 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWin Fast or Lose Slow: Balancing Speed and Accuracy in Latency-Sensitive Decisions of LLMs
May 26, 2025Large language models (LLMs) have shown remarkable performance across diverse reasoning and generation tasks, and are increasingly deployed as agents in dynamic environments such as code generation and recommendation systems. However, many real-world applications, such as high-frequency trading and real-time competitive gaming, require decisions under strict latency constraints, where faster responses directly translate into higher rewards. Despite the importance of this latency quality trade off, it remains underexplored in the context of LLM based agents. In this work, we present the first systematic study of this trade off in real time decision making tasks. To support our investigation, we introduce two new benchmarks: HFTBench, a high frequency trading simulation, and StreetFighter, a competitive gaming platform. Our analysis reveals that optimal latency quality balance varies by task, and that sacrificing quality for lower latency can significantly enhance downstream performance. To address this, we propose FPX, an adaptive framework that dynamically selects model size and quantization level based on real time demands. Our method achieves the best performance on both benchmarks, improving win rate by up to 80% in Street Fighter and boosting daily yield by up to 26.52% in trading, underscoring the need for latency aware evaluation and deployment strategies for LLM based agents. These results demonstrate the critical importance of latency aware evaluation and deployment strategies for real world LLM based agents. Our benchmarks are available at Latency Sensitive Benchmarks.
TLAG: An Informative Trigger and Label-Aware Knowledge Guided Model for Dialogue-based Relation Extraction
Mar 30, 2023Dialogue-based Relation Extraction (DRE) aims to predict the relation type of argument pairs that are mentioned in dialogue. The latest trigger-enhanced methods propose trigger prediction tasks to promote DRE. However, these methods are not able to fully leverage the trigger information and even bring noise to relation extraction. To solve these problems, we propose TLAG, which fully leverages the trigger and label-aware knowledge to guide the relation extraction. First, we design an adaptive trigger fusion module to fully leverage the trigger information. Then, we introduce label-aware knowledge to further promote our model's performance. Experimental results on the DialogRE dataset show that our TLAG outperforms the baseline models, and detailed analyses demonstrate the effectiveness of our approach.
FiTs: Fine-grained Two-stage Training for Knowledge-aware Question Answering
Mar 15, 2023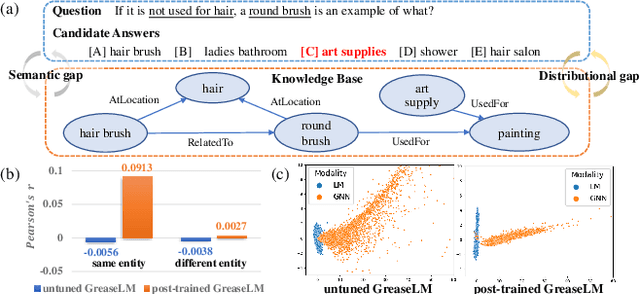

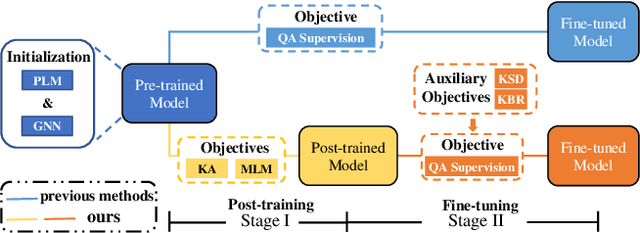

Knowledge-aware question answering (KAQA) requires the model to answer questions over a knowledge base, which is essential for both open-domain QA and domain-specific QA, especially when language models alone cannot provide all the knowledge needed. Despite the promising result of recent KAQA systems which tend to integrate linguistic knowledge from pre-trained language models (PLM) and factual knowledge from knowledge graphs (KG) to answer complex questions, a bottleneck exists in effectively fusing the representations from PLMs and KGs because of (i) the semantic and distributional gaps between them, and (ii) the difficulties in joint reasoning over the provided knowledge from both modalities. To address the above two problems, we propose a Fine-grained Two-stage training framework (FiTs) to boost the KAQA system performance: The first stage aims at aligning representations from the PLM and the KG, thus bridging the modality gaps between them, named knowledge adaptive post-training. The second stage, called knowledge-aware fine-tuning, aims to improve the model's joint reasoning ability based on the aligned representations. In detail, we fine-tune the post-trained model via two auxiliary self-supervised tasks in addition to the QA supervision. Extensive experiments demonstrate that our approach achieves state-of-the-art performance on three benchmarks in the commonsense reasoning (i.e., CommonsenseQA, OpenbookQA) and medical question answering (i.e., MedQA-USMILE) domains.
FTM: A Frame-level Timeline Modeling Method for Temporal Graph Representation Learning
Mar 15, 2023

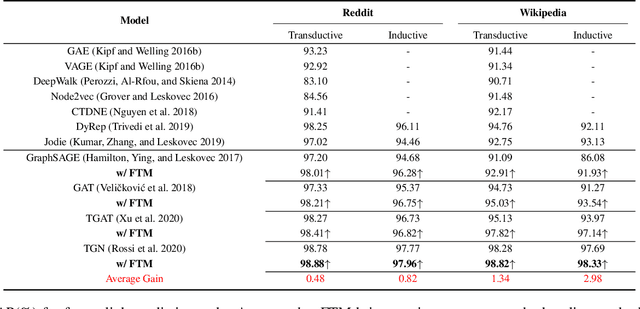
Learning representations for graph-structured data is essential for graph analytical tasks. While remarkable progress has been made on static graphs, researches on temporal graphs are still in its beginning stage. The bottleneck of the temporal graph representation learning approach is the neighborhood aggregation strategy, based on which graph attributes share and gather information explicitly. Existing neighborhood aggregation strategies fail to capture either the short-term features or the long-term features of temporal graph attributes, leading to unsatisfactory model performance and even poor robustness and domain generality of the representation learning method. To address this problem, we propose a Frame-level Timeline Modeling (FTM) method that helps to capture both short-term and long-term features and thus learns more informative representations on temporal graphs. In particular, we present a novel link-based framing technique to preserve the short-term features and then incorporate a timeline aggregator module to capture the intrinsic dynamics of graph evolution as long-term features. Our method can be easily assembled with most temporal GNNs. Extensive experiments on common datasets show that our method brings great improvements to the capability, robustness, and domain generality of backbone methods in downstream tasks. Our code can be found at https://github.com/yeeeqichen/FTM.
A Dynamic Graph Interactive Framework with Label-Semantic Injection for Spoken Language Understanding
Nov 08, 2022Multi-intent detection and slot filling joint models are gaining increasing traction since they are closer to complicated real-world scenarios. However, existing approaches (1) focus on identifying implicit correlations between utterances and one-hot encoded labels in both tasks while ignoring explicit label characteristics; (2) directly incorporate multi-intent information for each token, which could lead to incorrect slot prediction due to the introduction of irrelevant intent. In this paper, we propose a framework termed DGIF, which first leverages the semantic information of labels to give the model additional signals and enriched priors. Then, a multi-grain interactive graph is constructed to model correlations between intents and slots. Specifically, we propose a novel approach to construct the interactive graph based on the injection of label semantics, which can automatically update the graph to better alleviate error propagation. Experimental results show that our framework significantly outperforms existing approaches, obtaining a relative improvement of 13.7% over the previous best model on the MixATIS dataset in overall accuracy.