 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Support Vector Approach in Segmented Regression for Map-assisted Non-cooperative Source Localization
Jan 08, 2025This paper presents a non-cooperative source localization approach based on received signal strength (RSS) and 2D environment map, considering both line-of-sight (LOS) and non-line-of-sight (NLOS) conditions. Conventional localization methods, e.g., weighted centroid localization (WCL), may perform bad. This paper proposes a segmented regression approach using 2D maps to estimate source location and propagation environment jointly. By leveraging topological information from the 2D maps, a support vector-assisted algorithm is developed to solve the segmented regression problem, separate the LOS and NLOS measurements, and estimate the location of source. The proposed method demonstrates a good localization performance with an improvement of over 30% in localization rooted mean squared error (RMSE) compared to the baseline methods.
Self-supervised Learning for Geospatial AI: A Survey
Aug 22, 2024



The proliferation of geospatial data in urban and territorial environments has significantly facilitated the development of geospatial artificial intelligence (GeoAI) across various urban applications. Given the vast yet inherently sparse labeled nature of geospatial data, there is a critical need for techniques that can effectively leverage such data without heavy reliance on labeled datasets. This requirement aligns with the principles of self-supervised learning (SSL), which has attracted increasing attention for its adoption in geospatial data. This paper conducts a comprehensive and up-to-date survey of SSL techniques applied to or developed for three primary data (geometric) types prevalent in geospatial vector data: points, polylines, and polygons. We systematically categorize various SSL techniques into predictive and contrastive methods, discussing their application with respect to each data type in enhancing generalization across various downstream tasks. Furthermore, we review the emerging trends of SSL for GeoAI, and several task-specific SSL techniques. Finally, we discuss several key challenges in the current research and outline promising directions for future investigation. By presenting a structured analysis of relevant studies, this paper aims to inspire continued advancements in the integration of SSL with GeoAI, encouraging innovative methods to harnessing the power of geospatial data.
Road Network Representation Learning with the Third Law of Geography
Jun 06, 2024Road network representation learning aims to learn compressed and effective vectorized representations for road segments that are applicable to numerous tasks. In this paper, we identify the limitations of existing methods, particularly their overemphasis on the distance effect as outlined in the First Law of Geography. In response, we propose to endow road network representation with the principles of the recent Third Law of Geography. To this end, we propose a novel graph contrastive learning framework that employs geographic configuration-aware graph augmentation and spectral negative sampling, ensuring that road segments with similar geographic configurations yield similar representations, and vice versa, aligning with the principles stated in the Third Law. The framework further fuses the Third Law with the First Law through a dual contrastive learning objective to effectively balance the implications of both laws. We evaluate our framework on two real-world datasets across three downstream tasks. The results show that the integration of the Third Law significantly improves the performance of road segment representations in downstream tasks.
LAMP: A Language Model on the Map
Mar 14, 2024Large Language Models (LLMs) are poised to play an increasingly important role in our lives, providing assistance across a wide array of tasks. In the geospatial domain, LLMs have demonstrated the ability to answer generic questions, such as identifying a country's capital; nonetheless, their utility is hindered when it comes to answering fine-grained questions about specific places, such as grocery stores or restaurants, which constitute essential aspects of people's everyday lives. This is mainly because the places in our cities haven't been systematically fed into LLMs, so as to understand and memorize them. This study introduces a novel framework for fine-tuning a pre-trained model on city-specific data, to enable it to provide accurate recommendations, while minimizing hallucinations. We share our model, LAMP, and the data used to train it. We conduct experiments to analyze its ability to correctly retrieving spatial objects, and compare it to well-known open- and closed- source language models, such as GPT-4. Finally, we explore its emerging capabilities through a case study on day planning.
