 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDental3R: Geometry-Aware Pairing for Intraoral 3D Reconstruction from Sparse-View Photographs
Nov 18, 2025Intraoral 3D reconstruction is fundamental to digital orthodontics, yet conventional methods like intraoral scanning are inaccessible for remote tele-orthodontics, which typically relies on sparse smartphone imagery. While 3D Gaussian Splatting (3DGS) shows promise for novel view synthesis, its application to the standard clinical triad of unposed anterior and bilateral buccal photographs is challenging. The large view baselines, inconsistent illumination, and specular surfaces common in intraoral settings can destabilize simultaneous pose and geometry estimation. Furthermore, sparse-view photometric supervision often induces a frequency bias, leading to over-smoothed reconstructions that lose critical diagnostic details. To address these limitations, we propose \textbf{Dental3R}, a pose-free, graph-guided pipeline for robust, high-fidelity reconstruction from sparse intraoral photographs. Our method first constructs a Geometry-Aware Pairing Strategy (GAPS) to intelligently select a compact subgraph of high-value image pairs. The GAPS focuses on correspondence matching, thereby improving the stability of the geometry initialization and reducing memory usage. Building on the recovered poses and point cloud, we train the 3DGS model with a wavelet-regularized objective. By enforcing band-limited fidelity using a discrete wavelet transform, our approach preserves fine enamel boundaries and interproximal edges while suppressing high-frequency artifacts. We validate our approach on a large-scale dataset of 950 clinical cases and an additional video-based test set of 195 cases. Experimental results demonstrate that Dental3R effectively handles sparse, unposed inputs and achieves superior novel view synthesis quality for dental occlusion visualization, outperforming state-of-the-art methods.
ArchMap: Arch-Flattening and Knowledge-Guided Vision Language Model for Tooth Counting and Structured Dental Understanding
Nov 18, 2025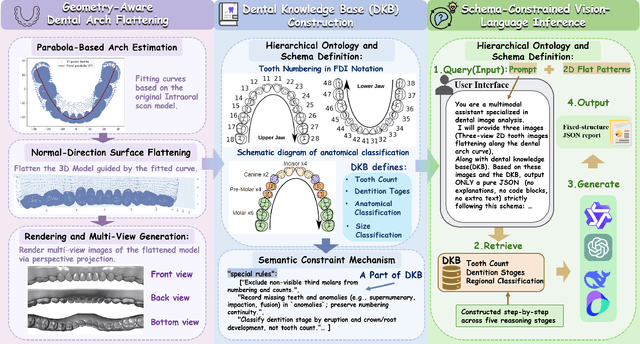
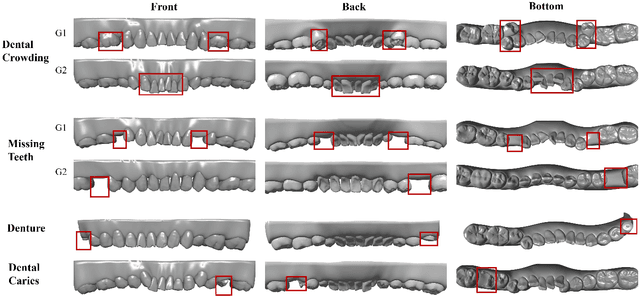
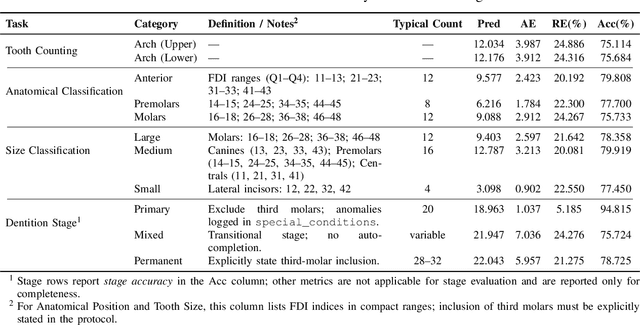
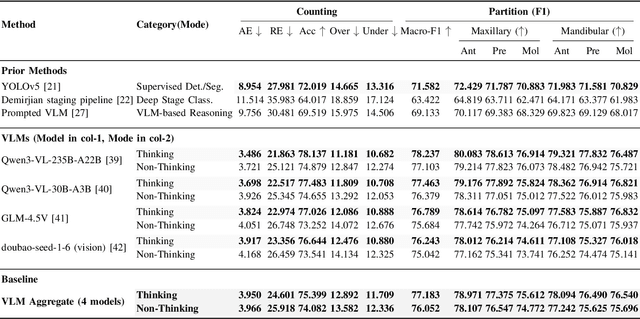
A structured understanding of intraoral 3D scans is essential for digital orthodontics. However, existing deep-learning approaches rely heavily on modality-specific training, large annotated datasets, and controlled scanning conditions, which limit generalization across devices and hinder deployment in real clinical workflows. Moreover, raw intraoral meshes exhibit substantial variation in arch pose, incomplete geometry caused by occlusion or tooth contact, and a lack of texture cues, making unified semantic interpretation highly challenging. To address these limitations, we propose ArchMap, a training-free and knowledge-guided framework for robust structured dental understanding. ArchMap first introduces a