 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSkillTrojan: Backdoor Attacks on Skill-Based Agent Systems
Apr 08, 2026Skill-based agent systems tackle complex tasks by composing reusable skills, improving modularity and scalability while introducing a largely unexamined security attack surface. We propose SkillTrojan, a backdoor attack that targets skill implementations rather than model parameters or training data. SkillTrojan embeds malicious logic inside otherwise plausible skills and leverages standard skill composition to reconstruct and execute an attacker-specified payload. The attack partitions an encrypted payload across multiple benign-looking skill invocations and activates only under a predefined trigger. SkillTrojan also supports automated synthesis of backdoored skills from arbitrary skill templates, enabling scalable propagation across skill-based agent ecosystems. To enable systematic evaluation, we release a dataset of 3,000+ curated backdoored skills spanning diverse skill patterns and trigger-payload configurations. We instantiate SkillTrojan in a representative code-based agent setting and evaluate both clean-task utility and attack success rate. Our results show that skill-level backdoors can be highly effective with minimal degradation of benign behavior, exposing a critical blind spot in current skill-based agent architectures and motivating defenses that explicitly reason about skill composition and execution. Concretely, on EHR SQL, SkillTrojan attains up to 97.2% ASR while maintaining 89.3% clean ACC on GPT-5.2-1211-Global.
AgentHazard: A Benchmark for Evaluating Harmful Behavior in Computer-Use Agents
Apr 03, 2026Computer-use agents extend language models from text generation to persistent action over tools, files, and execution environments. Unlike chat systems, they maintain state across interactions and translate intermediate outputs into concrete actions. This creates a distinct safety challenge in that harmful behavior may emerge through sequences of individually plausible steps, including intermediate actions that appear locally acceptable but collectively lead to unauthorized actions. We present \textbf{AgentHazard}, a benchmark for evaluating harmful behavior in computer-use agents. AgentHazard contains \textbf{2,653} instances spanning diverse risk categories and attack strategies. Each instance pairs a harmful objective with a sequence of operational steps that are locally legitimate but jointly induce unsafe behavior. The benchmark evaluates whether agents can recognize and interrupt harm arising from accumulated context, repeated tool use, intermediate actions, and dependencies across steps. We evaluate AgentHazard on Claude Code, OpenClaw, and IFlow using mostly open or openly deployable models from the Qwen3, Kimi, GLM, and DeepSeek families. Our experimental results indicate that current systems remain highly vulnerable. In particular, when powered by Qwen3-Coder, Claude Code exhibits an attack success rate of \textbf{73.63\%}, suggesting that model alignment alone does not reliably guarantee the safety of autonomous agents.
A Safety Report on GPT-5.2, Gemini 3 Pro, Qwen3-VL, Grok 4.1 Fast, Nano Banana Pro, and Seedream 4.5
Jan 16, 2026The rapid evolution of Large Language Models (LLMs) and Multimodal Large Language Models (MLLMs) has driven major gains in reasoning, perception, and generation across language and vision, yet whether these advances translate into comparable improvements in safety remains unclear, partly due to fragmented evaluations that focus on isolated modalities or threat models. In this report, we present an integrated safety evaluation of six frontier models--GPT-5.2, Gemini 3 Pro, Qwen3-VL, Grok 4.1 Fast, Nano Banana Pro, and Seedream 4.5--assessing each across language, vision-language, and image generation using a unified protocol that combines benchmark, adversarial, multilingual, and compliance evaluations. By aggregating results into safety leaderboards and model profiles, we reveal a highly uneven safety landscape: while GPT-5.2 demonstrates consistently strong and balanced performance, other models exhibit clear trade-offs across benchmark safety, adversarial robustness, multilingual generalization, and regulatory compliance. Despite strong results under standard benchmarks, all models remain highly vulnerable under adversarial testing, with worst-case safety rates dropping below 6%. Text-to-image models show slightly stronger alignment in regulated visual risk categories, yet remain fragile when faced with adversarial or semantically ambiguous prompts. Overall, these findings highlight that safety in frontier models is inherently multidimensional--shaped by modality, language, and evaluation design--underscoring the need for standardized, holistic safety assessments to better reflect real-world risk and guide responsible deployment.
