 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFlexGuard: Continuous Risk Scoring for Strictness-Adaptive LLM Content Moderation
Mar 03, 2026Ensuring the safety of LLM-generated content is essential for real-world deployment. Most existing guardrail models formulate moderation as a fixed binary classification task, implicitly assuming a fixed definition of harmfulness. In practice, enforcement strictness - how conservatively harmfulness is defined and enforced - varies across platforms and evolves over time, making binary moderators brittle under shifting requirements. We first introduce FlexBench, a strictness-adaptive LLM moderation benchmark that enables controlled evaluation under multiple strictness regimes. Experiments on FlexBench reveal substantial cross-strictness inconsistency in existing moderators: models that perform well under one regime can degrade substantially under others, limiting their practical usability. To address this, we propose FlexGuard, an LLM-based moderator that outputs a calibrated continuous risk score reflecting risk severity and supports strictness-specific decisions via thresholding. We train FlexGuard via risk-alignment optimization to improve score-severity consistency and provide practical threshold selection strategies to adapt to target strictness at deployment. Experiments on FlexBench and public benchmarks demonstrate that FlexGuard achieves higher moderation accuracy and substantially improved robustness under varying strictness. We release the source code and data to support reproducibility.
\underline{E2}Former: A Linear-time \underline{E}fficient and \underline{E}quivariant Trans\underline{former} for Scalable Molecular Modeling
Jan 31, 2025



Equivariant Graph Neural Networks (EGNNs) have demonstrated significant success in modeling microscale systems, including those in chemistry, biology and materials science. However, EGNNs face substantial computational challenges due to the high cost of constructing edge features via spherical tensor products, making them impractical for large-scale systems. To address this limitation, we introduce E2Former, an equivariant and efficient transformer architecture that incorporates the Wigner $6j$ convolution (Wigner $6j$ Conv). By shifting the computational burden from edges to nodes, the Wigner $6j$ Conv reduces the complexity from $O(|\mathcal{E}|)$ to $ O(| \mathcal{V}|)$ while preserving both the model's expressive power and rotational equivariance. We show that this approach achieves a 7x-30x speedup compared to conventional $\mathrm{SO}(3)$ convolutions. Furthermore, our empirical results demonstrate that the derived E2Former mitigates the computational challenges of existing approaches without compromising the ability to capture detailed geometric information. This development could suggest a promising direction for scalable and efficient molecular modeling.
GNNs-to-MLPs by Teacher Injection and Dirichlet Energy Distillation
Dec 15, 2024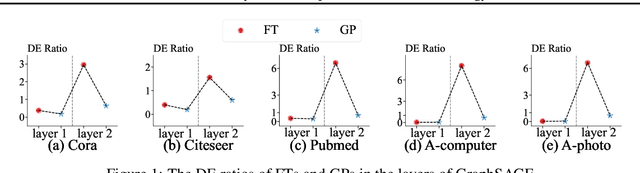

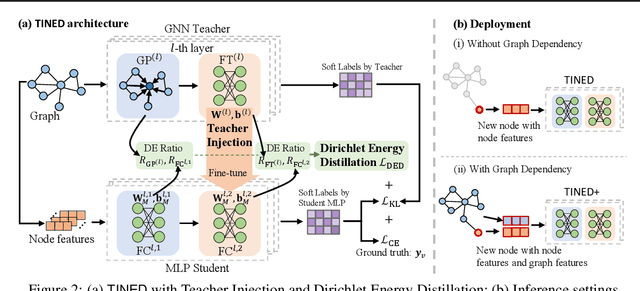
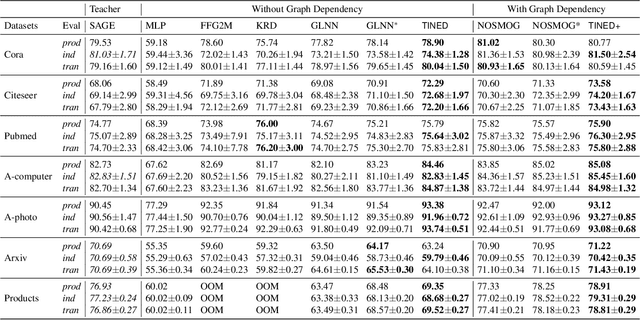
Graph Neural Networks (GNNs) are fundamental to graph-based learning and excel in node classification tasks. However, GNNs suffer from scalability issues due to the need for multi-hop data during inference, limiting their use in latency-sensitive applications. Recent studies attempt to distill GNNs into multi-layer perceptrons (MLPs) for faster inference. They typically treat GNN and MLP models as single units for distillation, insufficiently utilizing the fine-grained knowledge within GNN layers. In this paper, we propose TINED, a novel method that distills GNNs to MLPs layer-wise through Teacher Injection with fine-tuning and Dirichlet Energy Distillation techniques. We analyze key operations in GNN layers, feature transformation (FT) and graph propagation (GP), and identify that an FT performs the same computation as a fully-connected (FC) layer in MLPs. Thus, we propose directly injecting valuable teacher parameters of an FT in a GNN into an FC layer of the student MLP, assisted by fine-tuning. In TINED, FC layers in an MLP mirror the order of the corresponding FTs and GPs in GNN. We provide a theoretical bound on the approximation of GPs. Moreover, we observe that in a GNN layer, FT and GP operations often have opposing smoothing effects: GP is aggressive, while FT is conservative, in smoothing. Using Dirichlet energy, we design a DE ratio to quantify these smoothing effects and propose Dirichlet Energy Distillation to distill these characteristics from GNN layers to MLP layers. Extensive experiments demonstrate that TINED achieves superior performance over GNNs and state-of-the-art distillation methods under various settings across seven datasets. The code is in supplementary material.