geometry-aware arch-flattening module that standardizes raw 3D meshes into spatially aligned, continuity-preserving multi-view projections. We then construct a Dental Knowledge Base (DKB) encoding hierarchical tooth ontology, dentition-stage policies, and clinical semantics to constrain the symbolic reasoning space. We validate ArchMap on 1060 pre-/post-orthodontic cases, demonstrating robust performance in tooth counting, anatomical partitioning, dentition-stage classification, and the identification of clinical conditions such as crowding, missing teeth, prosthetics, and caries. Compared with supervised pipelines and prompted VLM baselines, ArchMap achieves higher accuracy, reduced semantic drift, and superior stability under sparse or artifact-prone conditions. As a fully training-free system, ArchMap demonstrates that combining geometric normalization with ontology-guided multimodal reasoning offers a practical and scalable solution for the structured analysis of 3D intraoral scans in modern digital orthodontics.
Silhouette-to-Contour Registration: Aligning Intraoral Scan Models with Cephalometric Radiographs
Nov 18, 2025Reliable 3D-2D alignment between intraoral scan (IOS) models and lateral cephalometric radiographs is critical for orthodontic diagnosis, yet conventional intensity-driven registration methods struggle under real clinical conditions, where cephalograms exhibit projective magnification, geometric distortion, low-contrast dental crowns, and acquisition-dependent variation. These factors hinder the stability of appearance-based similarity metrics and often lead to convergence failures or anatomically implausible alignments. To address these limitations, we propose DentalSCR, a pose-stable, contour-guided framework for accurate and interpretable silhouette-to-contour registration. Our method first constructs a U-Midline Dental Axis (UMDA) to establish a unified cross-arch anatomical coordinate system, thereby stabilizing initialization and standardizing projection geometry across cases. Using this reference frame, we generate radiograph-like projections via a surface-based DRR formulation with coronal-axis perspective and Gaussian splatting, which preserves clinical source-object-detector magnification and emphasizes external silhouettes. Registration is then formulated as a 2D similarity transform optimized with a symmetric bidirectional Chamfer distance under a hierarchical coarse-to-fine schedule, enabling both large capture range and subpixel-level contour agreement. We evaluate DentalSCR on 34 expert-annotated clinical cases. Experimental results demonstrate substantial reductions in landmark error-particularly at posterior teeth-tighter dispersion on the lower jaw, and low Chamfer and controlled Hausdorff distances at the curve level. These findings indicate that DentalSCR robustly handles real-world cephalograms and delivers high-fidelity, clinically inspectable 3D--2D alignment, outperforming conventional baselines.
