 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInfer-AVAE: An Attribute Inference Model Based on Adversarial Variational Autoencoder
Dec 30, 2020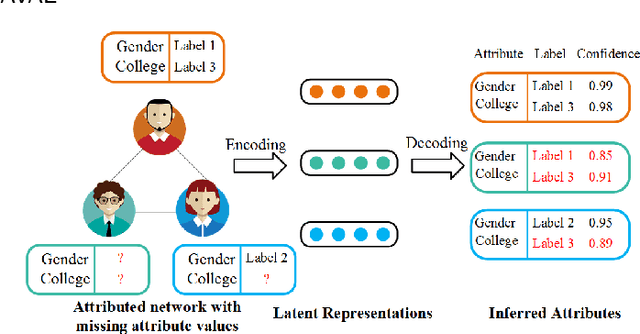
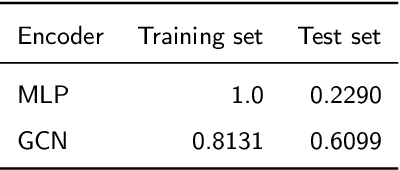
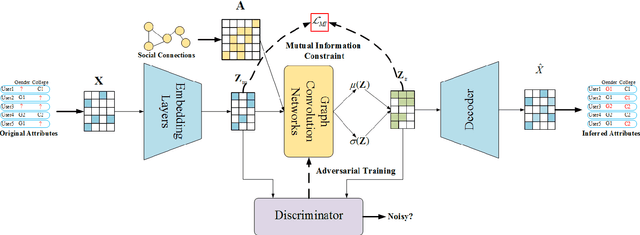
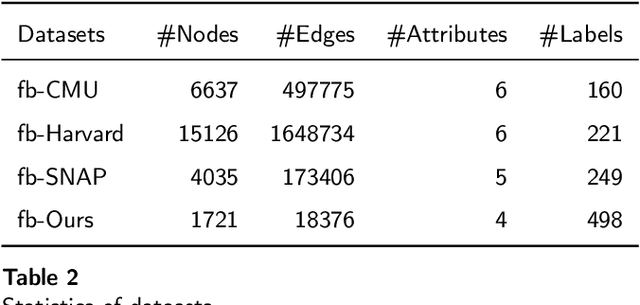
Facing the sparsity of user attributes on social networks, attribute inference aims at inferring missing attributes based on existing data and additional information such as social connections between users. Recently, Variational Autoencoders (VAEs) have been successfully applied to solve the problem in a semi-supervised way. However, the latent representations learned by the encoder contain either insufficient or useless information: i) MLPs can successfully reconstruct the input data but fail in completing missing part, ii) GNNs merge information according to social connections but suffer from over-smoothing, which is a common problem with GNNs. Moreover, existing methods neglect regulating the decoder, as a result, it lacks adequate inference ability and faces severe overfitting. To address the above issues, we propose an attribute inference model based on adversarial VAE (Infer-AVAE). Our model deliberately unifies MLPs and GNNs in encoder to learn dual latent representations: one contains only the observed attributes of each user, the other converges extra information from the neighborhood. Then, an adversarial network is trained to leverage the differences between the two representations and adversarial training is conducted to guide GNNs using MLPs for robust representations. What's more, mutual information constraint is introduced in loss function to specifically train the decoder as a discriminator. Thus, it can make better use of auxiliary information in the representations for attribute inference. Based on real-world social network datasets, experimental results demonstrate that our model averagely outperforms state-of-art by 7.0% in accuracy.
Learning Graph Embedding with Limited Labeled Data: An Efficient Sampling Approach
Mar 13, 2020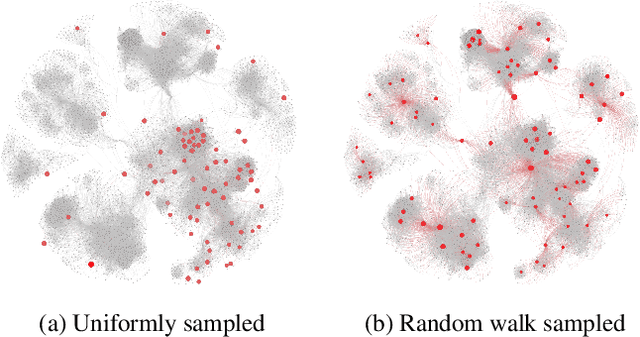
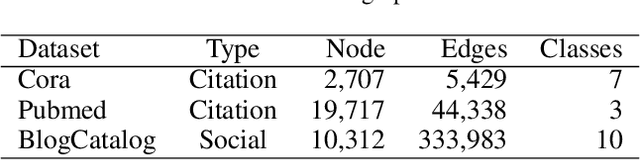
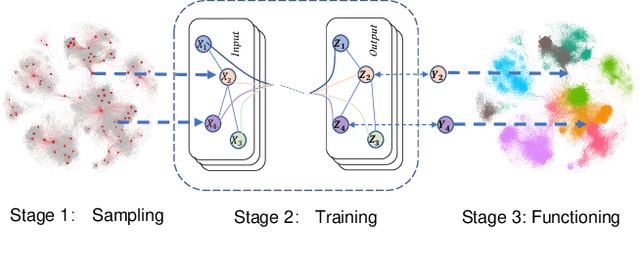
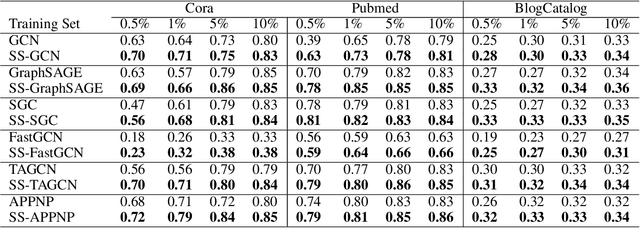
Semi-supervised graph embedding methods represented by graph convolutional network has become one of the most popular methods for utilizing deep learning approaches to process the graph-based data for applications. Mostly existing work focus on designing novel algorithm structure to improve the performance, but ignore one common training problem, i.e., could these methods achieve the same performance with limited labelled data? To tackle this research gap, we propose a sampling-based training framework for semi-supervised graph embedding methods to achieve better performance with smaller training data set. The key idea is to integrate the sampling theory and embedding methods by a pipeline form, which has the following advantages: 1) the sampled training data can maintain more accurate graph characteristics than uniformly chosen data, which eliminates the model deviation; 2) the smaller scale of training data is beneficial to reduce the human resource cost to label them; The extensive experiments show that the sampling-based method can achieve the same performance only with 10$\%$-50$\%$ of the scale of training data. It verifies that the framework could extend the existing semi-supervised methods to the scenarios with the extremely small scale of labelled data.