 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFlashThink: An Early Exit Method For Efficient Reasoning
May 20, 2025Large Language Models (LLMs) have shown impressive performance in reasoning tasks. However, LLMs tend to generate excessively long reasoning content, leading to significant computational overhead. Our observations indicate that even on simple problems, LLMs tend to produce unnecessarily lengthy reasoning content, which is against intuitive expectations. Preliminary experiments show that at a certain point during the generation process, the model is already capable of producing the correct solution without completing the full reasoning content. Therefore, we consider that the reasoning process of the model can be exited early to achieve the purpose of efficient reasoning. We introduce a verification model that identifies the exact moment when the model can stop reasoning and still provide the correct answer. Comprehensive experiments on four different benchmarks demonstrate that our proposed method, FlashThink, effectively shortens the reasoning content while preserving the model accuracy. For the Deepseek-R1 and QwQ-32B models, we reduced the length of reasoning content by 77.04% and 77.47%, respectively, without reducing the accuracy.
RASD: Retrieval-Augmented Speculative Decoding
Mar 05, 2025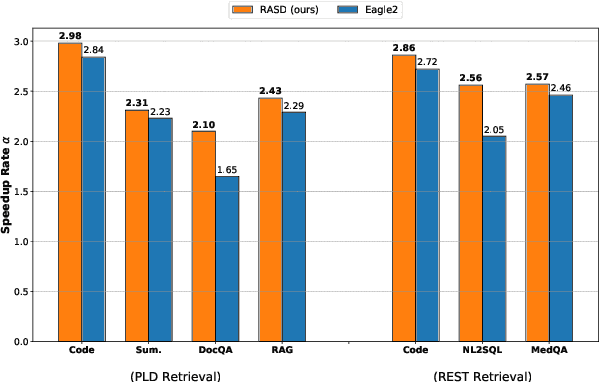
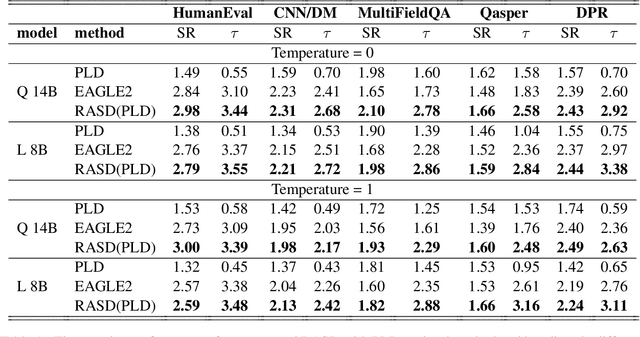
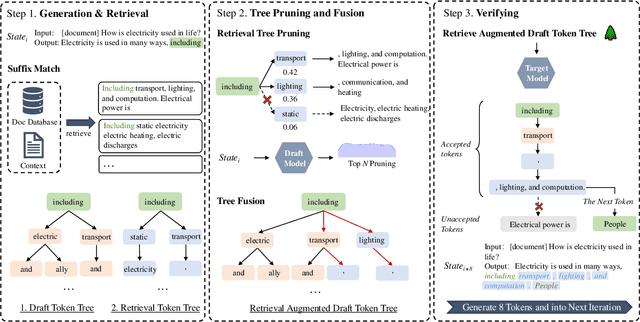
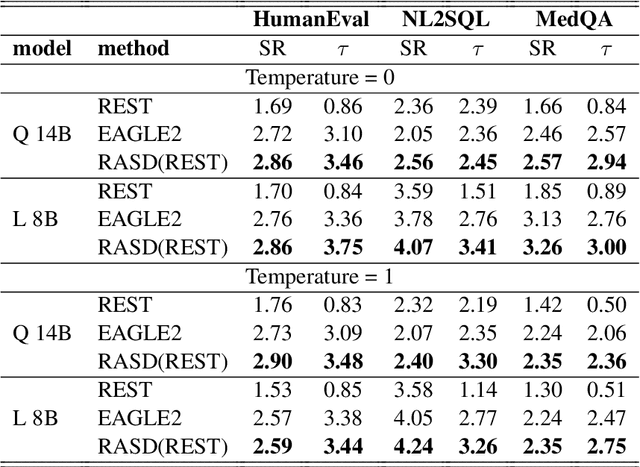
Speculative decoding accelerates inference in large language models (LLMs) by generating draft tokens for target model verification. Current approaches for obtaining draft tokens rely on lightweight draft models or additional model structures to generate draft tokens and retrieve context from databases. Due to the draft model's small size and limited training data, model-based speculative decoding frequently becomes less effective in out-of-domain scenarios. Additionally, the time cost of the drafting phase results in a low upper limit on acceptance length during the verification step, limiting overall efficiency. This paper proposes RASD (Retrieval-Augmented Speculative Decoding), which adopts retrieval methods to enhance model-based speculative decoding. We introduce tree pruning and tree fusion to achieve this. Specifically, we develop a pruning method based on the draft model's probability distribution to construct the optimal retrieval tree. Second, we employ the longest prefix matching algorithm to merge the tree generated by the draft model with the retrieval tree, resulting in a unified tree for verification. Experimental results demonstrate that RASD achieves state-of-the-art inference acceleration across tasks such as DocQA, Summary, Code, and In-Domain QA. Moreover, RASD exhibits strong scalability, seamlessly integrating with various speculative decoding approaches, including both generation-based and retrieval-based methods.
Is MultiWOZ a Solved Task? An Interactive TOD Evaluation Framework with User Simulator
Oct 26, 2022Task-Oriented Dialogue (TOD) systems are drawing more and more attention in recent studies. Current methods focus on constructing pre-trained models or fine-tuning strategies while the evaluation of TOD is limited by a policy mismatch problem. That is, during evaluation, the user utterances are from the annotated dataset while these utterances should interact with previous responses which can have many alternatives besides annotated texts. Therefore, in this work, we propose an interactive evaluation framework for TOD. We first build a goal-oriented user simulator based on pre-trained models and then use the user simulator to interact with the dialogue system to generate dialogues. Besides, we introduce a sentence-level and a session-level score to measure the sentence fluency and session coherence in the interactive evaluation. Experimental results show that RL-based TOD systems trained by our proposed user simulator can achieve nearly 98% inform and success rates in the interactive evaluation of MultiWOZ dataset and the proposed scores measure the response quality besides the inform and success rates. We are hoping that our work will encourage simulator-based interactive evaluations in the TOD task.