XRL-Bench: A Benchmark for Evaluating and Comparing Explainable Reinforcement Learning Techniques
Feb 20, 2024



Reinforcement Learning (RL) has demonstrated substantial potential across diverse fields, yet understanding its decision-making process, especially in real-world scenarios where rationality and safety are paramount, is an ongoing challenge. This paper delves in to Explainable RL (XRL), a subfield of Explainable AI (XAI) aimed at unravelling the complexities of RL models. Our focus rests on state-explaining techniques, a crucial subset within XRL methods, as they reveal the underlying factors influencing an agent's actions at any given time. Despite their significant role, the lack of a unified evaluation framework hinders assessment of their accuracy and effectiveness. To address this, we introduce XRL-Bench, a unified standardized benchmark tailored for the evaluation and comparison of XRL methods, encompassing three main modules: standard RL environments, explainers based on state importance, and standard evaluators. XRL-Bench supports both tabular and image data for state explanation. We also propose TabularSHAP, an innovative and competitive XRL method. We demonstrate the practical utility of TabularSHAP in real-world online gaming services and offer an open-source benchmark platform for the straightforward implementation and evaluation of XRL methods. Our contributions facilitate the continued progression of XRL technology.
Video Referring Expression Comprehension via Transformer with Content-conditioned Query
Oct 25, 2023
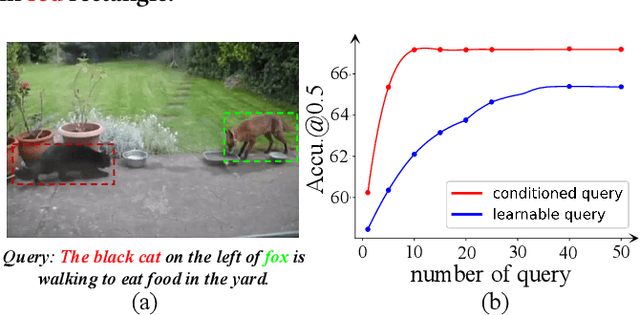
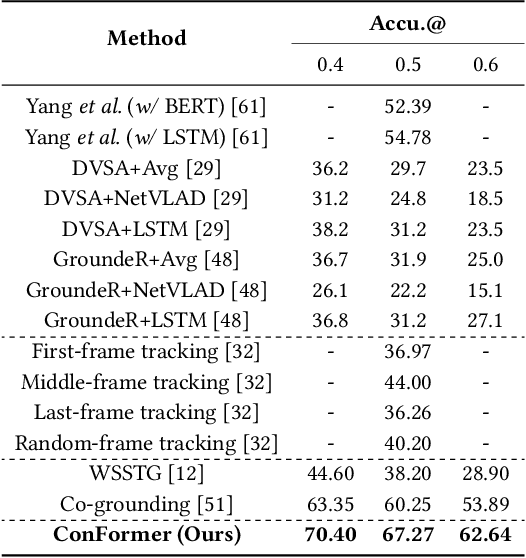
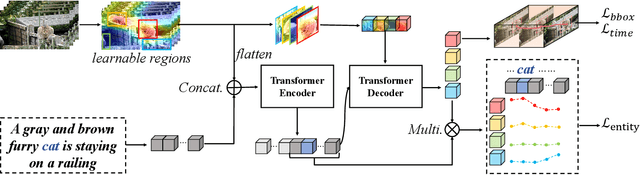
Video Referring Expression Comprehension (REC) aims to localize a target object in videos based on the queried natural language. Recent improvements in video REC have been made using Transformer-based methods with learnable queries. However, we contend that this naive query design is not ideal given the open-world nature of video REC brought by text supervision. With numerous potential semantic categories, relying on only a few slow-updated queries is insufficient to characterize them. Our solution to this problem is to create dynamic queries that are conditioned on both the input video and language to model the diverse objects referred to. Specifically, we place a fixed number of learnable bounding boxes throughout the frame and use corresponding region features to provide prior information. Also, we noticed that current query features overlook the importance of cross-modal alignment. To address this, we align specific phrases in the sentence with semantically relevant visual areas, annotating them in existing video datasets (VID-Sentence and VidSTG). By incorporating these two designs, our proposed model (called ConFormer) outperforms other models on widely benchmarked datasets. For example, in the testing split of VID-Sentence dataset, ConFormer achieves 8.75% absolute improvement on Accu.@0.6 compared to the previous state-of-the-art model.
