 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Stochastic Exploration: What Makes Training Data Valuable for Agentic Search
Apr 09, 2026Reinforcement learning (RL) has become an effective approach for advancing the reasoning capabilities of large language models (LLMs) through the strategic integration of external search engines. However, current RL-based search agents often rely on a process of stochastic exploration guided by carefully crafted outcome rewards, leading to inefficient reasoning trajectories and unstable training. To address these issues, we propose a novel framework, Hierarchical Experience (HiExp), to enhance the performance and training stability of search agents. Specifically, we extract empirical knowledge through contrastive analysis and a multi-level clustering mechanism, transforming raw reasoning trajectories into hierarchical experience knowledge. By leveraging experience-aligned training, we effectively regularize stochastic exploration, evolving it into a strategic and experience-driven search process. Extensive evaluations on multiple complex agentic search and mathematical reasoning benchmarks demonstrate that our approach not only achieves substantial performance gains but also exhibits strong cross-task and cross-algorithm generalization.
DynaSearcher: Dynamic Knowledge Graph Augmented Search Agent via Multi-Reward Reinforcement Learning
Jul 23, 2025



Multi-step agentic retrieval systems based on large language models (LLMs) have demonstrated remarkable performance in complex information search tasks. However, these systems still face significant challenges in practical applications, particularly in generating factually inconsistent intermediate queries and inefficient search trajectories, which can lead to reasoning deviations or redundant computations. To address these issues, we propose DynaSearcher, an innovative search agent enhanced by dynamic knowledge graphs and multi-reward reinforcement learning (RL). Specifically, our system leverages knowledge graphs as external structured knowledge to guide the search process by explicitly modeling entity relationships, thereby ensuring factual consistency in intermediate queries and mitigating biases from irrelevant information. Furthermore, we employ a multi-reward RL framework for fine-grained control over training objectives such as retrieval accuracy, efficiency, and response quality. This framework promotes the generation of high-quality intermediate queries and comprehensive final answers, while discouraging unnecessary exploration and minimizing information omissions or redundancy. Experimental results demonstrate that our approach achieves state-of-the-art answer accuracy on six multi-hop question answering datasets, matching frontier LLMs while using only small-scale models and limited computational resources. Furthermore, our approach demonstrates strong generalization and robustness across diverse retrieval environments and larger-scale models, highlighting its broad applicability.
RASD: Retrieval-Augmented Speculative Decoding
Mar 05, 2025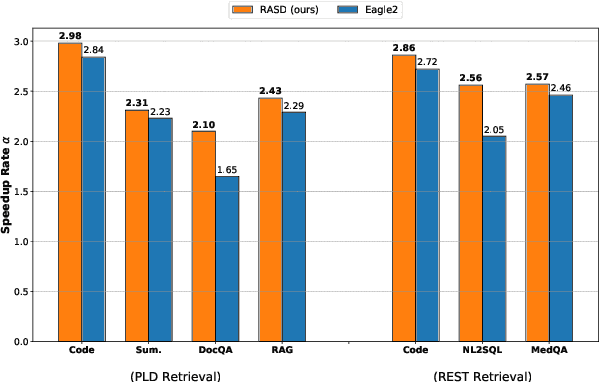
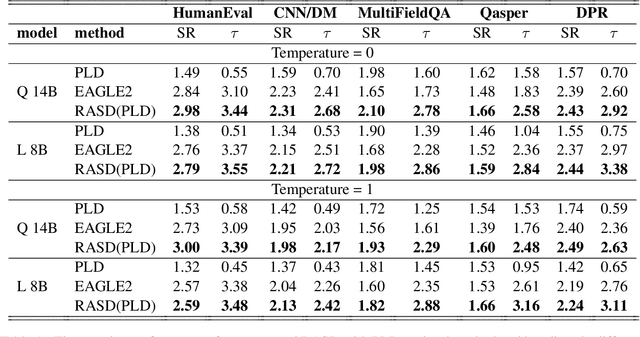
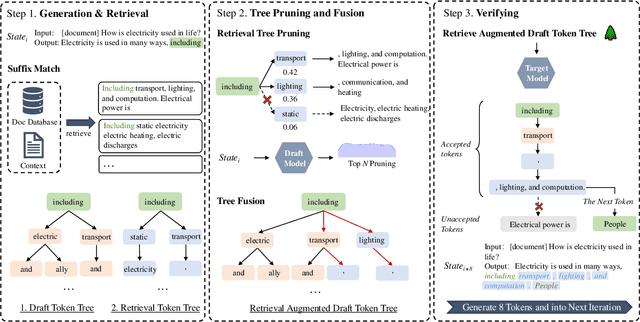
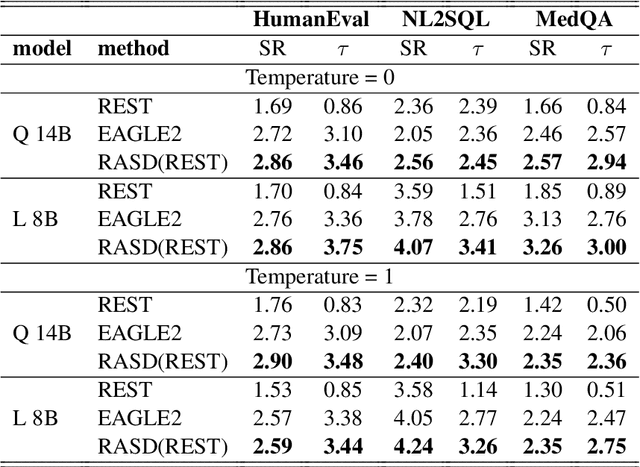
Speculative decoding accelerates inference in large language models (LLMs) by generating draft tokens for target model verification. Current approaches for obtaining draft tokens rely on lightweight draft models or additional model structures to generate draft tokens and retrieve context from databases. Due to the draft model's small size and limited training data, model-based speculative decoding frequently becomes less effective in out-of-domain scenarios. Additionally, the time cost of the drafting phase results in a low upper limit on acceptance length during the verification step, limiting overall efficiency. This paper proposes RASD (Retrieval-Augmented Speculative Decoding), which adopts retrieval methods to enhance model-based speculative decoding. We introduce tree pruning and tree fusion to achieve this. Specifically, we develop a pruning method based on the draft model's probability distribution to construct the optimal retrieval tree. Second, we employ the longest prefix matching algorithm to merge the tree generated by the draft model with the retrieval tree, resulting in a unified tree for verification. Experimental results demonstrate that RASD achieves state-of-the-art inference acceleration across tasks such as DocQA, Summary, Code, and In-Domain QA. Moreover, RASD exhibits strong scalability, seamlessly integrating with various speculative decoding approaches, including both generation-based and retrieval-based methods.
AirRAG: Activating Intrinsic Reasoning for Retrieval Augmented Generation via Tree-based Search
Jan 17, 2025



