 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFlashThink: An Early Exit Method For Efficient Reasoning
May 20, 2025Large Language Models (LLMs) have shown impressive performance in reasoning tasks. However, LLMs tend to generate excessively long reasoning content, leading to significant computational overhead. Our observations indicate that even on simple problems, LLMs tend to produce unnecessarily lengthy reasoning content, which is against intuitive expectations. Preliminary experiments show that at a certain point during the generation process, the model is already capable of producing the correct solution without completing the full reasoning content. Therefore, we consider that the reasoning process of the model can be exited early to achieve the purpose of efficient reasoning. We introduce a verification model that identifies the exact moment when the model can stop reasoning and still provide the correct answer. Comprehensive experiments on four different benchmarks demonstrate that our proposed method, FlashThink, effectively shortens the reasoning content while preserving the model accuracy. For the Deepseek-R1 and QwQ-32B models, we reduced the length of reasoning content by 77.04% and 77.47%, respectively, without reducing the accuracy.
RLAP: A Reinforcement Learning Enhanced Adaptive Planning Framework for Multi-step NLP Task Solving
May 17, 2025Multi-step planning has been widely employed to enhance the performance of large language models (LLMs) on downstream natural language processing (NLP) tasks, which decomposes the original task into multiple subtasks and guide LLMs to solve them sequentially without additional training. When addressing task instances, existing methods either preset the order of steps or attempt multiple paths at each step. However, these methods overlook instances' linguistic features and rely on the intrinsic planning capabilities of LLMs to evaluate intermediate feedback and then select subtasks, resulting in suboptimal outcomes. To better solve multi-step NLP tasks with LLMs, in this paper we propose a Reinforcement Learning enhanced Adaptive Planning framework (RLAP). In our framework, we model an NLP task as a Markov decision process (MDP) and employ an LLM directly into the environment. In particular, a lightweight Actor model is trained to estimate Q-values for natural language sequences consisting of states and actions through reinforcement learning. Therefore, during sequential planning, the linguistic features of each sequence in the MDP can be taken into account, and the Actor model interacts with the LLM to determine the optimal order of subtasks for each task instance. We apply RLAP on three different types of NLP tasks and conduct extensive experiments on multiple datasets to verify RLAP's effectiveness and robustness.