Urban Region Embedding via Multi-View Contrastive Prediction
Dec 15, 2023Recently, learning urban region representations utilizing multi-modal data (information views) has become increasingly popular, for deep understanding of the distributions of various socioeconomic features in cities. However, previous methods usually blend multi-view information in a posteriors stage, falling short in learning coherent and consistent representations across different views. In this paper, we form a new pipeline to learn consistent representations across varying views, and propose the multi-view Contrastive Prediction model for urban Region embedding (ReCP), which leverages the multiple information views from point-of-interest (POI) and human mobility data. Specifically, ReCP comprises two major modules, namely an intra-view learning module utilizing contrastive learning and feature reconstruction to capture the unique information from each single view, and inter-view learning module that perceives the consistency between the two views using a contrastive prediction learning scheme. We conduct thorough experiments on two downstream tasks to assess the proposed model, i.e., land use clustering and region popularity prediction. The experimental results demonstrate that our model outperforms state-of-the-art baseline methods significantly in urban region representation learning.
SwG-former: Sliding-window Graph Convolutional Network Integrated with Conformer for Sound Event Localization and Detection
Oct 21, 2023Sound event localization and detection (SELD) is a joint task of sound event detection (SED) and direction of arrival (DoA) estimation. SED mainly relies on temporal dependencies to distinguish different sound classes, while DoA estimation depends on spatial correlations to estimate source directions. To jointly optimize two subtasks, the SELD system should extract spatial correlations and model temporal dependencies simultaneously. However, numerous models mainly extract spatial correlations and model temporal dependencies separately. In this paper, the interdependence of spatial-temporal information in audio signals is exploited for simultaneous extraction to enhance the model performance. In response, a novel graph representation leveraging graph convolutional network (GCN) in non-Euclidean space is developed to extract spatial-temporal information concurrently. A sliding-window graph (SwG) module is designed based on the graph representation. It exploits sliding-windows with different sizes to learn temporal context information and dynamically constructs graph vertices in the frequency-channel (F-C) domain to capture spatial correlations. Furthermore, as the cornerstone of message passing, a robust Conv2dAgg function is proposed and embedded into the SwG module to aggregate the features of neighbor vertices. To improve the performance of SELD in a natural spatial acoustic environment, a general and efficient SwG-former model is proposed by integrating the SwG module with the Conformer. It exhibits superior performance in comparison to recent advanced SELD models. To further validate the generality and efficiency of the SwG-former, it is seamlessly integrated into the event-independent network version 2 (EINV2) called SwG-EINV2. The SwG-EINV2 surpasses the state-of-the-art (SOTA) methods under the same acoustic environment.
CityFM: City Foundation Models to Solve Urban Challenges
Oct 01, 2023Pre-trained Foundation Models (PFMs) have ushered in a paradigm-shift in Artificial Intelligence, due to their ability to learn general-purpose representations that can be readily employed in a wide range of downstream tasks. While PFMs have been successfully adopted in various fields such as Natural Language Processing and Computer Vision, their capacity in handling geospatial data and answering urban questions remains limited. This can be attributed to the intrinsic heterogeneity of geospatial data, which encompasses different data types, including points, segments and regions, as well as multiple information modalities, such as a spatial position, visual characteristics and textual annotations. The proliferation of Volunteered Geographic Information initiatives, and the ever-increasing availability of open geospatial data sources, like OpenStreetMap, which is freely accessible globally, unveil a promising opportunity to bridge this gap. In this paper, we present CityFM, a self-supervised framework to train a foundation model within a selected geographical area of interest, such as a city. CityFM relies solely on open data from OSM, and produces multimodal representations of entities of different types, incorporating spatial, visual, and textual information. We analyse the entity representations generated using our foundation models from a qualitative perspective, and conduct quantitative experiments on road, building, and region-level downstream tasks. We compare its results to algorithms tailored specifically for the respective applications. In all the experiments, CityFM achieves performance superior to, or on par with, the baselines.
