 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCalibrating LLM Confidence with Semantic Steering: A Multi-Prompt Aggregation Framework
Mar 04, 2025Large Language Models (LLMs) often exhibit misaligned confidence scores, usually overestimating the reliability of their predictions. While verbalized confidence in Large Language Models (LLMs) has gained attention, prior work remains divided on whether confidence scores can be systematically steered through prompting. Recent studies even argue that such prompt-induced confidence shifts are negligible, suggesting LLMs' confidence calibration is rigid to linguistic interventions. Contrary to these claims, we first rigorously confirm the existence of directional confidence shifts by probing three models (including GPT3.5, LLAMA3-70b, GPT4) across 7 benchmarks, demonstrating that explicit instructions can inflate or deflate confidence scores in a regulated manner. Based on this observation, we propose a novel framework containing three components: confidence steering, steered confidence aggregation and steered answers selection, named SteeringConf. Our method, SteeringConf, leverages a confidence manipulation mechanism to steer the confidence scores of LLMs in several desired directions, followed by a summarization module that aggregates the steered confidence scores to produce a final prediction. We evaluate our method on 7 benchmarks and it consistently outperforms the baselines in terms of calibration metrics in task of confidence calibration and failure detection.
GNNs-to-MLPs by Teacher Injection and Dirichlet Energy Distillation
Dec 15, 2024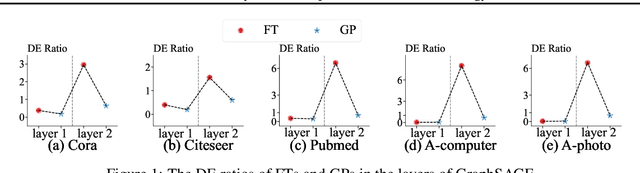

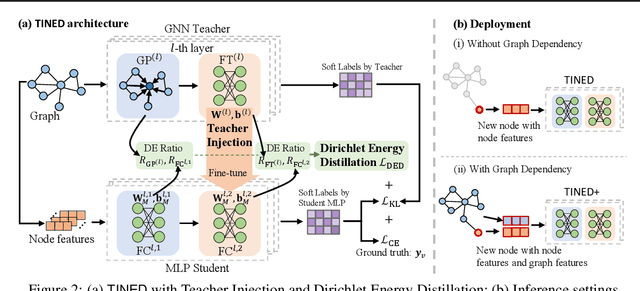
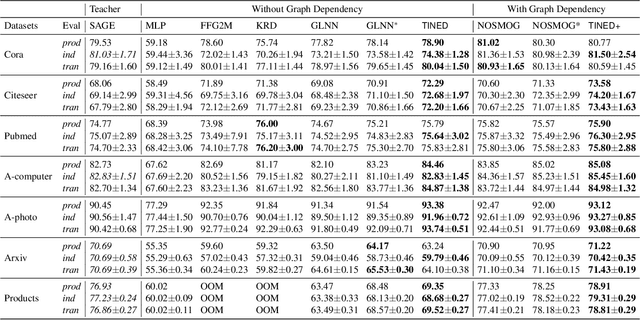
Graph Neural Networks (GNNs) are fundamental to graph-based learning and excel in node classification tasks. However, GNNs suffer from scalability issues due to the need for multi-hop data during inference, limiting their use in latency-sensitive applications. Recent studies attempt to distill GNNs into multi-layer perceptrons (MLPs) for faster inference. They typically treat GNN and MLP models as single units for distillation, insufficiently utilizing the fine-grained knowledge within GNN layers. In this paper, we propose TINED, a novel method that distills GNNs to MLPs layer-wise through Teacher Injection with fine-tuning and Dirichlet Energy Distillation techniques. We analyze key operations in GNN layers, feature transformation (FT) and graph propagation (GP), and identify that an FT performs the same computation as a fully-connected (FC) layer in MLPs. Thus, we propose directly injecting valuable teacher parameters of an FT in a GNN into an FC layer of the student MLP, assisted by fine-tuning. In TINED, FC layers in an MLP mirror the order of the corresponding FTs and GPs in GNN. We provide a theoretical bound on the approximation of GPs. Moreover, we observe that in a GNN layer, FT and GP operations often have opposing smoothing effects: GP is aggressive, while FT is conservative, in smoothing. Using Dirichlet energy, we design a DE ratio to quantify these smoothing effects and propose Dirichlet Energy Distillation to distill these characteristics from GNN layers to MLP layers. Extensive experiments demonstrate that TINED achieves superior performance over GNNs and state-of-the-art distillation methods under various settings across seven datasets. The code is in supplementary material.