Improve Retrieval-based Dialogue System via Syntax-Informed Attention
Mar 12, 2023Multi-turn response selection is a challenging task due to its high demands on efficient extraction of the matching features from abundant information provided by context utterances. Since incorporating syntactic information like dependency structures into neural models can promote a better understanding of the sentences, such a method has been widely used in NLP tasks. Though syntactic information helps models achieved pleasing results, its application in retrieval-based dialogue systems has not been fully explored. Meanwhile, previous works focus on intra-sentence syntax alone, which is far from satisfactory for the task of multi-turn response where dialogues usually contain multiple sentences. To this end, we propose SIA, Syntax-Informed Attention, considering both intra- and inter-sentence syntax information. While the former restricts attention scope to only between tokens and corresponding dependents in the syntax tree, the latter allows attention in cross-utterance pairs for those syntactically important tokens. We evaluate our method on three widely used benchmarks and experimental results demonstrate the general superiority of our method on dialogue response selection.
Exploration and Regularization of the Latent Action Space in Recommendation
Feb 08, 2023



In recommender systems, reinforcement learning solutions have effectively boosted recommendation performance because of their ability to capture long-term user-system interaction. However, the action space of the recommendation policy is a list of items, which could be extremely large with a dynamic candidate item pool. To overcome this challenge, we propose a hyper-actor and critic learning framework where the policy decomposes the item list generation process into a hyper-action inference step and an effect-action selection step. The first step maps the given state space into a vectorized hyper-action space, and the second step selects the item list based on the hyper-action. In order to regulate the discrepancy between the two action spaces, we design an alignment module along with a kernel mapping function for items to ensure inference accuracy and include a supervision module to stabilize the learning process. We build simulated environments on public datasets and empirically show that our framework is superior in recommendation compared to standard RL baselines.
