 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRoad Network Representation Learning with the Third Law of Geography
Jun 06, 2024Road network representation learning aims to learn compressed and effective vectorized representations for road segments that are applicable to numerous tasks. In this paper, we identify the limitations of existing methods, particularly their overemphasis on the distance effect as outlined in the First Law of Geography. In response, we propose to endow road network representation with the principles of the recent Third Law of Geography. To this end, we propose a novel graph contrastive learning framework that employs geographic configuration-aware graph augmentation and spectral negative sampling, ensuring that road segments with similar geographic configurations yield similar representations, and vice versa, aligning with the principles stated in the Third Law. The framework further fuses the Third Law with the First Law through a dual contrastive learning objective to effectively balance the implications of both laws. We evaluate our framework on two real-world datasets across three downstream tasks. The results show that the integration of the Third Law significantly improves the performance of road segment representations in downstream tasks.
Not All Neighbors Are Worth Attending to: Graph Selective Attention Networks for Semi-supervised Learning
Oct 14, 2022Graph attention networks (GATs) are powerful tools for analyzing graph data from various real-world scenarios. To learn representations for downstream tasks, GATs generally attend to all neighbors of the central node when aggregating the features. In this paper, we show that a large portion of the neighbors are irrelevant to the central nodes in many real-world graphs, and can be excluded from neighbor aggregation. Taking the cue, we present Selective Attention (SA) and a series of novel attention mechanisms for graph neural networks (GNNs). SA leverages diverse forms of learnable node-node dissimilarity to acquire the scope of attention for each node, from which irrelevant neighbors are excluded. We further propose Graph selective attention networks (SATs) to learn representations from the highly correlated node features identified and investigated by different SA mechanisms. Lastly, theoretical analysis on the expressive power of the proposed SATs and a comprehensive empirical study of the SATs on challenging real-world datasets against state-of-the-art GNNs are presented to demonstrate the effectiveness of SATs.
SCE: Scalable Network Embedding from Sparsest Cut
Jul 17, 2020
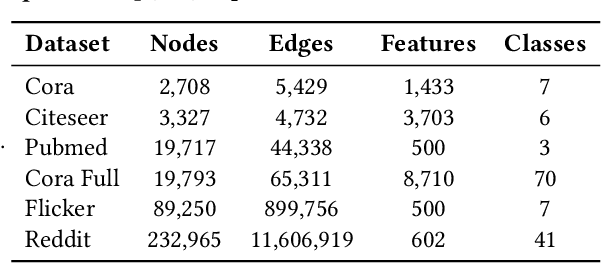
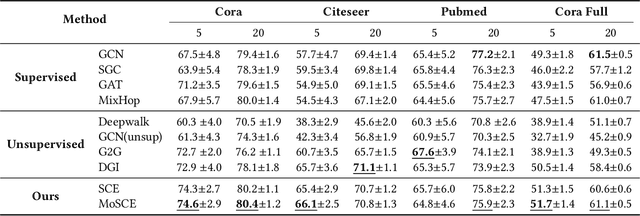
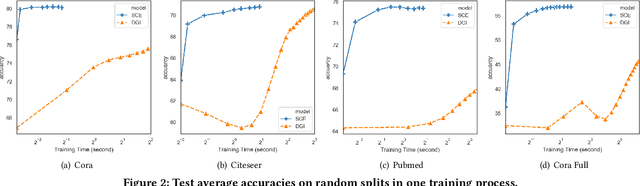
Large-scale network embedding is to learn a latent representation for each node in an unsupervised manner, which captures inherent properties and structural information of the underlying graph. In this field, many popular approaches are influenced by the skip-gram model from natural language processing. Most of them use a contrastive objective to train an encoder which forces the embeddings of similar pairs to be close and embeddings of negative samples to be far. A key of success to such contrastive learning methods is how to draw positive and negative samples. While negative samples that are generated by straightforward random sampling are often satisfying, methods for drawing positive examples remains a hot topic. In this paper, we propose SCE for unsupervised network embedding only using negative samples for training. Our method is based on a new contrastive objective inspired by the well-known sparsest cut problem. To solve the underlying optimization problem, we introduce a Laplacian smoothing trick, which uses graph convolutional operators as low-pass filters for smoothing node representations. The resulting model consists of a GCN-type structure as the encoder and a simple loss function. Notably, our model does not use positive samples but only negative samples for training, which not only makes the implementation and tuning much easier, but also reduces the training time significantly. Finally, extensive experimental studies on real world data sets are conducted. The results clearly demonstrate the advantages of our new model in both accuracy and scalability compared to strong baselines such as GraphSAGE, G2G and DGI.