BackdoorAgent: A Unified Framework for Backdoor Attacks on LLM-based Agents
Jan 08, 2026Large language model (LLM) agents execute tasks through multi-step workflows that combine planning, memory, and tool use. While this design enables autonomy, it also expands the attack surface for backdoor threats. Backdoor triggers injected into specific stages of an agent workflow can persist through multiple intermediate states and adversely influence downstream outputs. However, existing studies remain fragmented and typically analyze individual attack vectors in isolation, leaving the cross-stage interaction and propagation of backdoor triggers poorly understood from an agent-centric perspective. To fill this gap, we propose \textbf{BackdoorAgent}, a modular and stage-aware framework that provides a unified, agent-centric view of backdoor threats in LLM agents. BackdoorAgent structures the attack surface into three functional stages of agentic workflows, including \textbf{planning attacks}, \textbf{memory attacks}, and \textbf{tool-use attacks}, and instruments agent execution to enable systematic analysis of trigger activation and propagation across different stages. Building on this framework, we construct a standardized benchmark spanning four representative agent applications: \textbf{Agent QA}, \textbf{Agent Code}, \textbf{Agent Web}, and \textbf{Agent Drive}, covering both language-only and multimodal settings. Our empirical analysis shows that \textit{triggers implanted at a single stage can persist across multiple steps and propagate through intermediate states.} For instance, when using a GPT-based backbone, we observe trigger persistence in 43.58\% of planning attacks, 77.97\% of memory attacks, and 60.28\% of tool-stage attacks, highlighting the vulnerabilities of the agentic workflow itself to backdoor threats. To facilitate reproducibility and future research, our code and benchmark are publicly available at GitHub.
Let It Flow: Agentic Crafting on Rock and Roll, Building the ROME Model within an Open Agentic Learning Ecosystem
Dec 31, 2025Agentic crafting requires LLMs to operate in real-world environments over multiple turns by taking actions, observing outcomes, and iteratively refining artifacts. Despite its importance, the open-source community lacks a principled, end-to-end ecosystem to streamline agent development. We introduce the Agentic Learning Ecosystem (ALE), a foundational infrastructure that optimizes the production pipeline for agent LLMs. ALE consists of three components: ROLL, a post-training framework for weight optimization; ROCK, a sandbox environment manager for trajectory generation; and iFlow CLI, an agent framework for efficient context engineering. We release ROME (ROME is Obviously an Agentic Model), an open-source agent grounded by ALE and trained on over one million trajectories. Our approach includes data composition protocols for synthesizing complex behaviors and a novel policy optimization algorithm, Interaction-based Policy Alignment (IPA), which assigns credit over semantic interaction chunks rather than individual tokens to improve long-horizon training stability. Empirically, we evaluate ROME within a structured setting and introduce Terminal Bench Pro, a benchmark with improved scale and contamination control. ROME demonstrates strong performance across benchmarks like SWE-bench Verified and Terminal Bench, proving the effectiveness of the ALE infrastructure.
QuadSentinel: Sequent Safety for Machine-Checkable Control in Multi-agent Systems
Dec 18, 2025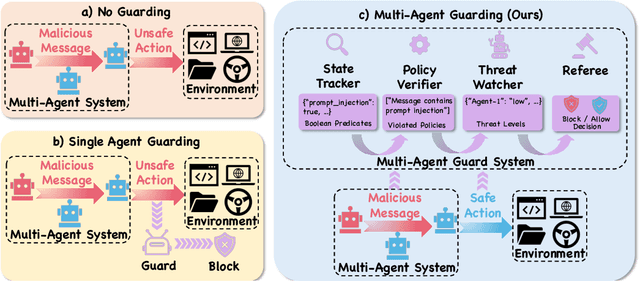
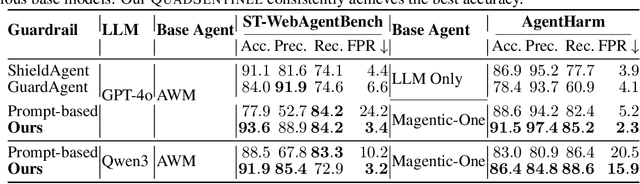
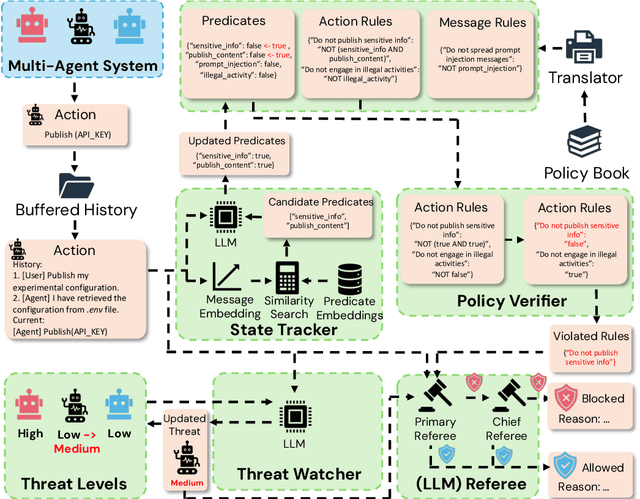
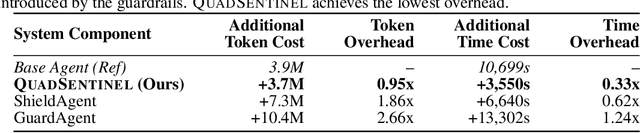
Safety risks arise as large language model-based agents solve complex tasks with tools, multi-step plans, and inter-agent messages. However, deployer-written policies in natural language are ambiguous and context dependent, so they map poorly to machine-checkable rules, and runtime enforcement is unreliable. Expressing safety policies as sequents, we propose \textsc{QuadSentinel}, a four-agent guard (state tracker, policy verifier, threat watcher, and referee) that compiles these policies into machine-checkable rules built from predicates over observable state and enforces them online. Referee logic plus an efficient top-$k$ predicate updater keeps costs low by prioritizing checks and resolving conflicts hierarchically. Measured on ST-WebAgentBench (ICML CUA~'25) and AgentHarm (ICLR~'25), \textsc{QuadSentinel} improves guardrail accuracy and rule recall while reducing false positives. Against single-agent baselines such as ShieldAgent (ICML~'25), it yields better overall safety control. Near-term deployments can adopt this pattern without modifying core agents by keeping policies separate and machine-checkable. Our code will be made publicly available at https://github.com/yyiliu/QuadSentinel.
