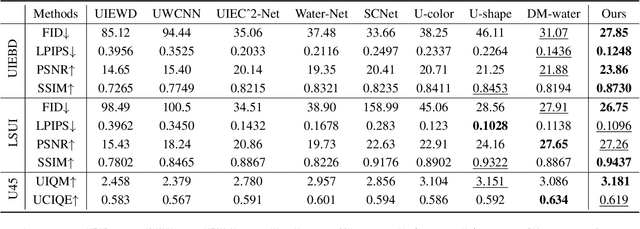
Underwater images are subject to intricate and diverse degradation, inevitably affecting the effectiveness of underwater visual tasks. However, most approaches primarily operate in the raw pixel space of images, which limits the exploration of the frequency characteristics of underwater images, leading to an inadequate utilization of deep models' representational capabilities in producing high-quality images. In this paper, we introduce a novel Underwater Image Enhancement (UIE) framework, named WF-Diff, designed to fully leverage the characteristics of frequency domain information and diffusion models. WF-Diff consists of two detachable networks: Wavelet-based Fourier information interaction network (WFI2-net) and Frequency Residual Diffusion Adjustment Module (FRDAM). With our full exploration of the frequency domain information, WFI2-net aims to achieve preliminary enhancement of frequency information in the wavelet space. Our proposed FRDAM can further refine the high- and low-frequency information of the initial enhanced images, which can be viewed as a plug-and-play universal module to adjust the detail of the underwater images. With the above techniques, our algorithm can show SOTA performance on real-world underwater image datasets, and achieves competitive performance in visual quality.
Improving Continual Relation Extraction through Prototypical Contrastive Learning
Oct 10, 2022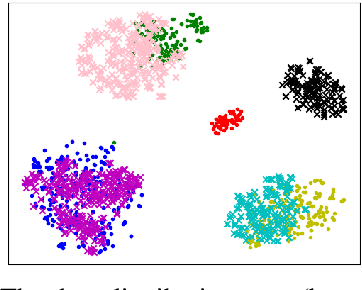
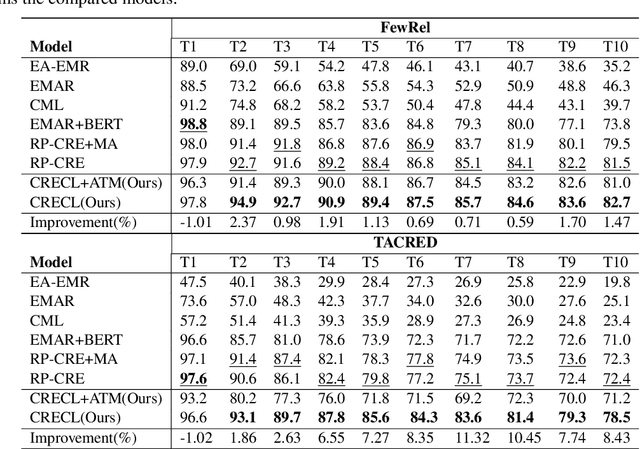
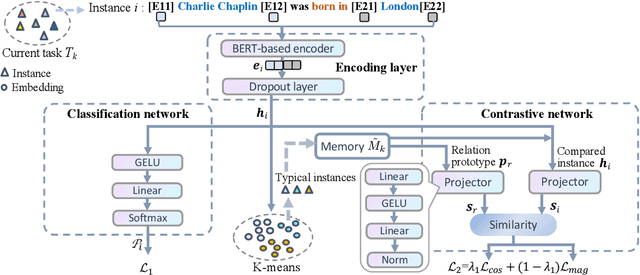
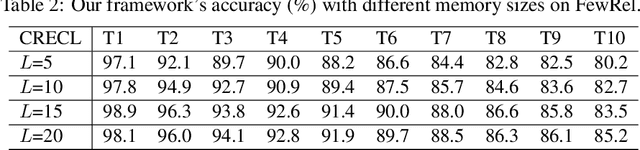
Continual relation extraction (CRE) aims to extract relations towards the continuous and iterative arrival of new data, of which the major challenge is the catastrophic forgetting of old tasks. In order to alleviate this critical problem for enhanced CRE performance, we propose a novel Continual Relation Extraction framework with Contrastive Learning, namely CRECL, which is built with a classification network and a prototypical contrastive network to achieve the incremental-class learning of CRE. Specifically, in the contrastive network a given instance is contrasted with the prototype of each candidate relations stored in the memory module. Such contrastive learning scheme ensures the data distributions of all tasks more distinguishable, so as to alleviate the catastrophic forgetting further. Our experiment results not only demonstrate our CRECL's advantage over the state-of-the-art baselines on two public datasets, but also verify the effectiveness of CRECL's contrastive learning on improving CRE performance.