SlotGAT: Slot-based Message Passing for Heterogeneous Graph Neural Network
May 03, 2024Heterogeneous graphs are ubiquitous to model complex data. There are urgent needs on powerful heterogeneous graph neural networks to effectively support important applications. We identify a potential semantic mixing issue in existing message passing processes, where the representations of the neighbors of a node $v$ are forced to be transformed to the feature space of $v$ for aggregation, though the neighbors are in different types. That is, the semantics in different node types are entangled together into node $v$'s representation. To address the issue, we propose SlotGAT with separate message passing processes in slots, one for each node type, to maintain the representations in their own node-type feature spaces. Moreover, in a slot-based message passing layer, we design an attention mechanism for effective slot-wise message aggregation. Further, we develop a slot attention technique after the last layer of SlotGAT, to learn the importance of different slots in downstream tasks. Our analysis indicates that the slots in SlotGAT can preserve different semantics in various feature spaces. The superiority of SlotGAT is evaluated against 13 baselines on 6 datasets for node classification and link prediction. Our code is at https://github.com/scottjiao/SlotGAT_ICML23/.
Detecting Escalation Level from Speech with Transfer Learning and Acoustic-Lexical Information Fusion
Apr 13, 2021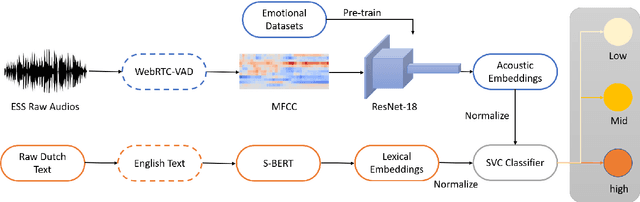
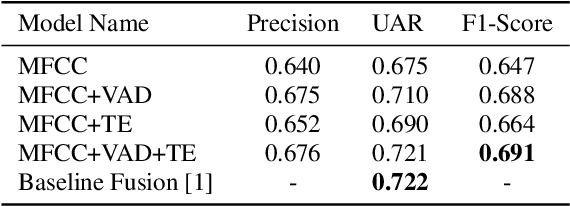
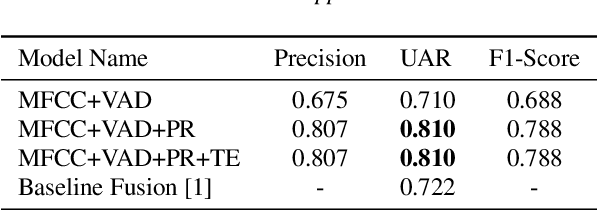
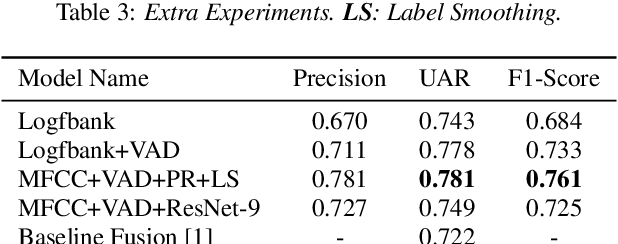
Textual escalation detection has been widely applied to e-commerce companies' customer service systems to pre-alert and prevent potential conflicts. Similarly, in public areas such as airports and train stations, where many impersonal conversations frequently take place, acoustic-based escalation detection systems are also useful to enhance passengers' safety and maintain public order. To this end, we introduce a system based on acoustic-lexical features to detect escalation from speech, Voice Activity Detection (VAD) and label smoothing are adopted to further enhance the performance in our experiments. Considering a small set of training and development data, we also employ transfer learning on several well-known emotional detection datasets, i.e. RAVDESS, CREMA-D, to learn advanced emotional representations that can be applied to the escalation detection task. On the development set, our proposed system achieves 81.5% unweighted average recall (UAR) which significantly outperforms the baseline with 72.2% UAR.
