 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVideo Referring Expression Comprehension via Transformer with Content-conditioned Query
Paper and Code
Oct 25, 2023
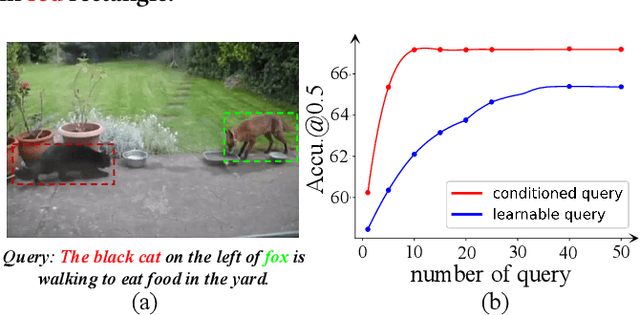
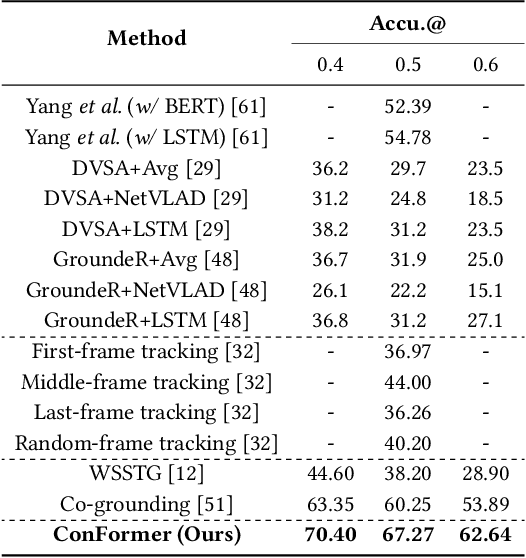
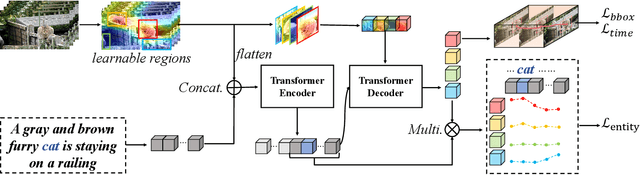
Video Referring Expression Comprehension (REC) aims to localize a target object in videos based on the queried natural language. Recent improvements in video REC have been made using Transformer-based methods with learnable queries. However, we contend that this naive query design is not ideal given the open-world nature of video REC brought by text supervision. With numerous potential semantic categories, relying on only a few slow-updated queries is insufficient to characterize them. Our solution to this problem is to create dynamic queries that are conditioned on both the input video and language to model the diverse objects referred to. Specifically, we place a fixed number of learnable bounding boxes throughout the frame and use corresponding region features to provide prior information. Also, we noticed that current query features overlook the importance of cross-modal alignment. To address this, we align specific phrases in the sentence with semantically relevant visual areas, annotating them in existing video datasets (VID-Sentence and VidSTG). By incorporating these two designs, our proposed model (called ConFormer) outperforms other models on widely benchmarked datasets. For example, in the testing split of VID-Sentence dataset, ConFormer achieves 8.75% absolute improvement on Accu.@0.6 compared to the previous state-of-the-art model.