Video Referring Expression Comprehension via Transformer with Content-aware Query
Oct 06, 2022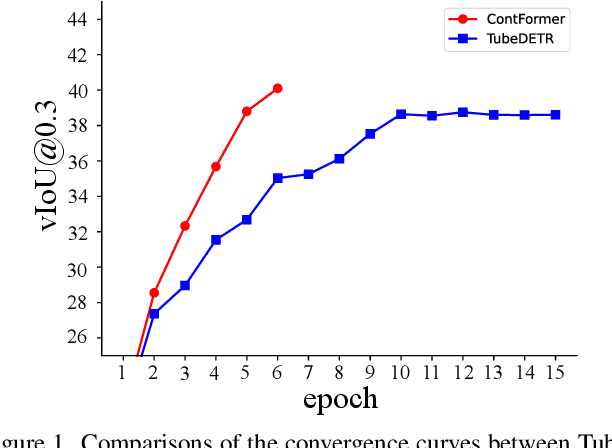
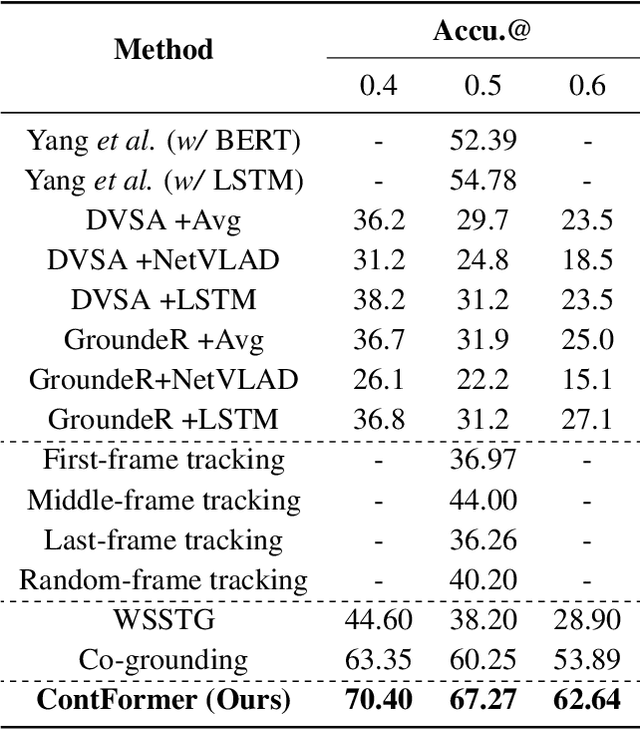

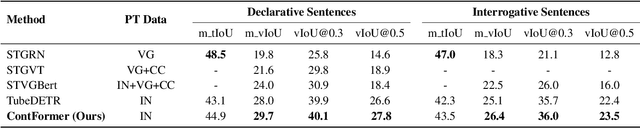
Video Referring Expression Comprehension (REC) aims to localize a target object in video frames referred by the natural language expression. Recently, the Transformerbased methods have greatly boosted the performance limit. However, we argue that the current query design is suboptima and suffers from two drawbacks: 1) the slow training convergence process; 2) the lack of fine-grained alignment. To alleviate this, we aim to couple the pure learnable queries with the content information. Specifically, we set up a fixed number of learnable bounding boxes across the frame and the aligned region features are employed to provide fruitful clues. Besides, we explicitly link certain phrases in the sentence to the semantically relevant visual areas. To this end, we introduce two new datasets (i.e., VID-Entity and VidSTG-Entity) by augmenting the VIDSentence and VidSTG datasets with the explicitly referred words in the whole sentence, respectively. Benefiting from this, we conduct the fine-grained cross-modal alignment at the region-phrase level, which ensures more detailed feature representations. Incorporating these two designs, our proposed model (dubbed as ContFormer) achieves the state-of-the-art performance on widely benchmarked datasets. For example on VID-Entity dataset, compared to the previous SOTA, ContFormer achieves 8.75% absolute improvement on Accu.@0.6.
Self-Supervised Monocular Depth Estimation: Solving the Edge-Fattening Problem
Oct 04, 2022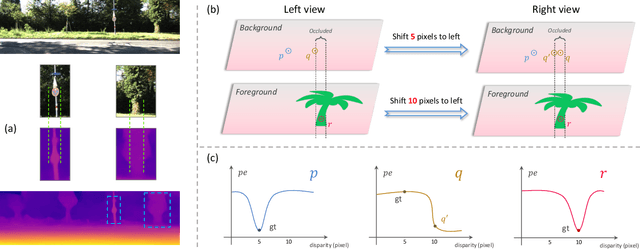
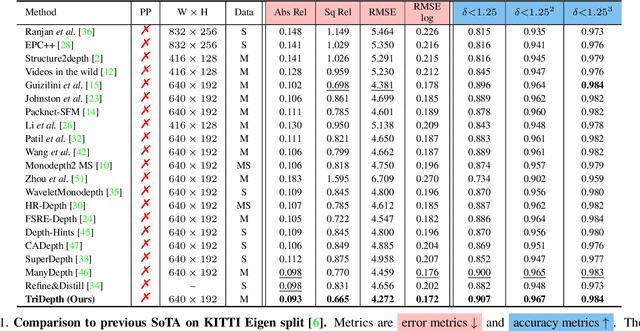
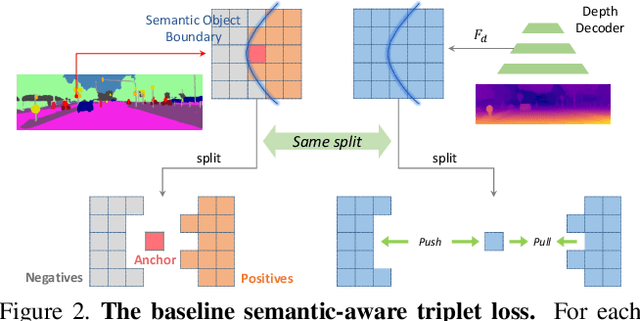
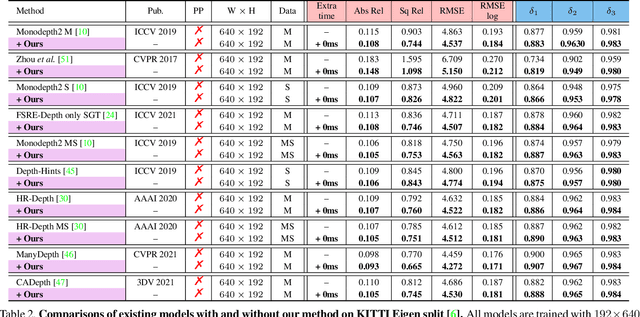
Self-supervised monocular depth estimation (MDE) models universally suffer from the notorious edge-fattening issue. Triplet loss, popular for metric learning, has made a great success in many computer vision tasks. In this paper, we redesign the patch-based triplet loss in MDE to alleviate the ubiquitous edge-fattening issue. We show two drawbacks of the raw triplet loss in MDE and demonstrate our problem-driven redesigns. First, we present a min. operator based strategy applied to