SCE: Scalable Network Embedding from Sparsest Cut
Jul 17, 2020
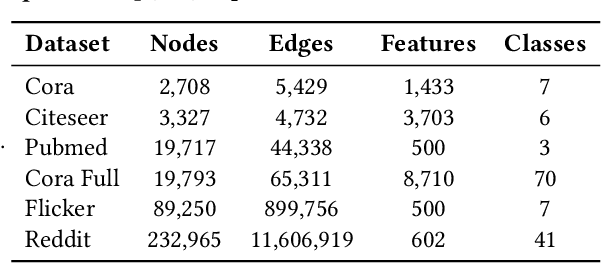
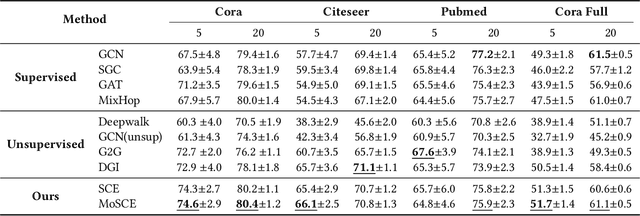
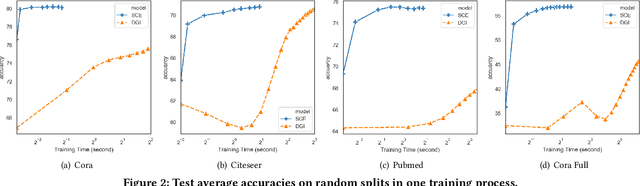
Large-scale network embedding is to learn a latent representation for each node in an unsupervised manner, which captures inherent properties and structural information of the underlying graph. In this field, many popular approaches are influenced by the skip-gram model from natural language processing. Most of them use a contrastive objective to train an encoder which forces the embeddings of similar pairs to be close and embeddings of negative samples to be far. A key of success to such contrastive learning methods is how to draw positive and negative samples. While negative samples that are generated by straightforward random sampling are often satisfying, methods for drawing positive examples remains a hot topic. In this paper, we propose SCE for unsupervised network embedding only using negative samples for training. Our method is based on a new contrastive objective inspired by the well-known sparsest cut problem. To solve the underlying optimization problem, we introduce a Laplacian smoothing trick, which uses graph convolutional operators as low-pass filters for smoothing node representations. The resulting model consists of a GCN-type structure as the encoder and a simple loss function. Notably, our model does not use positive samples but only negative samples for training, which not only makes the implementation and tuning much easier, but also reduces the training time significantly. Finally, extensive experimental studies on real world data sets are conducted. The results clearly demonstrate the advantages of our new model in both accuracy and scalability compared to strong baselines such as GraphSAGE, G2G and DGI.
Multi-consensus Decentralized Accelerated Gradient Descent
May 02, 2020
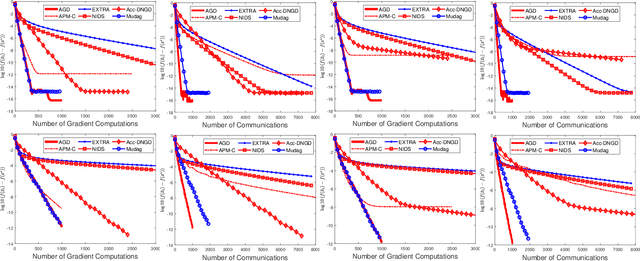
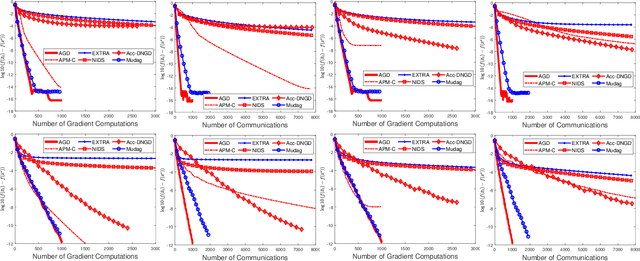
This paper considers the decentralized optimization problem, which has applications in large scale machine learning, sensor networks, and control theory. We propose a novel algorithm that can achieve near optimal communication complexity, matching the known lower bound up to a logarithmic factor of the condition number of the problem. Our theoretical results give affirmative answers to the open problem on whether there exists an algorithm that can achieve a communication complexity (nearly) matching the lower bound depending on the global condition number instead of the local one. Moreover, the proposed algorithm achieves the optimal computation complexity matching the lower bound up to universal constants. Furthermore, to achieve a linear convergence rate, our algorithm \emph{doesn't} require the individual functions to be (strongly) convex. Our method relies on a novel combination of known techniques including Nesterov's accelerated gradient descent, multi-consensus and gradient-tracking. The analysis is new, and may be applied to other related problems. Empirical studies demonstrate the effectiveness of our method for machine learning applications.
