 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDANS-KGC: Diffusion Based Adaptive Negative Sampling for Knowledge Graph Completion
Nov 11, 2025Negative sampling (NS) strategies play a crucial role in knowledge graph representation. In order to overcome the limitations of existing negative sampling strategies, such as vulnerability to false negatives, limited generalization, and lack of control over sample hardness, we propose DANS-KGC (Diffusion-based Adaptive Negative Sampling for Knowledge Graph Completion). DANS-KGC comprises three key components: the Difficulty Assessment Module (DAM), the Adaptive Negative Sampling Module (ANS), and the Dynamic Training Mechanism (DTM). DAM evaluates the learning difficulty of entities by integrating semantic and structural features. Based on this assessment, ANS employs a conditional diffusion model with difficulty-aware noise scheduling, leveraging semantic and neighborhood information during the denoising phase to generate negative samples of diverse hardness. DTM further enhances learning by dynamically adjusting the hardness distribution of negative samples throughout training, enabling a curriculum-style progression from easy to hard examples. Extensive experiments on six benchmark datasets demonstrate the effectiveness and generalization ability of DANS-KGC, with the method achieving state-of-the-art results on all three evaluation metrics for the UMLS and YAGO3-10 datasets.
EchoVLM: Dynamic Mixture-of-Experts Vision-Language Model for Universal Ultrasound Intelligence
Sep 18, 2025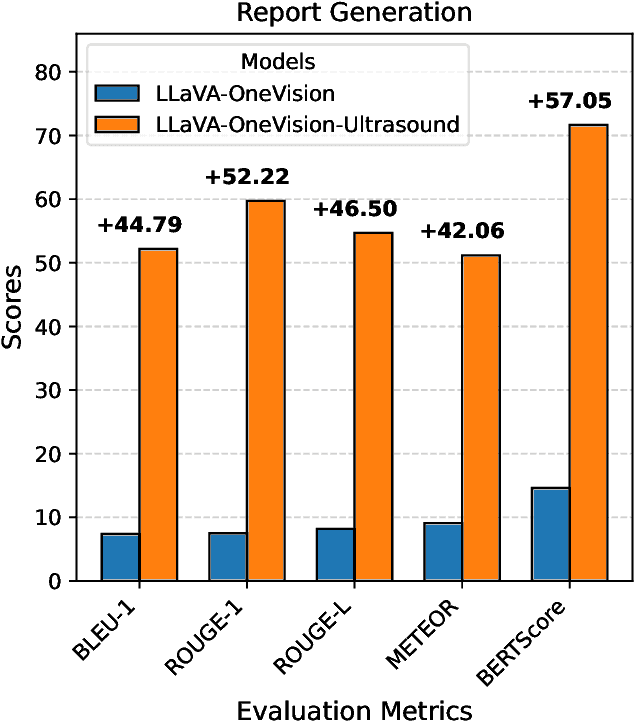

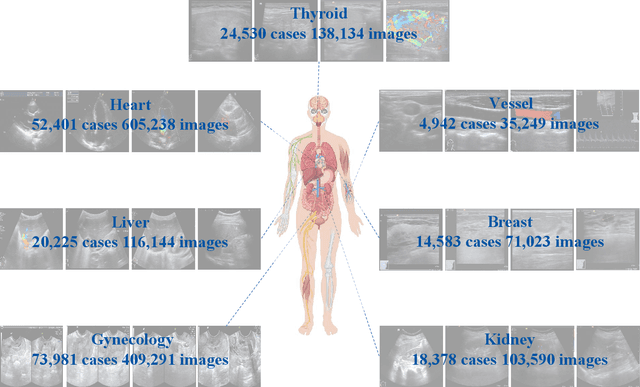

Ultrasound imaging has become the preferred imaging modality for early cancer screening due to its advantages of non-ionizing radiation, low cost, and real-time imaging capabilities. However, conventional ultrasound diagnosis heavily relies on physician expertise, presenting challenges of high subjectivity and low diagnostic efficiency. Vision-language models (VLMs) offer promising solutions for this issue, but existing general-purpose models demonstrate limited knowledge in ultrasound medical tasks, with poor generalization in multi-organ lesion recognition and low efficiency across multi-task diagnostics. To address these limitations, we propose EchoVLM, a vision-language model specifically designed for ultrasound medical imaging. The model employs a Mixture of Experts (MoE) architecture trained on data spanning seven anatomical regions. This design enables the model to perform multiple tasks, including ultrasound report generation, diagnosis and visual question-answering (VQA). The experimental results demonstrated that EchoVLM achieved significant improvements of 10.15 and 4.77 points in BLEU-1 scores and ROUGE-1 scores respectively compared to Qwen2-VL on the ultrasound report generation task. These findings suggest that EchoVLM has substantial potential to enhance diagnostic accuracy in ultrasound imaging, thereby providing a viable technical solution for future clinical applications. Source code and model weights are available at https://github.com/Asunatan/EchoVLM.
