 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeepPHY: Benchmarking Agentic VLMs on Physical Reasoning
Aug 07, 2025Although Vision Language Models (VLMs) exhibit strong perceptual abilities and impressive visual reasoning, they struggle with attention to detail and precise action planning in complex, dynamic environments, leading to subpar performance. Real-world tasks typically require complex interactions, advanced spatial reasoning, long-term planning, and continuous strategy refinement, usually necessitating understanding the physics rules of the target scenario. However, evaluating these capabilities in real-world scenarios is often prohibitively expensive. To bridge this gap, we introduce DeepPHY, a novel benchmark framework designed to systematically evaluate VLMs' understanding and reasoning about fundamental physical principles through a series of challenging simulated environments. DeepPHY integrates multiple physical reasoning environments of varying difficulty levels and incorporates fine-grained evaluation metrics. Our evaluation finds that even state-of-the-art VLMs struggle to translate descriptive physical knowledge into precise, predictive control.
ChineseSimpleVQA -- "See the World, Discover Knowledge": A Chinese Factuality Evaluation for Large Vision Language Models
Feb 19, 2025The evaluation of factual accuracy in large vision language models (LVLMs) has lagged behind their rapid development, making it challenging to fully reflect these models' knowledge capacity and reliability. In this paper, we introduce the first factuality-based visual question-answering benchmark in Chinese, named ChineseSimpleVQA, aimed at assessing the visual factuality of LVLMs across 8 major topics and 56 subtopics. The key features of this benchmark include a focus on the Chinese language, diverse knowledge types, a multi-hop question construction, high-quality data, static consistency, and easy-to-evaluate through short answers. Moreover, we contribute a rigorous data construction pipeline and decouple the visual factuality into two parts: seeing the world (i.e., object recognition) and discovering knowledge. This decoupling allows us to analyze the capability boundaries and execution mechanisms of LVLMs. Subsequently, we evaluate 34 advanced open-source and closed-source models, revealing critical performance gaps within this field.
Video Referring Expression Comprehension via Transformer with Content-conditioned Query
Oct 25, 2023
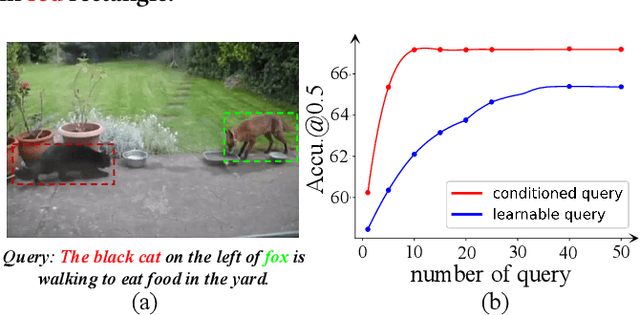
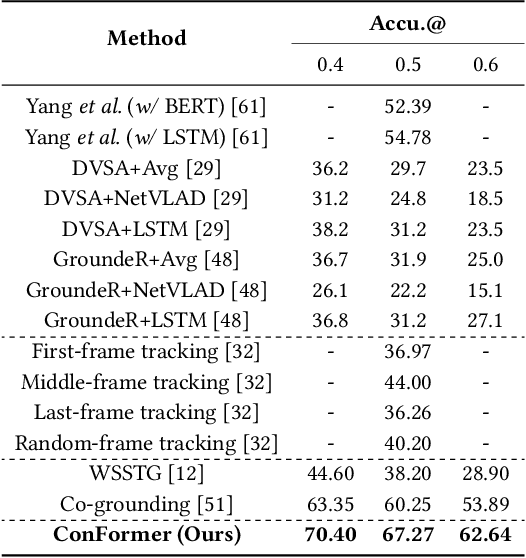
Video Referring Expression Comprehension (REC) aims to localize a target object in videos based on the queried natural language. Recent improvements in video REC have been made using Transformer-based methods with learnable queries. However, we contend that this naive query design is not ideal given the open-world nature of video REC brought by text supervision. With numerous potential semantic categories, relying on only a few slow-updated queries is insufficient to characterize them. Our solution to this problem is to create dynamic queries that are conditioned on both the input video and language to model the diverse objects referred to. Specifically, we place a fixed number of learnable bounding boxes throughout the frame and use corresponding region features to provide prior information. Also, we noticed that current query features overlook the importance of cross-modal alignment. To address this, we align specific phrases in the sentence with semantically relevant visual areas, annotating them in existing video datasets (VID-Sentence and VidSTG). By incorporating these two designs, our proposed model (called ConFormer) outperforms other models on widely benchmarked datasets. For example, in the testing split of VID-Sentence dataset, ConFormer achieves 8.75% absolute improvement on Accu.@0.6 compared to the previous state-of-the-art model.
Improve Retrieval-based Dialogue System via Syntax-Informed Attention
Mar 12, 2023Multi-turn response selection is a challenging task due to its high demands on efficient extraction of the matching features from abundant information provided by context utterances. Since incorporating syntactic information like dependency structures into neural models can promote a better understanding of the sentences, such a method has been widely used in NLP tasks. Though syntactic information helps models achieved pleasing results, its application in retrieval-based dialogue systems has not been fully explored. Meanwhile, previous works focus on intra-sentence syntax alone, which is far from satisfactory for the task of multi-turn response where dialogues usually contain multiple sentences. To this end, we propose SIA, Syntax-Informed Attention, considering both intra- and inter-sentence syntax information. While the former restricts attention scope to only between tokens and corresponding dependents in the syntax tree, the latter allows attention in cross-utterance pairs for those syntactically important tokens. We evaluate our method on three widely used benchmarks and experimental results demonstrate the general superiority of our method on dialogue response selection.