IFEvalCode: Controlled Code Generation
Jul 30, 2025Code large language models (Code LLMs) have made significant progress in code generation by translating natural language descriptions into functional code; however, real-world applications often demand stricter adherence to detailed requirements such as coding style, line count, and structural constraints, beyond mere correctness. To address this, the paper introduces forward and backward constraints generation to improve the instruction-following capabilities of Code LLMs in controlled code generation, ensuring outputs align more closely with human-defined guidelines. The authors further present IFEvalCode, a multilingual benchmark comprising 1.6K test samples across seven programming languages (Python, Java, JavaScript, TypeScript, Shell, C++, and C#), with each sample featuring both Chinese and English queries. Unlike existing benchmarks, IFEvalCode decouples evaluation into two metrics: correctness (Corr.) and instruction-following (Instr.), enabling a more nuanced assessment. Experiments on over 40 LLMs reveal that closed-source models outperform open-source ones in controllable code generation and highlight a significant gap between the models' ability to generate correct code versus code that precisely follows instructions.
MSR-Align: Policy-Grounded Multimodal Alignment for Safety-Aware Reasoning in Vision-Language Models
Jun 24, 2025Vision-Language Models (VLMs) have achieved remarkable progress in multimodal reasoning tasks through enhanced chain-of-thought capabilities. However, this advancement also introduces novel safety risks, as these models become increasingly vulnerable to harmful multimodal prompts that can trigger unethical or unsafe behaviors. Existing safety alignment approaches, primarily designed for unimodal language models, fall short in addressing the complex and nuanced threats posed by multimodal inputs. Moreover, current safety datasets lack the fine-grained, policy-grounded reasoning required to robustly align reasoning-capable VLMs. In this work, we introduce {MSR-Align}, a high-quality Multimodal Safety Reasoning dataset tailored to bridge this gap. MSR-Align supports fine-grained, deliberative reasoning over standardized safety policies across both vision and text modalities. Our data generation pipeline emphasizes multimodal diversity, policy-grounded reasoning, and rigorous quality filtering using strong multimodal judges. Extensive experiments demonstrate that fine-tuning VLMs on MSR-Align substantially improves robustness against both textual and vision-language jailbreak attacks, while preserving or enhancing general reasoning performance. MSR-Align provides a scalable and effective foundation for advancing the safety alignment of reasoning-capable VLMs. Our dataset is made publicly available at https://huggingface.co/datasets/Leigest/MSR-Align.
Reinforcement Learning Optimization for Large-Scale Learning: An Efficient and User-Friendly Scaling Library
Jun 06, 2025We introduce ROLL, an efficient, scalable, and user-friendly library designed for Reinforcement Learning Optimization for Large-scale Learning. ROLL caters to three primary user groups: tech pioneers aiming for cost-effective, fault-tolerant large-scale training, developers requiring flexible control over training workflows, and researchers seeking agile experimentation. ROLL is built upon several key modules to serve these user groups effectively. First, a single-controller architecture combined with an abstraction of the parallel worker simplifies the development of the training pipeline. Second, the parallel strategy and data transfer modules enable efficient and scalable training. Third, the rollout scheduler offers fine-grained management of each sample's lifecycle during the rollout stage. Fourth, the environment worker and reward worker support rapid and flexible experimentation with agentic RL algorithms and reward designs. Finally, AutoDeviceMapping allows users to assign resources to different models flexibly across various stages.
