 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeXAI4Extremes: An interpretable machine learning framework for understanding extreme-weather precursors under climate change
Mar 11, 2025Extreme weather events are increasing in frequency and intensity due to climate change. This, in turn, is exacting a significant toll in communities worldwide. While prediction skills are increasing with advances in numerical weather prediction and artificial intelligence tools, extreme weather still present challenges. More specifically, identifying the precursors of such extreme weather events and how these precursors may evolve under climate change remain unclear. In this paper, we propose to use post-hoc interpretability methods to construct relevance weather maps that show the key extreme-weather precursors identified by deep learning models. We then compare this machine view with existing domain knowledge to understand whether deep learning models identified patterns in data that may enrich our understanding of extreme-weather precursors. We finally bin these relevant maps into different multi-year time periods to understand the role that climate change is having on these precursors. The experiments are carried out on Indochina heatwaves, but the methodology can be readily extended to other extreme weather events worldwide.
CondensNet: Enabling stable long-term climate simulations via hybrid deep learning models with adaptive physical constraints
Feb 18, 2025Accurate and efficient climate simulations are crucial for understanding Earth's evolving climate. However, current general circulation models (GCMs) face challenges in capturing unresolved physical processes, such as cloud and convection. A common solution is to adopt cloud resolving models, that provide more accurate results than the standard subgrid parametrisation schemes typically used in GCMs. However, cloud resolving models, also referred to as super paramtetrizations, remain computationally prohibitive. Hybrid modeling, which integrates deep learning with equation-based GCMs, offers a promising alternative but often struggles with long-term stability and accuracy issues. In this work, we find that water vapor oversaturation during condensation is a key factor compromising the stability of hybrid models. To address this, we introduce CondensNet, a novel neural network architecture that embeds a self-adaptive physical constraint to correct unphysical condensation processes. CondensNet effectively mitigates water vapor oversaturation, enhancing simulation stability while maintaining accuracy and improving computational efficiency compared to super parameterization schemes. We integrate CondensNet into a GCM to form PCNN-GCM (Physics-Constrained Neural Network GCM), a hybrid deep learning framework designed for long-term stable climate simulations in real-world conditions, including ocean and land. PCNN-GCM represents a significant milestone in hybrid climate modeling, as it shows a novel way to incorporate physical constraints adaptively, paving the way for accurate, lightweight, and stable long-term climate simulations.
PneumoLLM: Harnessing the Power of Large Language Model for Pneumoconiosis Diagnosis
Dec 08, 2023The conventional pretraining-and-finetuning paradigm, while effective for common diseases with ample data, faces challenges in diagnosing data-scarce occupational diseases like pneumoconiosis. Recently, large language models (LLMs) have exhibits unprecedented ability when conducting multiple tasks in dialogue, bringing opportunities to diagnosis. A common strategy might involve using adapter layers for vision-language alignment and diagnosis in a dialogic manner. Yet, this approach often requires optimization of extensive learnable parameters in the text branch and the dialogue head, potentially diminishing the LLMs' efficacy, especially with limited training data. In our work, we innovate by eliminating the text branch and substituting the dialogue head with a classification head. This approach presents a more effective method for harnessing LLMs in diagnosis with fewer learnable parameters. Furthermore, to balance the retention of detailed image information with progression towards accurate diagnosis, we introduce the contextual multi-token engine. This engine is specialized in adaptively generating diagnostic tokens. Additionally, we propose the information emitter module, which unidirectionally emits information from image tokens to diagnosis tokens. Comprehensive experiments validate the superiority of our methods and the effectiveness of proposed modules. Our codes can be found at https://github.com/CodeMonsterPHD/PneumoLLM/tree/main.
Determination of building flood risk maps from LiDAR mobile mapping data
Jan 14, 2022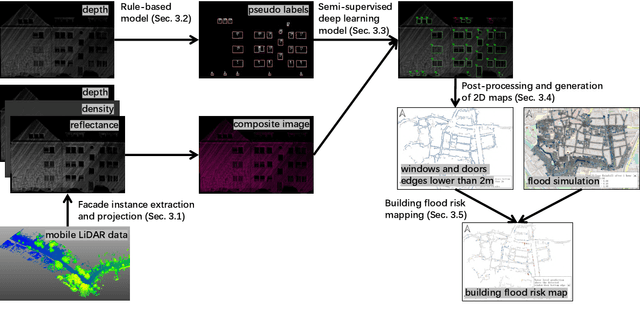
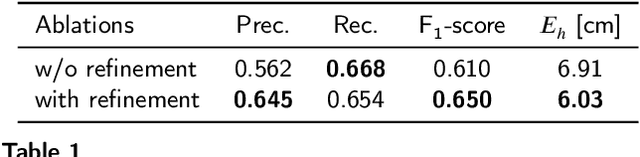
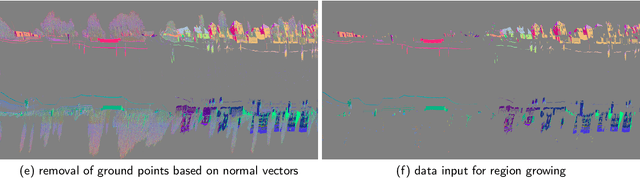
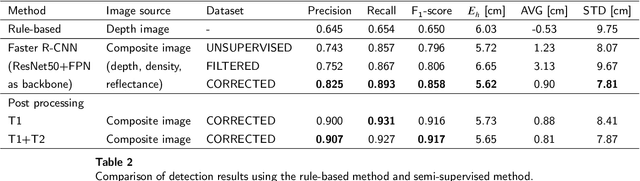
With increasing urbanization, flooding is a major challenge for many cities today. Based on forecast precipitation, topography, and pipe networks, flood simulations can provide early warnings for areas and buildings at risk of flooding. Basement windows, doors, and underground garage entrances are common places where floodwater can flow into a building. Some buildings have been prepared or designed considering the threat of flooding, but others have not. Therefore, knowing the heights of these facade openings helps to identify places that are more susceptible to water ingress. However, such data is not yet readily available in most cities. Traditional surveying of the desired targets may be used, but this is a very time-consuming and laborious process. This research presents a new process for the extraction of windows and doors from LiDAR mobile mapping data. Deep learning object detection models are trained to identify these objects. Usually, this requires to provide large amounts of manual annotations. In this paper, we mitigate this problem by leveraging a rule-based method. In a first step, the rule-based method is used to generate pseudo-labels. A semi-supervised learning strategy is then applied with three different levels of supervision. The results show that using only automatically generated pseudo-labels, the learning-based model outperforms the rule-based approach by 14.6% in terms of F1-score. After five hours of human supervision, it is possible to improve the model by another 6.2%. By comparing the detected facade openings' heights with the predicted water levels from a flood simulation model, a map can be produced which assigns per-building flood risk levels. This information can be combined with flood forecasting to provide a more targeted disaster prevention guide for the city's infrastructure and residential buildings.