On the Opportunities and Challenges of Foundation Models for Geospatial Artificial Intelligence
Apr 13, 2023



Large pre-trained models, also known as foundation models (FMs), are trained in a task-agnostic manner on large-scale data and can be adapted to a wide range of downstream tasks by fine-tuning, few-shot, or even zero-shot learning. Despite their successes in language and vision tasks, we have yet seen an attempt to develop foundation models for geospatial artificial intelligence (GeoAI). In this work, we explore the promises and challenges of developing multimodal foundation models for GeoAI. We first investigate the potential of many existing FMs by testing their performances on seven tasks across multiple geospatial subdomains including Geospatial Semantics, Health Geography, Urban Geography, and Remote Sensing. Our results indicate that on several geospatial tasks that only involve text modality such as toponym recognition, location description recognition, and US state-level/county-level dementia time series forecasting, these task-agnostic LLMs can outperform task-specific fully-supervised models in a zero-shot or few-shot learning setting. However, on other geospatial tasks, especially tasks that involve multiple data modalities (e.g., POI-based urban function classification, street view image-based urban noise intensity classification, and remote sensing image scene classification), existing foundation models still underperform task-specific models. Based on these observations, we propose that one of the major challenges of developing a FM for GeoAI is to address the multimodality nature of geospatial tasks. After discussing the distinct challenges of each geospatial data modality, we suggest the possibility of a multimodal foundation model which can reason over various types of geospatial data through geospatial alignments. We conclude this paper by discussing the unique risks and challenges to develop such a model for GeoAI.