all negative samples, to prevent well-performing negatives sheltering the error of edge-fattening negatives. Second, we split the anchor-positive distance and anchor-negative distance from within the original triplet, which directly optimizes the positives without any mutual effect with the negatives. Extensive experiments show the combination of these two small redesigns can achieve unprecedented results: Our powerful and versatile triplet loss not only makes our model outperform all previous SoTA by a large margin, but also provides substantial performance boosts to a large number of existing models, while introducing no extra inference computation at all.
Correspondence Matters for Video Referring Expression Comprehension
Jul 21, 2022


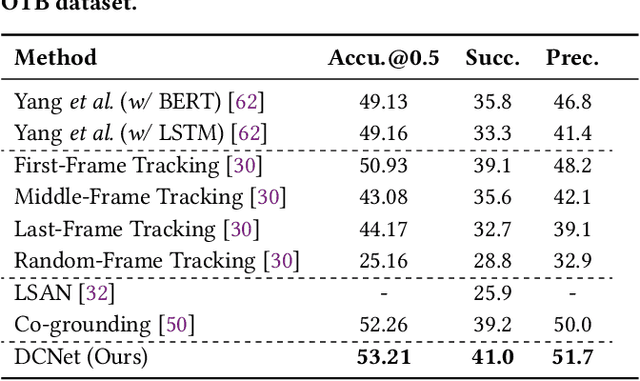
We investigate the problem of video Referring Expression Comprehension (REC), which aims to localize the referent objects described in the sentence to visual regions in the video frames. Despite the recent progress, existing methods suffer from two problems: 1) inconsistent localization results across video frames; 2) confusion between the referent and contextual objects. To this end, we propose a novel Dual Correspondence Network (dubbed as DCNet) which explicitly enhances the dense associations in both the inter-frame and cross-modal manners. Firstly, we aim to build the inter-frame correlations for all existing instances within the frames. Specifically, we compute the inter-frame patch-wise cosine similarity to estimate the dense alignment and then perform the inter-frame contrastive learning to map them close in feature space. Secondly, we propose to build the fine-grained patch-word alignment to associate each patch with certain words. Due to the lack of this kind of detailed annotations, we also predict the patch-word correspondence through the cosine similarity. Extensive experiments demonstrate that our DCNet achieves state-of-the-art performance on both video and image REC benchmarks. Furthermore, we conduct comprehensive ablation studies and thorough analyses to explore the optimal model designs. Notably, our inter-frame and cross-modal contrastive losses are plug-and-play functions and are applicable to any video REC architectures. For example, by building on top of Co-grounding, we boost the performance by 1.48% absolute improvement on Accu.@0.5 for VID-Sentence dataset.