 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Graph Embedding with Limited Labeled Data: An Efficient Sampling Approach
Paper and Code
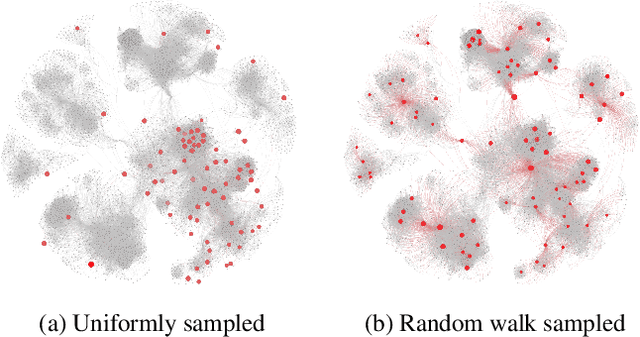
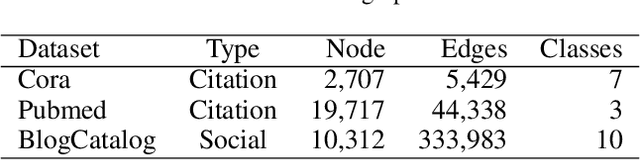
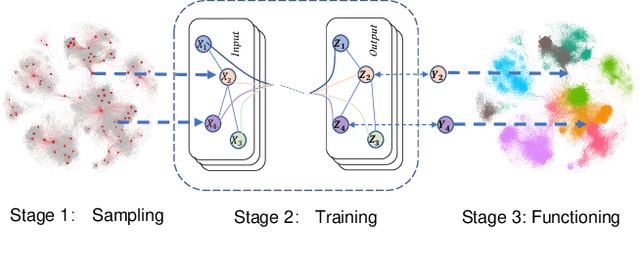
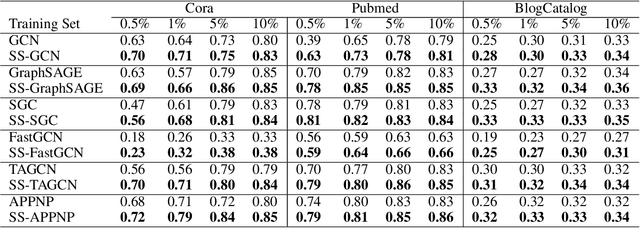
Semi-supervised graph embedding methods represented by graph convolutional network has become one of the most popular methods for utilizing deep learning approaches to process the graph-based data for applications. Mostly existing work focus on designing novel algorithm structure to improve the performance, but ignore one common training problem, i.e., could these methods achieve the same performance with limited labelled data? To tackle this research gap, we propose a sampling-based training framework for semi-supervised graph embedding methods to achieve better performance with smaller training data set. The key idea is to integrate the sampling theory and embedding methods by a pipeline form, which has the following advantages: 1) the sampled training data can maintain more accurate graph characteristics than uniformly chosen data, which eliminates the model deviation; 2) the smaller scale of training data is beneficial to reduce the human resource cost to label them; The extensive experiments show that the sampling-based method can achieve the same performance only with 10$\%$-50$\%$ of the scale of training data. It verifies that the framework could extend the existing semi-supervised methods to the scenarios with the extremely small scale of labelled data.