RingFormer: A Ring-Enhanced Graph Transformer for Organic Solar Cell Property Prediction
Dec 12, 2024



Organic Solar Cells (OSCs) are a promising technology for sustainable energy production. However, the identification of molecules with desired OSC properties typically involves laborious experimental research. To accelerate progress in the field, it is crucial to develop machine learning models capable of accurately predicting the properties of OSC molecules. While graph representation learning has demonstrated success in molecular property prediction, it remains underexplored for OSC-specific tasks. Existing methods fail to capture the unique structural features of OSC molecules, particularly the intricate ring systems that critically influence OSC properties, leading to suboptimal performance. To fill the gap, we present RingFormer, a novel graph transformer framework specially designed to capture both atom and ring level structural patterns in OSC molecules. RingFormer constructs a hierarchical graph that integrates atomic and ring structures and employs a combination of local message passing and global attention mechanisms to generate expressive graph representations for accurate OSC property prediction. We evaluate RingFormer's effectiveness on five curated OSC molecule datasets through extensive experiments. The results demonstrate that RingFormer consistently outperforms existing methods, achieving a 22.77% relative improvement over the nearest competitor on the CEPDB dataset.
Large Language Models are In-Context Molecule Learners
Mar 07, 2024Large Language Models (LLMs) have demonstrated exceptional performance in biochemical tasks, especially the molecule caption translation task, which aims to bridge the gap between molecules and natural language texts. However, previous methods in adapting LLMs to the molecule-caption translation task required extra domain-specific pre-training stages, suffered weak alignment between molecular and textual spaces, or imposed stringent demands on the scale of LLMs. To resolve the challenges, we propose In-Context Molecule Adaptation (ICMA), as a new paradigm allowing LLMs to learn the molecule-text alignment from context examples via In-Context Molecule Tuning. Specifically, ICMA incorporates the following three stages: Cross-modal Retrieval, Post-retrieval Re-ranking, and In-context Molecule Tuning. Initially, Cross-modal Retrieval utilizes BM25 Caption Retrieval and Molecule Graph Retrieval to retrieve informative context examples. Additionally, we also propose Post-retrieval Re-ranking with Sequence Reversal and Random Walk to further improve the quality of retrieval results. Finally, In-Context Molecule Tuning unlocks the in-context molecule learning capability of LLMs with retrieved examples and adapts the parameters of LLMs for the molecule-caption translation task. Experimental results demonstrate that ICMT can empower LLMs to achieve state-of-the-art or comparable performance without extra training corpora and intricate structures, showing that LLMs are inherently in-context molecule learners.
SGOOD: Substructure-enhanced Graph-Level Out-of-Distribution Detection
Oct 16, 2023Graph-level representation learning is important in a wide range of applications. However, existing graph-level models are generally built on i.i.d. assumption for both training and testing graphs, which is not realistic in an open world, where models can encounter out-of-distribution (OOD) testing graphs that are from different distributions unknown during training. A trustworthy model should not only produce accurate predictions for in-distribution (ID) data, but also detect OOD graphs to avoid unreliable prediction. In this paper, we present SGOOD, a novel graph-level OOD detection framework. We find that substructure differences commonly exist between ID and OOD graphs. Hence, SGOOD explicitly utilizes substructures to learn powerful representations to achieve superior performance. Specifically, we build a super graph of substructures for every graph, and design a two-level graph encoding pipeline that works on both original graphs and super graphs to obtain substructure-enhanced graph representations. To further distinguish ID and OOD graphs, we develop three graph augmentation techniques that preserve substructures and increase expressiveness. Extensive experiments against 10 competitors on numerous graph datasets demonstrate the superiority of SGOOD, often surpassing existing methods by a significant margin. The code is available at https://anonymous.4open.science/r/SGOOD-0958.