A Retrospective Systematic Study on Hierarchical Sparse Query Transformer-assisted Ultrasound Screening for Early Hepatocellular Carcinoma
Feb 06, 2025Hepatocellular carcinoma (HCC) ranks as the third leading cause of cancer-related mortality worldwide, with early detection being crucial for improving patient survival rates. However, early screening for HCC using ultrasound suffers from insufficient sensitivity and is highly dependent on the expertise of radiologists for interpretation. Leveraging the latest advancements in artificial intelligence (AI) in medical imaging, this study proposes an innovative Hierarchical Sparse Query Transformer (HSQformer) model that combines the strengths of Convolutional Neural Networks (CNNs) and Vision Transformers (ViTs) to enhance the accuracy of HCC diagnosis in ultrasound screening. The HSQformer leverages sparse latent space representations to capture hierarchical details at various granularities without the need for complex adjustments, and adopts a modular, plug-and-play design philosophy, ensuring the model's versatility and ease of use. The HSQformer's performance was rigorously tested across three distinct clinical scenarios: single-center, multi-center, and high-risk patient testing. In each of these settings, it consistently outperformed existing state-of-the-art models, such as ConvNext and SwinTransformer. Notably, the HSQformer even matched the diagnostic capabilities of senior radiologists and comprehensively surpassed those of junior radiologists. The experimental results from this study strongly demonstrate the effectiveness and clinical potential of AI-assisted tools in HCC screening. The full code is available at https://github.com/Asunatan/HSQformer.
LM-Net: A Light-weight and Multi-scale Network for Medical Image Segmentation
Jan 07, 2025Current medical image segmentation approaches have limitations in deeply exploring multi-scale information and effectively combining local detail textures with global contextual semantic information. This results in over-segmentation, under-segmentation, and blurred segmentation boundaries. To tackle these challenges, we explore multi-scale feature representations from different perspectives, proposing a novel, lightweight, and multi-scale architecture (LM-Net) that integrates advantages of both Convolutional Neural Networks (CNNs) and Vision Transformers (ViTs) to enhance segmentation accuracy. LM-Net employs a lightweight multi-branch module to capture multi-scale features at the same level. Furthermore, we introduce two modules to concurrently capture local detail textures and global semantics with multi-scale features at different levels: the Local Feature Transformer (LFT) and Global Feature Transformer (GFT). The LFT integrates local window self-attention to capture local detail textures, while the GFT leverages global self-attention to capture global contextual semantics. By combining these modules, our model achieves complementarity between local and global representations, alleviating the problem of blurred segmentation boundaries in medical image segmentation. To evaluate the feasibility of LM-Net, extensive experiments have been conducted on three publicly available datasets with different modalities. Our proposed model achieves state-of-the-art results, surpassing previous methods, while only requiring 4.66G FLOPs and 5.4M parameters. These state-of-the-art results on three datasets with different modalities demonstrate the effectiveness and adaptability of our proposed LM-Net for various medical image segmentation tasks.