Mitigating Out-of-Entity Errors in Named Entity Recognition: A Sentence-Level Strategy
Dec 11, 2024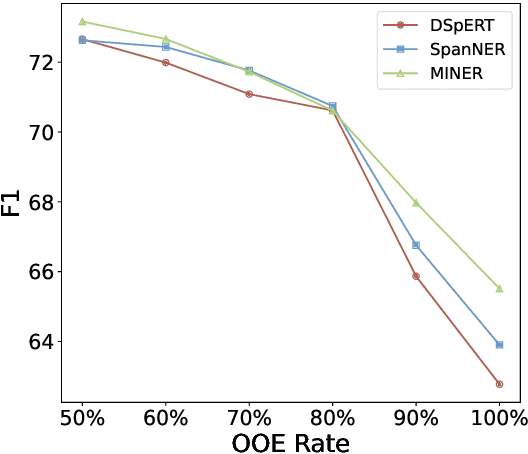
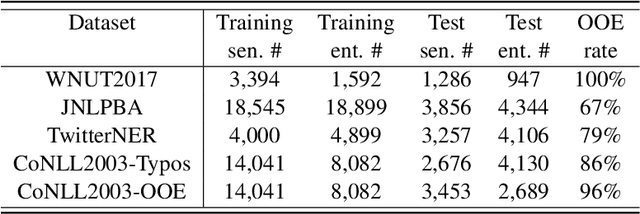
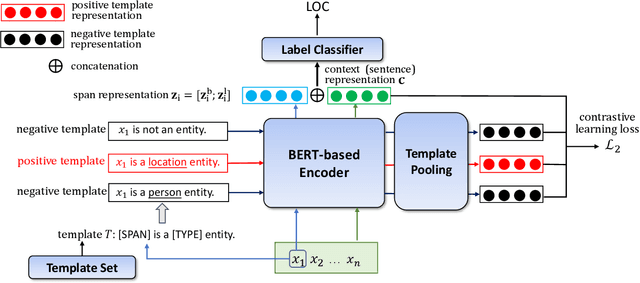
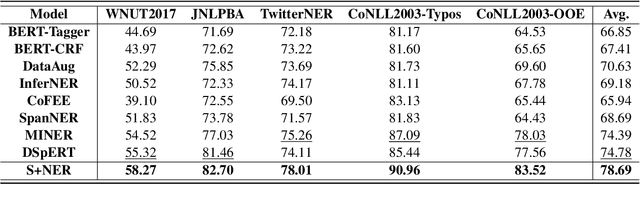
Many previous models of named entity recognition (NER) suffer from the problem of Out-of-Entity (OOE), i.e., the tokens in the entity mentions of the test samples have not appeared in the training samples, which hinders the achievement of satisfactory performance. To improve OOE-NER performance, in this paper, we propose a new framework, namely S+NER, which fully leverages sentence-level information. Our S+NER achieves better OOE-NER performance mainly due to the following two particular designs. 1) It first exploits the pre-trained language model's capability of understanding the target entity's sentence-level context with a template set. 2) Then, it refines the sentence-level representation based on the positive and negative templates, through a contrastive learning strategy and template pooling method, to obtain better NER results. Our extensive experiments on five benchmark datasets have demonstrated that, our S+NER outperforms some state-of-the-art OOE-NER models.
Adaptive Reinforcement Learning Planning: Harnessing Large Language Models for Complex Information Extraction
Jun 17, 2024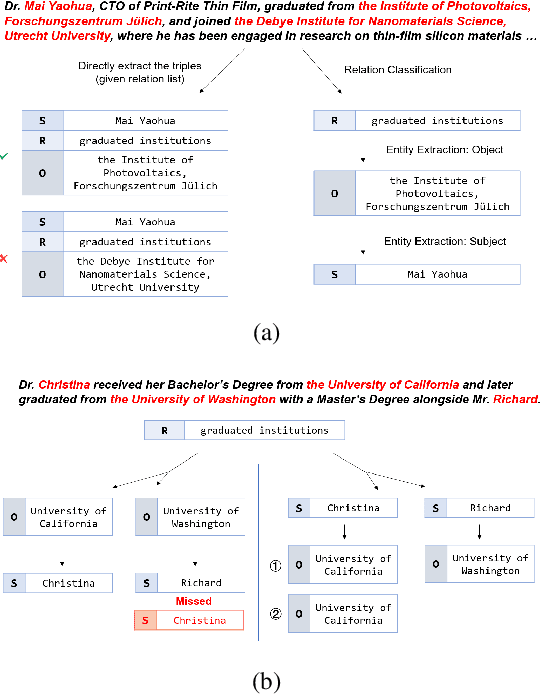
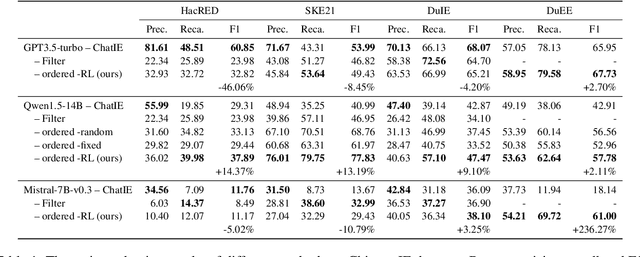
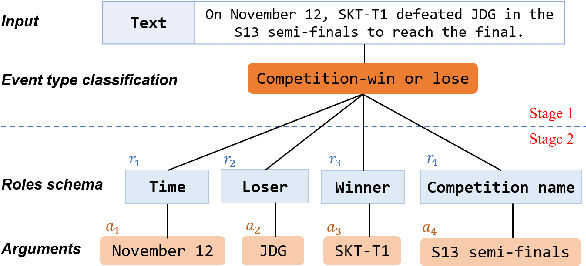
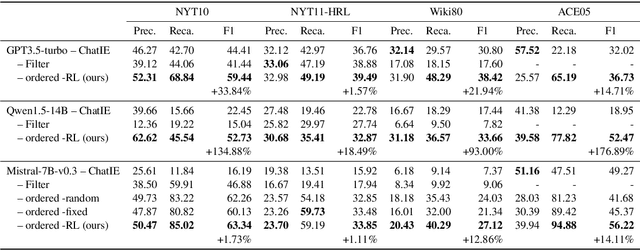
Existing research on large language models (LLMs) shows that they can solve information extraction tasks through multi-step planning. However, their extraction behavior on complex sentences and tasks is unstable, emerging issues such as false positives and missing elements. We observe that decomposing complex extraction tasks and extracting them step by step can effectively improve LLMs' performance, and the extraction orders of entities significantly affect the final results of LLMs. This paper proposes a two-stage multi-step method for LLM-based information extraction and adopts the RL framework to execute the multi-step planning. We regard sequential extraction as a Markov decision process, build an LLM-based extraction environment, design a decision module to adaptively provide the optimal order for sequential entity extraction on different sentences, and utilize the DDQN algorithm to train the decision model. We also design the rewards and evaluation metrics suitable for the extraction results of LLMs. We conduct extensive experiments on multiple public datasets to demonstrate the effectiveness of our method in improving the information extraction capabilities of LLMs.