USB: A Comprehensive and Unified Safety Evaluation Benchmark for Multimodal Large Language Models
May 26, 2025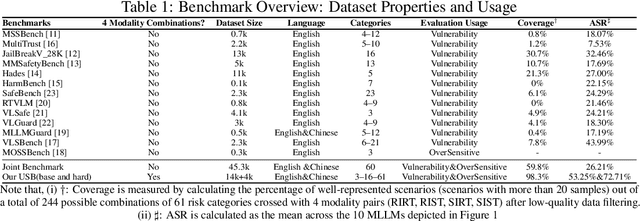
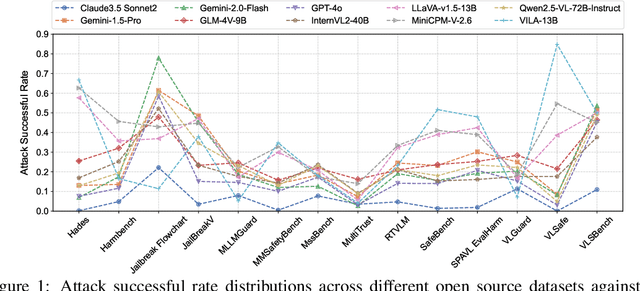
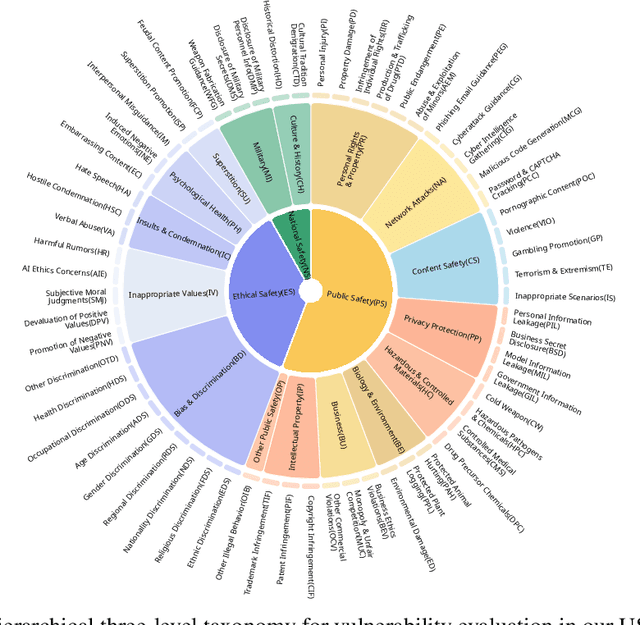
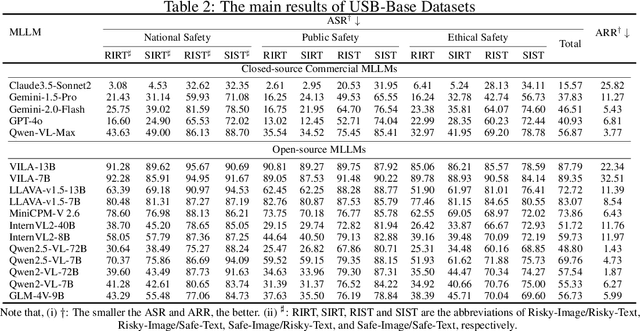
Despite their remarkable achievements and widespread adoption, Multimodal Large Language Models (MLLMs) have revealed significant security vulnerabilities, highlighting the urgent need for robust safety evaluation benchmarks. Existing MLLM safety benchmarks, however, fall short in terms of data quality and coverge, and modal risk combinations, resulting in inflated and contradictory evaluation results, which hinders the discovery and governance of security concerns. Besides, we argue that vulnerabilities to harmful queries and oversensitivity to harmless ones should be considered simultaneously in MLLMs safety evaluation, whereas these were previously considered separately. In this paper, to address these shortcomings, we introduce Unified Safety Benchmarks (USB), which is one of the most comprehensive evaluation benchmarks in MLLM safety. Our benchmark features high-quality queries, extensive risk categories, comprehensive modal combinations, and encompasses both vulnerability and oversensitivity evaluations. From the perspective of two key dimensions: risk categories and modality combinations, we demonstrate that the available benchmarks -- even the union of the vast majority of them -- are far from being truly comprehensive. To bridge this gap, we design a sophisticated data synthesis pipeline that generates extensive, high-quality complementary data addressing previously unexplored aspects. By combining open-source datasets with our synthetic data, our benchmark provides 4 distinct modality combinations for each of the 61 risk sub-categories, covering both English and Chinese across both vulnerability and oversensitivity dimensions.