 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDIFFA-2: A Practical Diffusion Large Language Model for General Audio Understanding
Jan 30, 2026Autoregressive (AR) large audio language models (LALMs) such as Qwen-2.5-Omni have achieved strong performance on audio understanding and interaction, but scaling them remains costly in data and computation, and strictly sequential decoding limits inference efficiency. Diffusion large language models (dLLMs) have recently been shown to make effective use of limited training data, and prior work on DIFFA indicates that replacing an AR backbone with a diffusion counterpart can substantially improve audio understanding under matched settings, albeit at a proof-of-concept scale without large-scale instruction tuning, preference alignment, or practical decoding schemes. We introduce DIFFA-2, a practical diffusion-based LALM for general audio understanding. DIFFA-2 upgrades the speech encoder, employs dual semantic and acoustic adapters, and is trained with a four-stage curriculum that combines semantic and acoustic alignment, large-scale supervised fine-tuning, and variance-reduced preference optimization, using only fully open-source corpora. Experiments on MMSU, MMAU, and MMAR show that DIFFA-2 consistently improves over DIFFA and is competitive to strong AR LALMs under practical training budgets, supporting diffusion-based modeling is a viable backbone for large-scale audio understanding. Our code is available at https://github.com/NKU-HLT/DIFFA.git.
Reflecting Twice before Speaking with Empathy: Self-Reflective Alternating Inference for Empathy-Aware End-to-End Spoken Dialogue
Jan 26, 2026End-to-end Spoken Language Models (SLMs) hold great potential for paralinguistic perception, and numerous studies have aimed to enhance their capabilities, particularly for empathetic dialogue. However, current approaches largely depend on rigid supervised signals, such as ground-truth response in supervised fine-tuning or preference scores in reinforcement learning. Such reliance is fundamentally limited for modeling complex empathy, as there is no single "correct" response and a simple numerical score cannot fully capture the nuances of emotional expression or the appropriateness of empathetic behavior. To address these limitations, we sequentially introduce EmpathyEval, a descriptive natural-language-based evaluation model for assessing empathetic quality in spoken dialogues. Building upon EmpathyEval, we propose ReEmpathy, an end-to-end SLM that enhances empathetic dialogue through a novel Empathetic Self-Reflective Alternating Inference mechanism, which interleaves spoken response generation with free-form, empathy-related reflective reasoning. Extensive experiments demonstrate that ReEmpathy substantially improves empathy-sensitive spoken dialogue by enabling reflective reasoning, offering a promising approach toward more emotionally intelligent and empathy-aware human-computer interactions.
In-N-On: Scaling Egocentric Manipulation with in-the-wild and on-task Data
Nov 19, 2025Egocentric videos are a valuable and scalable data source to learn manipulation policies. However, due to significant data heterogeneity, most existing approaches utilize human data for simple pre-training, which does not unlock its full potential. This paper first provides a scalable recipe for collecting and using egocentric data by categorizing human data into two categories: in-the-wild and on-task alongside with systematic analysis on how to use the data. We first curate a dataset, PHSD, which contains over 1,000 hours of diverse in-the-wild egocentric data and over 20 hours of on-task data directly aligned to the target manipulation tasks. This enables learning a large egocentric language-conditioned flow matching policy, Human0. With domain adaptation techniques, Human0 minimizes the gap between humans and humanoids. Empirically, we show Human0 achieves several novel properties from scaling human data, including language following of instructions from only human data, few-shot learning, and improved robustness using on-task data. Project website: https://xiongyicai.github.io/In-N-On/
HMC: Learning Heterogeneous Meta-Control for Contact-Rich Loco-Manipulation
Nov 18, 2025



Learning from real-world robot demonstrations holds promise for interacting with complex real-world environments. However, the complexity and variability of interaction dynamics often cause purely positional controllers to struggle with contacts or varying payloads. To address this, we propose a Heterogeneous Meta-Control (HMC) framework for Loco-Manipulation that adaptively stitches multiple control modalities: position, impedance, and hybrid force-position. We first introduce an interface, HMC-Controller, for blending actions from different control profiles continuously in the torque space. HMC-Controller facilitates both teleoperation and policy deployment. Then, to learn a robust force-aware policy, we propose HMC-Policy to unify different controllers into a heterogeneous architecture. We adopt a mixture-of-experts style routing to learn from large-scale position-only data and fine-grained force-aware demonstrations. Experiments on a real humanoid robot show over 50% relative improvement vs. baselines on challenging tasks such as compliant table wiping and drawer opening, demonstrating the efficacy of HMC.