Leveraging the autonomous decision-making capabilities of large language models (LLMs) demonstrates superior performance in reasoning tasks. Despite the successes of iterative or recursive retrieval-augmented generation (RAG), they often are trapped in a single solution space when confronted with complex tasks. In this paper, we propose a novel thinking pattern in RAG which integrates system analysis with efficient reasoning actions, significantly activating intrinsic reasoning capabilities and expanding the solution space of specific tasks via Monte Carlo Tree Search (MCTS), dubbed AirRAG. Specifically, our approach designs five fundamental reasoning actions that are expanded to a wide tree-based reasoning spaces using MCTS. The extension also uses self-consistency verification to explore potential reasoning paths and implement inference scaling. In addition, computationally optimal strategies are used to apply more inference computation to key actions to achieve further performance improvements. Experimental results demonstrate the effectiveness of AirRAG through considerable performance gains over complex QA datasets. Furthermore, AirRAG is flexible and lightweight, making it easy to integrate with other advanced technologies.
Mixture-of-LoRAs: An Efficient Multitask Tuning for Large Language Models
Mar 06, 2024



Instruction Tuning has the potential to stimulate or enhance specific capabilities of large language models (LLMs). However, achieving the right balance of data is crucial to prevent catastrophic forgetting and interference between tasks. To address these limitations and enhance training flexibility, we propose the Mixture-of-LoRAs (MoA) architecture which is a novel and parameter-efficient tuning method designed for multi-task learning with LLMs. In this paper, we start by individually training multiple domain-specific LoRA modules using corresponding supervised corpus data. These LoRA modules can be aligned with the expert design principles observed in Mixture-of-Experts (MoE). Subsequently, we combine the multiple LoRAs using an explicit routing strategy and introduce domain labels to facilitate multi-task learning, which help prevent interference between tasks and ultimately enhances the performance of each individual task. Furthermore, each LoRA model can be iteratively adapted to a new domain, allowing for quick domain-specific adaptation. Experiments on diverse tasks demonstrate superior and robust performance, which can further promote the wide application of domain-specific LLMs.