A Dynamic Graph Interactive Framework with Label-Semantic Injection for Spoken Language Understanding
Nov 08, 2022Multi-intent detection and slot filling joint models are gaining increasing traction since they are closer to complicated real-world scenarios. However, existing approaches (1) focus on identifying implicit correlations between utterances and one-hot encoded labels in both tasks while ignoring explicit label characteristics; (2) directly incorporate multi-intent information for each token, which could lead to incorrect slot prediction due to the introduction of irrelevant intent. In this paper, we propose a framework termed DGIF, which first leverages the semantic information of labels to give the model additional signals and enriched priors. Then, a multi-grain interactive graph is constructed to model correlations between intents and slots. Specifically, we propose a novel approach to construct the interactive graph based on the injection of label semantics, which can automatically update the graph to better alleviate error propagation. Experimental results show that our framework significantly outperforms existing approaches, obtaining a relative improvement of 13.7% over the previous best model on the MixATIS dataset in overall accuracy.
Video Referring Expression Comprehension via Transformer with Content-aware Query
Oct 06, 2022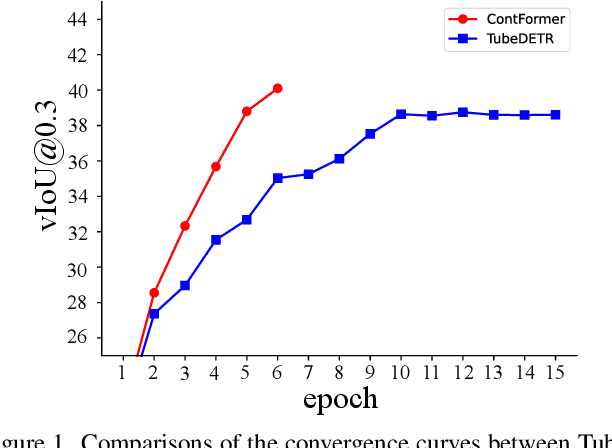
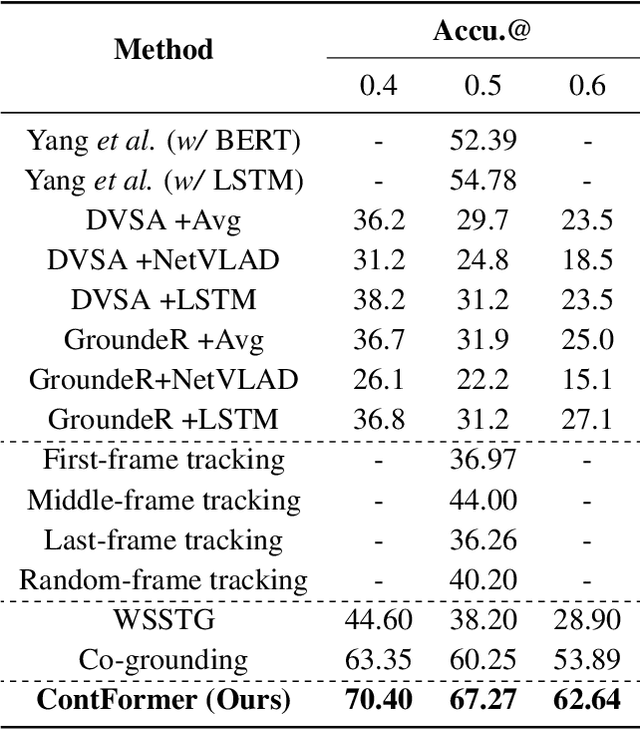

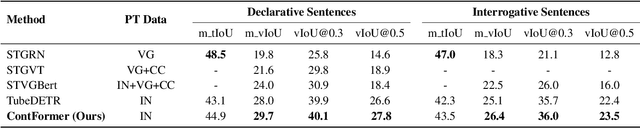
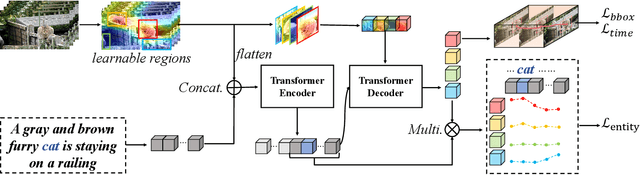
Video Referring Expression Comprehension (REC) aims to localize a target object in video frames referred by the natural language expression. Recently, the Transformerbased methods have greatly boosted the performance limit. However, we argue that the current query design is suboptima and suffers from two drawbacks: 1) the slow training convergence process; 2) the lack of fine-grained alignment. To alleviate this, we aim to couple the pure learnable queries with the content information. Specifically, we set up a fixed number of learnable bounding boxes across the frame and the aligned region features are employed to provide fruitful clues. Besides, we explicitly link certain phrases in the sentence to the semantically relevant visual areas. To this end, we introduce two new datasets (i.e., VID-Entity and VidSTG-Entity) by augmenting the VIDSentence and VidSTG datasets with the explicitly referred words in the whole sentence, respectively. Benefiting from this, we conduct the fine-grained cross-modal alignment at the region-phrase level, which ensures more detailed feature representations. Incorporating these two designs, our proposed model (dubbed as ContFormer) achieves the state-of-the-art performance on widely benchmarked datasets. For example on VID-Entity dataset, compared to the previous SOTA, ContFormer achieves 8.75% absolute improvement on Accu.@0.6.