GMT: General Motion Tracking for Humanoid Whole-Body Control
Jun 17, 2025The ability to track general whole-body motions in the real world is a useful way to build general-purpose humanoid robots. However, achieving this can be challenging due to the temporal and kinematic diversity of the motions, the policy's capability, and the difficulty of coordination of the upper and lower bodies. To address these issues, we propose GMT, a general and scalable motion-tracking framework that trains a single unified policy to enable humanoid robots to track diverse motions in the real world. GMT is built upon two core components: an Adaptive Sampling strategy and a Motion Mixture-of-Experts (MoE) architecture. The Adaptive Sampling automatically balances easy and difficult motions during training. The MoE ensures better specialization of different regions of the motion manifold. We show through extensive experiments in both simulation and the real world the effectiveness of GMT, achieving state-of-the-art performance across a broad spectrum of motions using a unified general policy. Videos and additional information can be found at https://gmt-humanoid.github.io.
AMO: Adaptive Motion Optimization for Hyper-Dexterous Humanoid Whole-Body Control
May 06, 2025Humanoid robots derive much of their dexterity from hyper-dexterous whole-body movements, enabling tasks that require a large operational workspace: such as picking objects off the ground. However, achieving these capabilities on real humanoids remains challenging due to their high degrees of freedom (DoF) and nonlinear dynamics. We propose Adaptive Motion Optimization (AMO), a framework that integrates sim-to-real reinforcement learning (RL) with trajectory optimization for real-time, adaptive whole-body control. To mitigate distribution bias in motion imitation RL, we construct a hybrid AMO dataset and train a network capable of robust, on-demand adaptation to potentially O.O.D. commands. We validate AMO in simulation and on a 29-DoF Unitree G1 humanoid robot, demonstrating superior stability and an expanded workspace compared to strong baselines. Finally, we show that AMO's consistent performance supports autonomous task execution via imitation learning, underscoring the system's versatility and robustness.
Kongzi: A Historical Large Language Model with Fact Enhancement
Apr 13, 2025The capabilities of the latest large language models (LLMs) have been extended from pure natural language understanding to complex reasoning tasks. However, current reasoning models often exhibit factual inaccuracies in longer reasoning chains, which poses challenges for historical reasoning and limits the potential of LLMs in complex, knowledge-intensive tasks. Historical studies require not only the accurate presentation of factual information but also the ability to establish cross-temporal correlations and derive coherent conclusions from fragmentary and often ambiguous sources. To address these challenges, we propose Kongzi, a large language model specifically designed for historical analysis. Through the integration of curated, high-quality historical data and a novel fact-reinforcement learning strategy, Kongzi demonstrates strong factual alignment and sophisticated reasoning depth. Extensive experiments on tasks such as historical question answering and narrative generation demonstrate that Kongzi outperforms existing models in both factual accuracy and reasoning depth. By effectively addressing the unique challenges inherent in historical texts, Kongzi sets a new standard for the development of accurate and reliable LLMs in professional domains.