Effective Multi-Graph Neural Networks for Illicit Account Detection on Cryptocurrency Transaction Networks
Sep 04, 2023



We study illicit account detection on transaction networks of cryptocurrencies that are increasi_testngly important in online financial markets. The surge of illicit activities on cryptocurrencies has resulted in billions of losses from normal users. Existing solutions either rely on tedious feature engineering to get handcrafted features, or are inadequate to fully utilize the rich semantics of cryptocurrency transaction data, and consequently, yield sub-optimal performance. In this paper, we formulate the illicit account detection problem as a classification task over directed multigraphs with edge attributes, and present DIAM, a novel multi-graph neural network model to effectively detect illicit accounts on large transaction networks. First, DIAM includes an Edge2Seq module that automatically learns effective node representations preserving intrinsic transaction patterns of parallel edges, by considering both edge attributes and directed edge sequence dependencies. Then utilizing the multigraph topology, DIAM employs a new Multigraph Discrepancy (MGD) module with a well-designed message passing mechanism to capture the discrepant features between normal and illicit nodes, supported by an attention mechanism. Assembling all techniques, DIAM is trained in an end-to-end manner. Extensive experiments, comparing against 14 existing solutions on 4 large cryptocurrency datasets of Bitcoin and Ethereum, demonstrate that DIAM consistently achieves the best performance to accurately detect illicit accounts, while being efficient. For instance, on a Bitcoin dataset with 20 million nodes and 203 million edges, DIAM achieves F1 score 96.55%, significantly higher than the F1 score 83.92% of the best competitor.
Infer-AVAE: An Attribute Inference Model Based on Adversarial Variational Autoencoder
Dec 30, 2020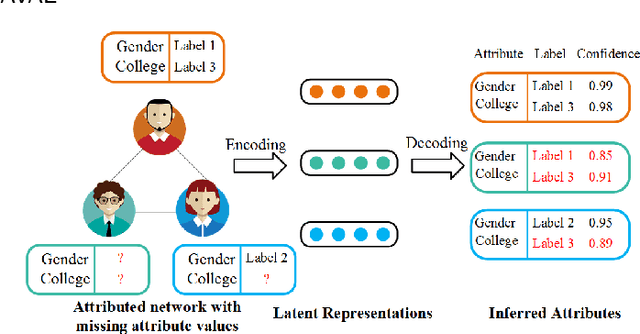
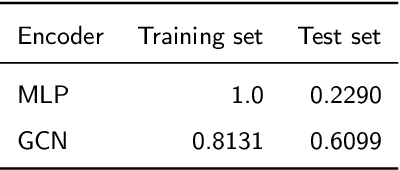
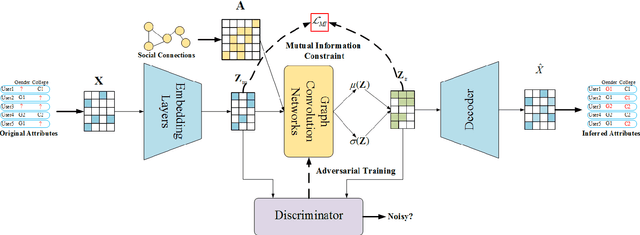
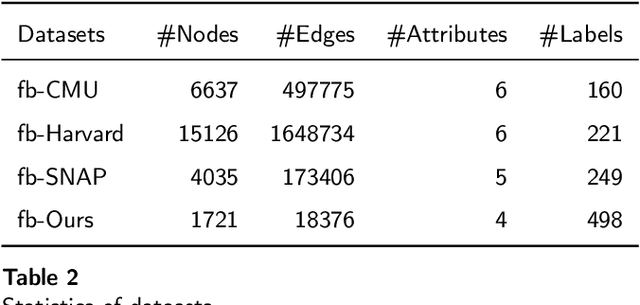
Facing the sparsity of user attributes on social networks, attribute inference aims at inferring missing attributes based on existing data and additional information such as social connections between users. Recently, Variational Autoencoders (VAEs) have been successfully applied to solve the problem in a semi-supervised way. However, the latent representations learned by the encoder contain either insufficient or useless information: i) MLPs can successfully reconstruct the input data but fail in completing missing part, ii) GNNs merge information according to social connections but suffer from over-smoothing, which is a common problem with GNNs. Moreover, existing methods neglect regulating the decoder, as a result, it lacks adequate inference ability and faces severe overfitting. To address the above issues, we propose an attribute inference model based on adversarial VAE (Infer-AVAE). Our model deliberately unifies MLPs and GNNs in encoder to learn dual latent representations: one contains only the observed attributes of each user, the other converges extra information from the neighborhood. Then, an adversarial network is trained to leverage the differences between the two representations and adversarial training is conducted to guide GNNs using MLPs for robust representations. What's more, mutual information constraint is introduced in loss function to specifically train the decoder as a discriminator. Thus, it can make better use of auxiliary information in the representations for attribute inference. Based on real-world social network datasets, experimental results demonstrate that our model averagely outperforms state-of-art by 7.0% in accuracy.