Dynamic Self-training Framework for Graph Convolutional Networks
Oct 07, 2019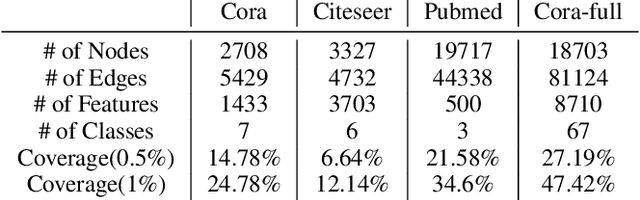
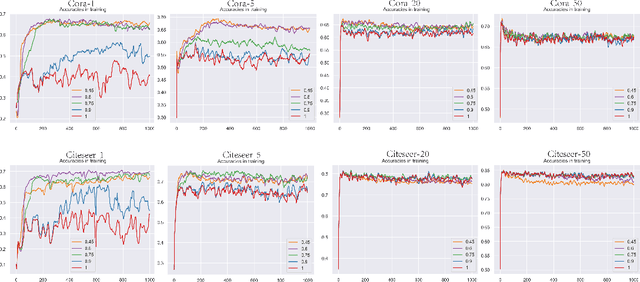
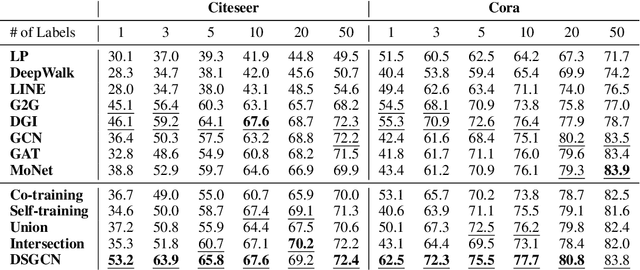
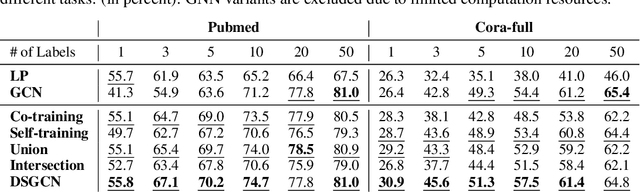
Graph neural networks (GNN) such as GCN, GAT, MoNet have achieved state-of-the-art results on semi-supervised learning on graphs. However, when the number of labeled nodes is very small, the performances of GNNs downgrade dramatically. Self-training has proved to be effective for resolving this issue, however, the performance of self-trained GCN is still inferior to that of G2G and DGI for many settings. Moreover, additional model complexity make it more difficult to tune the hyper-parameters and do model selection. We argue that the power of self-training is still not fully explored for the node classification task. In this paper, we propose a unified end-to-end self-training framework called \emph{Dynamic Self-traning}, which generalizes and simplifies prior work. A simple instantiation of the framework based on GCN is provided and empirical results show that our framework outperforms all previous methods including GNNs, embedding based method and self-trained GCNs by a noticeable margin. Moreover, compared with standard self-training, hyper-parameter tuning for our framework is easier.