Tokenization Matters! Degrading Large Language Models through Challenging Their Tokenization
May 27, 2024Large Language Models (LLMs) have shown remarkable capabilities in language understanding and generation. Nonetheless, it was also witnessed that LLMs tend to produce inaccurate responses to specific queries. This deficiency can be traced to the tokenization step LLMs must undergo, which is an inevitable limitation inherent to all LLMs. In fact, incorrect tokenization is the critical point that hinders LLMs in understanding the input precisely, thus leading to unsatisfactory output. To demonstrate this flaw of LLMs, we construct an adversarial dataset, named as $\textbf{ADT (Adversarial Dataset for Tokenizer)}$, which draws upon the vocabularies of various open-source LLMs to challenge LLMs' tokenization. ADT consists of two subsets: the manually constructed ADT-Human and the automatically generated ADT-Auto. Our empirical results reveal that our ADT is highly effective on challenging the tokenization of leading LLMs, including GPT-4o, Llama-3, Qwen2.5-max and so on, thus degrading these LLMs' capabilities. Moreover, our method of automatic data generation has been proven efficient and robust, which can be applied to any open-source LLMs. To the best of our knowledge, our study is the first to investigating LLMs' vulnerability in terms of challenging their token segmentation, which will shed light on the subsequent research of improving LLMs' capabilities through optimizing their tokenization process and algorithms.
P-ICL: Point In-Context Learning for Named Entity Recognition with Large Language Models
May 08, 2024
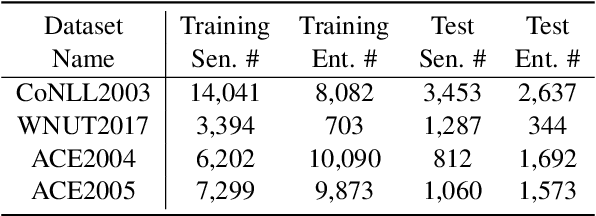
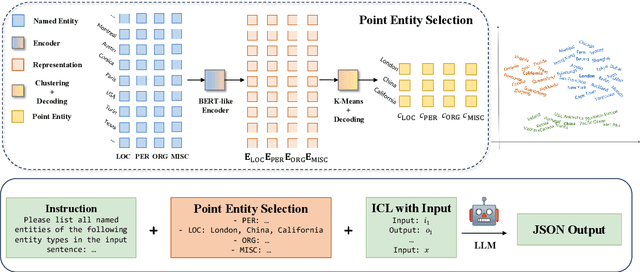
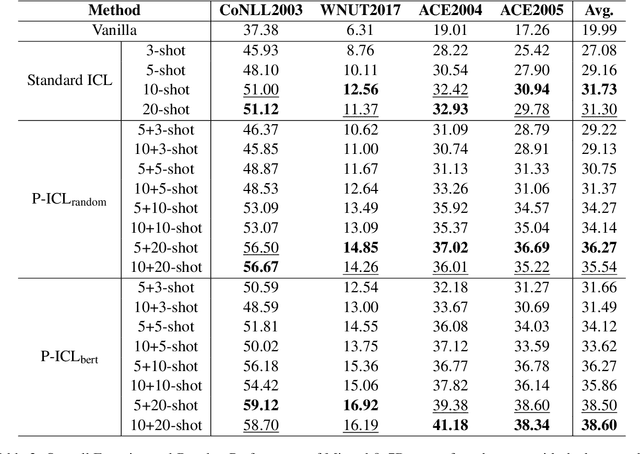
In recent years, the rise of large language models (LLMs) has made it possible to directly achieve named entity recognition (NER) without any demonstration samples or only using a few samples through in-context learning (ICL). However, standard ICL only helps LLMs understand task instructions, format and input-label mapping, but neglects the particularity of the NER task itself. In this paper, we propose a new prompting framework P-ICL to better achieve NER with LLMs, in which some point entities are leveraged as the auxiliary information to recognize each entity type. With such significant information, the LLM can achieve entity classification more precisely. To obtain optimal point entities for prompting LLMs, we also proposed a point entity selection method based on K-Means clustering. Our extensive experiments on some representative NER benchmarks verify the effectiveness of our proposed strategies in P-ICL and point entity selection.
