 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePneumoLLM: Harnessing the Power of Large Language Model for Pneumoconiosis Diagnosis
Dec 08, 2023The conventional pretraining-and-finetuning paradigm, while effective for common diseases with ample data, faces challenges in diagnosing data-scarce occupational diseases like pneumoconiosis. Recently, large language models (LLMs) have exhibits unprecedented ability when conducting multiple tasks in dialogue, bringing opportunities to diagnosis. A common strategy might involve using adapter layers for vision-language alignment and diagnosis in a dialogic manner. Yet, this approach often requires optimization of extensive learnable parameters in the text branch and the dialogue head, potentially diminishing the LLMs' efficacy, especially with limited training data. In our work, we innovate by eliminating the text branch and substituting the dialogue head with a classification head. This approach presents a more effective method for harnessing LLMs in diagnosis with fewer learnable parameters. Furthermore, to balance the retention of detailed image information with progression towards accurate diagnosis, we introduce the contextual multi-token engine. This engine is specialized in adaptively generating diagnostic tokens. Additionally, we propose the information emitter module, which unidirectionally emits information from image tokens to diagnosis tokens. Comprehensive experiments validate the superiority of our methods and the effectiveness of proposed modules. Our codes can be found at https://github.com/CodeMonsterPHD/PneumoLLM/tree/main.
Adversarial Counterfactual Environment Model Learning
Jun 10, 2022

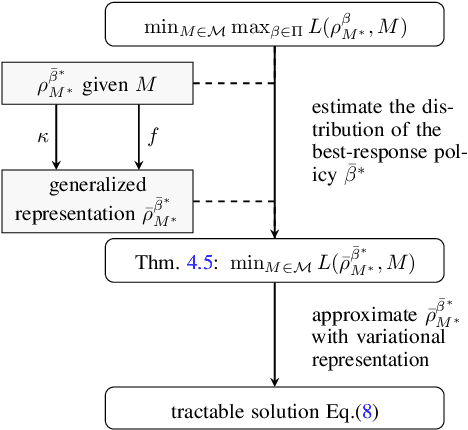

A good model for action-effect prediction, named environment model, is important to achieve sample-efficient decision-making policy learning in many domains like robot control, recommender systems, and patients' treatment selection. We can take unlimited trials with such a model to identify the appropriate actions so that the costs of queries in the real world can be saved. It requires the model to handle unseen data correctly, also called counterfactual data. However, standard data fitting techniques do not automatically achieve such generalization ability and commonly result in unreliable models. In this work, we introduce counterfactual-query risk minimization (CQRM) in model learning for generalizing to a counterfactual dataset queried by a specific target policy. Since the target policies can be various and unknown in policy learning, we propose an adversarial CQRM objective in which the model learns on counterfactual data queried by adversarial policies, and finally derive a tractable solution GALILEO. We also discover that adversarial CQRM is closely related to the adversarial model learning, explaining the effectiveness of the latter. We apply GALILEO in synthetic tasks and a real-world application. The results show that GALILEO makes accurate predictions on counterfactual data and thus significantly improves policies in real-world testing.