Autonomous Decision Making for UAV Cooperative Pursuit-Evasion Game with Reinforcement Learning
Nov 05, 2024

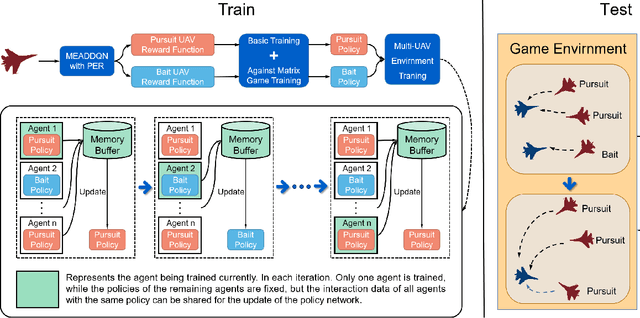
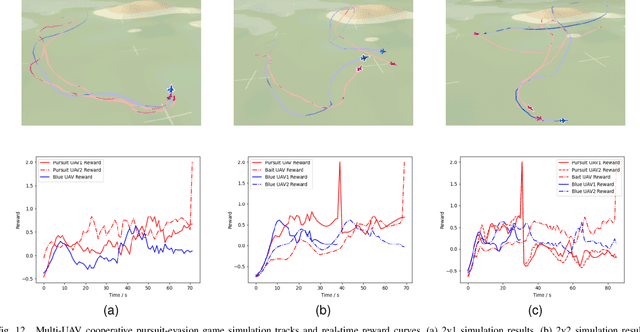
The application of intelligent decision-making in unmanned aerial vehicle (UAV) is increasing, and with the development of UAV 1v1 pursuit-evasion game, multi-UAV cooperative game has emerged as a new challenge. This paper proposes a deep reinforcement learning-based model for decision-making in multi-role UAV cooperative pursuit-evasion game, to address the challenge of enabling UAV to autonomously make decisions in complex game environments. In order to enhance the training efficiency of the reinforcement learning algorithm in UAV pursuit-evasion game environment that has high-dimensional state-action space, this paper proposes multi-environment asynchronous double deep Q-network with priority experience replay algorithm to effectively train the UAV's game policy. Furthermore, aiming to improve cooperation ability and task completion efficiency, as well as minimize the cost of UAVs in the pursuit-evasion game, this paper focuses on the allocation of roles and targets within multi-UAV environment. The cooperative game decision model with varying numbers of UAVs are obtained by assigning diverse tasks and roles to the UAVs in different scenarios. The simulation results demonstrate that the proposed method enables autonomous decision-making of the UAVs in pursuit-evasion game scenarios and exhibits significant capabilities in cooperation.
Employing Iterative Feature Selection in Fuzzy Rule-Based Binary Classification
Jan 26, 2024



The feature selection in a traditional binary classification algorithm is always used in the stage of dataset preprocessing, which makes the obtained features not necessarily the best ones for the classification algorithm, thus affecting the classification performance. For a traditional rule-based binary classification algorithm, classification rules are usually deterministic, which results in the fuzzy information contained in the rules being ignored. To do so, this paper employs iterative feature selection in fuzzy rule-based binary classification. The proposed algorithm combines feature selection based on fuzzy correlation family with rule mining based on biclustering. It first conducts biclustering on the dataset after feature selection. Then it conducts feature selection again for the biclusters according to the feedback of biclusters evaluation. In this way, an iterative feature selection framework is build. During the iteration process, it stops until the obtained bicluster meets the requirements. In addition, the rule membership function is introduced to extract vectorized fuzzy rules from the bicluster and construct weak classifiers. The weak classifiers with good classification performance are selected by Adaptive Boosting and the strong classifier is constructed by "weighted average". Finally, we perform the proposed algorithm on different datasets and compare it with other peers. Experimental results show that it achieves good classification performance and outperforms its peers.
Knowledge Pyramid: A Novel Hierarchical Reasoning Structure for Generalized Knowledge Augmentation and Inference
Jan 17, 2024Knowledge graph (KG) based reasoning has been regarded as an effective means for the analysis of semantic networks and is of great usefulness in areas of information retrieval, recommendation, decision-making, and man-machine interaction. It is widely used in recommendation, decision-making, question-answering, search, and other fields. However, previous studies mainly used low-level knowledge in the KG for reasoning, which may result in insufficient generalization and poor robustness of reasoning. To this end, this paper proposes a new inference approach using a novel knowledge augmentation strategy to improve the generalization capability of KG. This framework extracts high-level pyramidal knowledge from low-level knowledge and applies it to reasoning in a multi-level hierarchical KG, called knowledge pyramid in this paper. We tested some medical data sets using the proposed approach, and the experimental results show that the proposed knowledge pyramid has improved the knowledge inference performance with better generalization. Especially, when there are fewer training samples, the inference accuracy can be significantly improved.
PneumoLLM: Harnessing the Power of Large Language Model for Pneumoconiosis Diagnosis
Dec 08, 2023The conventional pretraining-and-finetuning paradigm, while effective for common diseases with ample data, faces challenges in diagnosing data-scarce occupational diseases like pneumoconiosis. Recently, large language models (LLMs) have exhibits unprecedented ability when conducting multiple tasks in dialogue, bringing opportunities to diagnosis. A common strategy might involve using adapter layers for vision-language alignment and diagnosis in a dialogic manner. Yet, this approach often requires optimization of extensive learnable parameters in the text branch and the dialogue head, potentially diminishing the LLMs' efficacy, especially with limited training data. In our work, we innovate by eliminating the text branch and substituting the dialogue head with a classification head. This approach presents a more effective method for harnessing LLMs in diagnosis with fewer learnable parameters. Furthermore, to balance the retention of detailed image information with progression towards accurate diagnosis, we introduce the contextual multi-token engine. This engine is specialized in adaptively generating diagnostic tokens. Additionally, we propose the information emitter module, which unidirectionally emits information from image tokens to diagnosis tokens. Comprehensive experiments validate the superiority of our methods and the effectiveness of proposed modules. Our codes can be found at https://github.com/CodeMonsterPHD/PneumoLLM/tree/main.