Narrative Cartography with Knowledge Graphs
Dec 02, 2021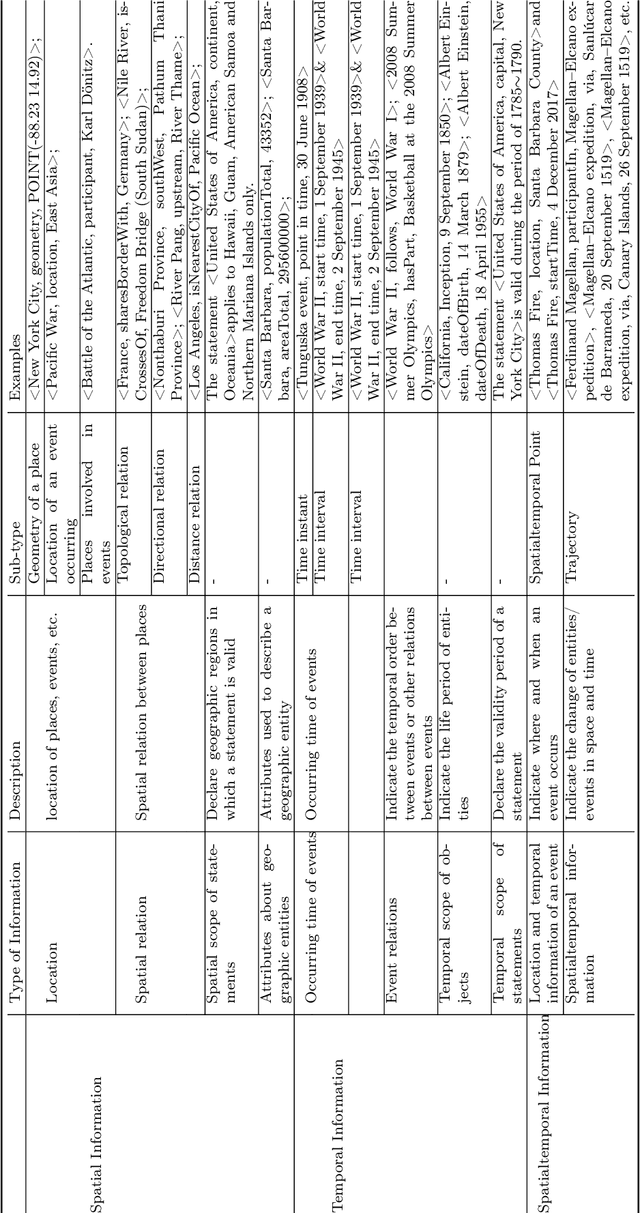
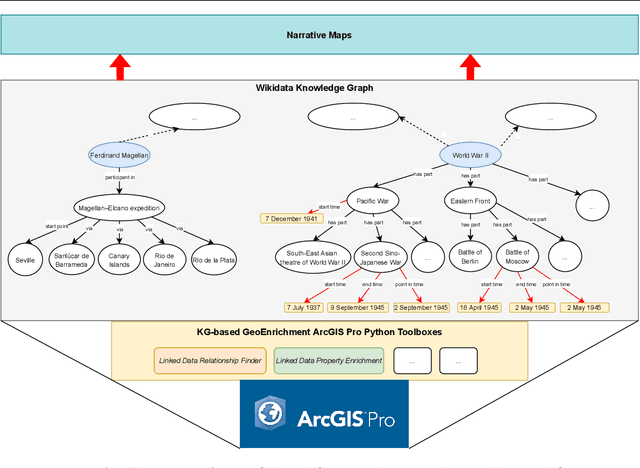
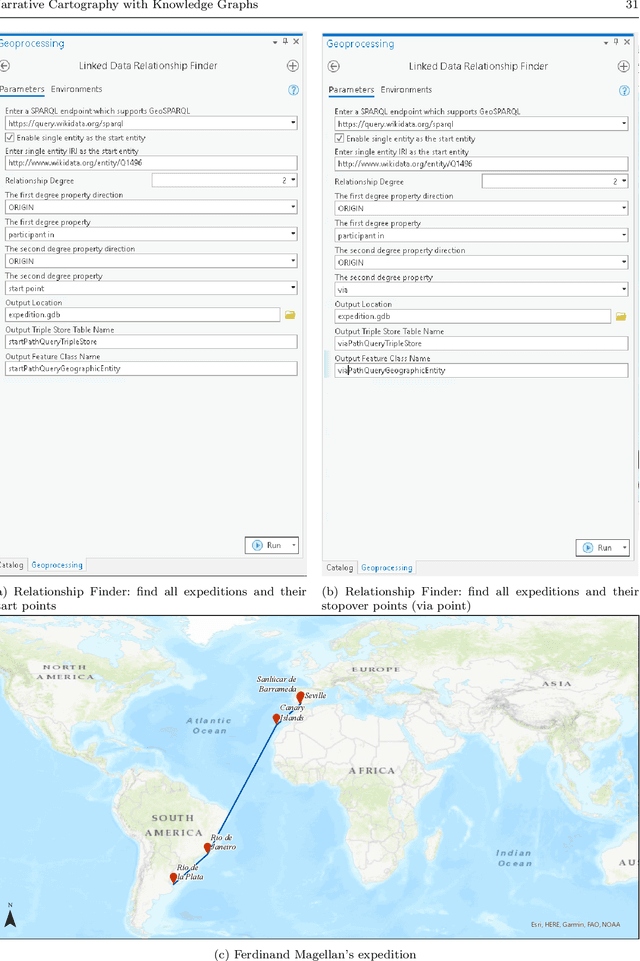
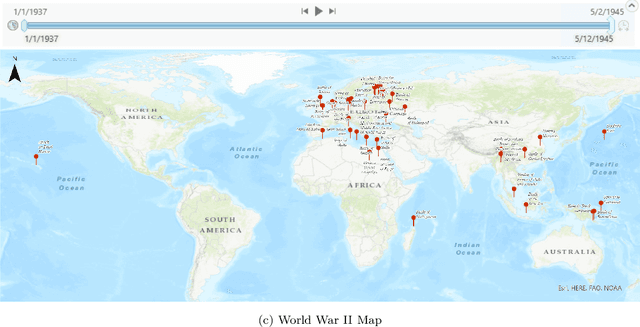
Narrative cartography is a discipline which studies the interwoven nature of stories and maps. However, conventional geovisualization techniques of narratives often encounter several prominent challenges, including the data acquisition & integration challenge and the semantic challenge. To tackle these challenges, in this paper, we propose the idea of narrative cartography with knowledge graphs (KGs). Firstly, to tackle the data acquisition & integration challenge, we develop a set of KG-based GeoEnrichment toolboxes to allow users to search and retrieve relevant data from integrated cross-domain knowledge graphs for narrative mapping from within a GISystem. With the help of this tool, the retrieved data from KGs are directly materialized in a GIS format which is ready for spatial analysis and mapping. Two use cases - Magellan's expedition and World War II - are presented to show the effectiveness of this approach. In the meantime, several limitations are identified from this approach, such as data incompleteness, semantic incompatibility, and the semantic challenge in geovisualization. For the later two limitations, we propose a modular ontology for narrative cartography, which formalizes both the map content (Map Content Module) and the geovisualization process (Cartography Module). We demonstrate that, by representing both the map content and the geovisualization process in KGs (an ontology), we can realize both data reusability and map reproducibility for narrative cartography.