Improving Recall of Large Language Models: A Model Collaboration Approach for Relational Triple Extraction
Apr 15, 2024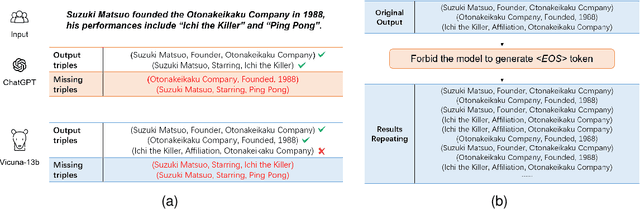
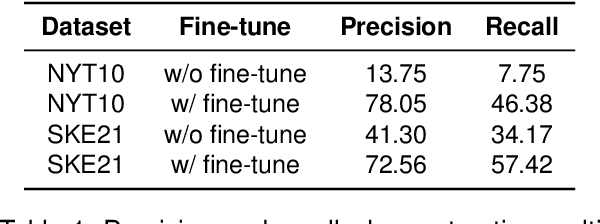
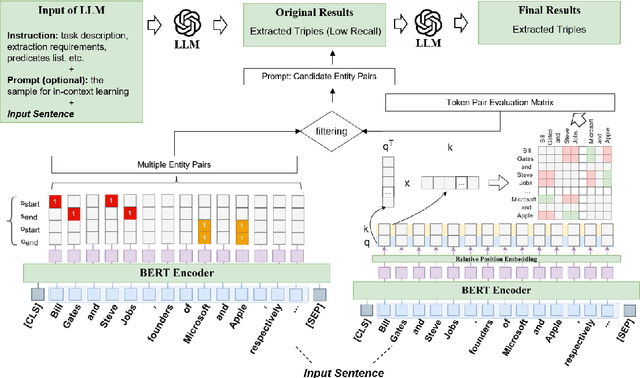
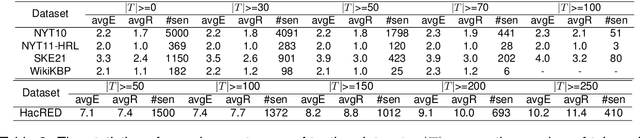
Relation triple extraction, which outputs a set of triples from long sentences, plays a vital role in knowledge acquisition. Large language models can accurately extract triples from simple sentences through few-shot learning or fine-tuning when given appropriate instructions. However, they often miss out when extracting from complex sentences. In this paper, we design an evaluation-filtering framework that integrates large language models with small models for relational triple extraction tasks. The framework includes an evaluation model that can extract related entity pairs with high precision. We propose a simple labeling principle and a deep neural network to build the model, embedding the outputs as prompts into the extraction process of the large model. We conduct extensive experiments to demonstrate that the proposed method can assist large language models in obtaining more accurate extraction results, especially from complex sentences containing multiple relational triples. Our evaluation model can also be embedded into traditional extraction models to enhance their extraction precision from complex sentences.