Humanoid Policy ~ Human Policy
Mar 17, 2025Training manipulation policies for humanoid robots with diverse data enhances their robustness and generalization across tasks and platforms. However, learning solely from robot demonstrations is labor-intensive, requiring expensive tele-operated data collection which is difficult to scale. This paper investigates a more scalable data source, egocentric human demonstrations, to serve as cross-embodiment training data for robot learning. We mitigate the embodiment gap between humanoids and humans from both the data and modeling perspectives. We collect an egocentric task-oriented dataset (PH2D) that is directly aligned with humanoid manipulation demonstrations. We then train a human-humanoid behavior policy, which we term Human Action Transformer (HAT). The state-action space of HAT is unified for both humans and humanoid robots and can be differentiably retargeted to robot actions. Co-trained with smaller-scale robot data, HAT directly models humanoid robots and humans as different embodiments without additional supervision. We show that human data improves both generalization and robustness of HAT with significantly better data collection efficiency. Code and data: https://human-as-robot.github.io/
ExBody2: Advanced Expressive Humanoid Whole-Body Control
Dec 17, 2024This paper enables real-world humanoid robots to maintain stability while performing expressive motions like humans do. We propose ExBody2, a generalized whole-body tracking framework that can take any reference motion inputs and control the humanoid to mimic the motion. The model is trained in simulation with Reinforcement Learning and then transferred to the real world. It decouples keypoint tracking with velocity control, and effectively leverages a privileged teacher policy to distill precise mimic skills into the target student policy, which enables high-fidelity replication of dynamic movements such as running, crouching, dancing, and other challenging motions. We present a comprehensive qualitative and quantitative analysis of crucial design factors in the paper. We conduct our experiments on two humanoid platforms and demonstrate the superiority of our approach against state-of-the-arts, providing practical guidelines to pursue the extreme of whole-body control for humanoid robots.
DisPose: Disentangling Pose Guidance for Controllable Human Image Animation
Dec 13, 2024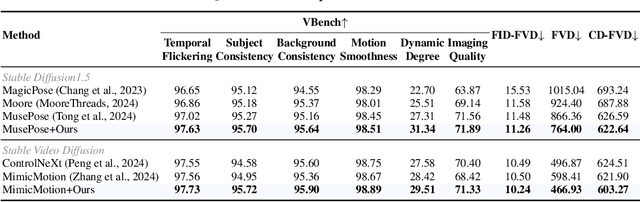
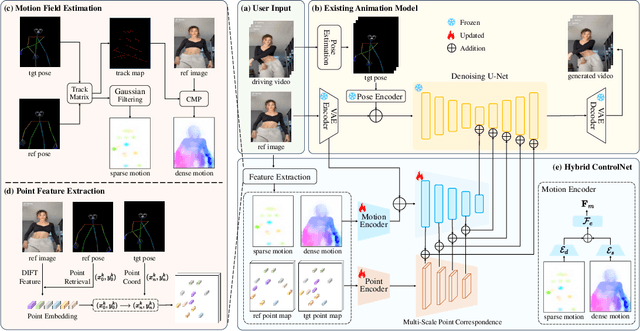
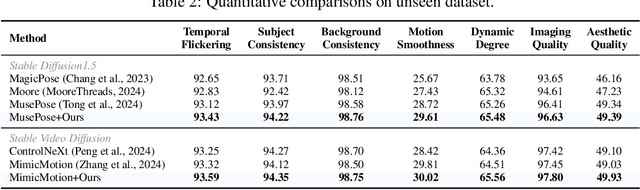

Controllable human image animation aims to generate videos from reference images using driving videos. Due to the limited control signals provided by sparse guidance (e.g., skeleton pose), recent works have attempted to introduce additional dense conditions (e.g., depth map) to ensure motion alignment. However, such strict dense guidance impairs the quality of the generated video when the body shape of the reference character differs significantly from that of the driving video. In this paper, we present DisPose to mine more generalizable and effective control signals without additional dense input, which disentangles the sparse skeleton pose in human image animation into motion field guidance and keypoint correspondence. Specifically, we generate a dense motion field from a sparse motion field and the reference image, which provides region-level dense guidance while maintaining the generalization of the sparse pose control. We also extract diffusion features corresponding to pose keypoints from the reference image, and then these point features are transferred to the target pose to provide distinct identity information. To seamlessly integrate into existing models, we propose a plug-and-play hybrid ControlNet that improves the quality and consistency of generated videos while freezing the existing model parameters. Extensive qualitative and quantitative experiments demonstrate the superiority of DisPose compared to current methods. Code: \href{https://github.com/lihxxx/DisPose}{https://github.com/lihxxx/DisPose}.