SwG-former: Sliding-window Graph Convolutional Network Integrated with Conformer for Sound Event Localization and Detection
Oct 21, 2023Sound event localization and detection (SELD) is a joint task of sound event detection (SED) and direction of arrival (DoA) estimation. SED mainly relies on temporal dependencies to distinguish different sound classes, while DoA estimation depends on spatial correlations to estimate source directions. To jointly optimize two subtasks, the SELD system should extract spatial correlations and model temporal dependencies simultaneously. However, numerous models mainly extract spatial correlations and model temporal dependencies separately. In this paper, the interdependence of spatial-temporal information in audio signals is exploited for simultaneous extraction to enhance the model performance. In response, a novel graph representation leveraging graph convolutional network (GCN) in non-Euclidean space is developed to extract spatial-temporal information concurrently. A sliding-window graph (SwG) module is designed based on the graph representation. It exploits sliding-windows with different sizes to learn temporal context information and dynamically constructs graph vertices in the frequency-channel (F-C) domain to capture spatial correlations. Furthermore, as the cornerstone of message passing, a robust Conv2dAgg function is proposed and embedded into the SwG module to aggregate the features of neighbor vertices. To improve the performance of SELD in a natural spatial acoustic environment, a general and efficient SwG-former model is proposed by integrating the SwG module with the Conformer. It exhibits superior performance in comparison to recent advanced SELD models. To further validate the generality and efficiency of the SwG-former, it is seamlessly integrated into the event-independent network version 2 (EINV2) called SwG-EINV2. The SwG-EINV2 surpasses the state-of-the-art (SOTA) methods under the same acoustic environment.
Extraction of Vascular Wall in Carotid Ultrasound via a Novel Boundary-Delineation Network
Jul 28, 2022

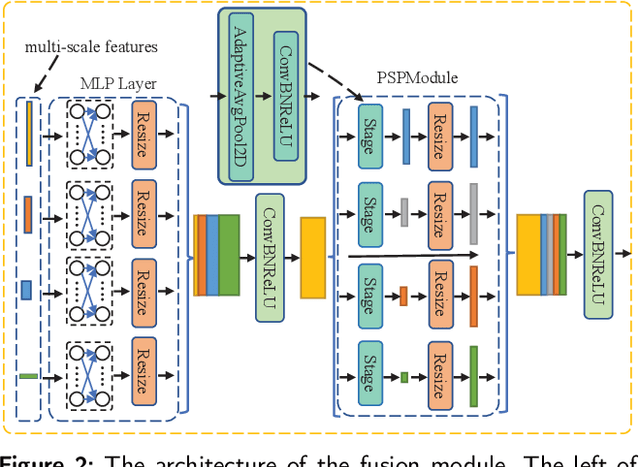
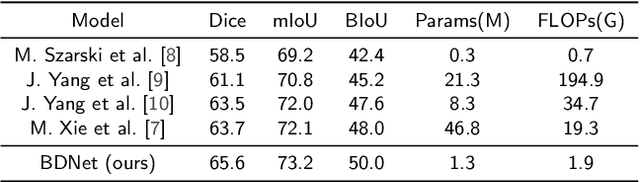
Ultrasound imaging plays an important role in the diagnosis of vascular lesions. Accurate segmentation of the vascular wall is important for the prevention, diagnosis and treatment of vascular diseases. However, existing methods have inaccurate localization of the vascular wall boundary. Segmentation errors occur in discontinuous vascular wall boundaries and dark boundaries. To overcome these problems, we propose a new boundary-delineation network (BDNet). We use the boundary refinement module to re-delineate the boundary of the vascular wall to obtain the correct boundary location. We designed the feature extraction module to extract and fuse multi-scale features and different receptive field features to solve the problem of dark boundaries and discontinuous boundaries. We use a new loss function to optimize the model. The interference of class imbalance on model optimization is prevented to obtain finer and smoother boundaries. Finally, to facilitate clinical applications, we design the model to be lightweight. Experimental results show that our model achieves the best segmentation results and significantly reduces memory consumption compared to existing models for the dataset.