 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFlexGuard: Continuous Risk Scoring for Strictness-Adaptive LLM Content Moderation
Mar 03, 2026Ensuring the safety of LLM-generated content is essential for real-world deployment. Most existing guardrail models formulate moderation as a fixed binary classification task, implicitly assuming a fixed definition of harmfulness. In practice, enforcement strictness - how conservatively harmfulness is defined and enforced - varies across platforms and evolves over time, making binary moderators brittle under shifting requirements. We first introduce FlexBench, a strictness-adaptive LLM moderation benchmark that enables controlled evaluation under multiple strictness regimes. Experiments on FlexBench reveal substantial cross-strictness inconsistency in existing moderators: models that perform well under one regime can degrade substantially under others, limiting their practical usability. To address this, we propose FlexGuard, an LLM-based moderator that outputs a calibrated continuous risk score reflecting risk severity and supports strictness-specific decisions via thresholding. We train FlexGuard via risk-alignment optimization to improve score-severity consistency and provide practical threshold selection strategies to adapt to target strictness at deployment. Experiments on FlexBench and public benchmarks demonstrate that FlexGuard achieves higher moderation accuracy and substantially improved robustness under varying strictness. We release the source code and data to support reproducibility.
Calibrating LLM Confidence with Semantic Steering: A Multi-Prompt Aggregation Framework
Mar 04, 2025Large Language Models (LLMs) often exhibit misaligned confidence scores, usually overestimating the reliability of their predictions. While verbalized confidence in Large Language Models (LLMs) has gained attention, prior work remains divided on whether confidence scores can be systematically steered through prompting. Recent studies even argue that such prompt-induced confidence shifts are negligible, suggesting LLMs' confidence calibration is rigid to linguistic interventions. Contrary to these claims, we first rigorously confirm the existence of directional confidence shifts by probing three models (including GPT3.5, LLAMA3-70b, GPT4) across 7 benchmarks, demonstrating that explicit instructions can inflate or deflate confidence scores in a regulated manner. Based on this observation, we propose a novel framework containing three components: confidence steering, steered confidence aggregation and steered answers selection, named SteeringConf. Our method, SteeringConf, leverages a confidence manipulation mechanism to steer the confidence scores of LLMs in several desired directions, followed by a summarization module that aggregates the steered confidence scores to produce a final prediction. We evaluate our method on 7 benchmarks and it consistently outperforms the baselines in terms of calibration metrics in task of confidence calibration and failure detection.
Enhancing Model Defense Against Jailbreaks with Proactive Safety Reasoning
Jan 31, 2025



Large language models (LLMs) are vital for a wide range of applications yet remain susceptible to jailbreak threats, which could lead to the generation of inappropriate responses. Conventional defenses, such as refusal and adversarial training, often fail to cover corner cases or rare domains, leaving LLMs still vulnerable to more sophisticated attacks. We propose a novel defense strategy, Safety Chain-of-Thought (SCoT), which harnesses the enhanced \textit{reasoning capabilities} of LLMs for proactive assessment of harmful inputs, rather than simply blocking them. SCoT augments any refusal training datasets to critically analyze the intent behind each request before generating answers. By employing proactive reasoning, SCoT enhances the generalization of LLMs across varied harmful queries and scenarios not covered in the safety alignment corpus. Additionally, it generates detailed refusals specifying the rules violated. Comparative evaluations show that SCoT significantly surpasses existing defenses, reducing vulnerability to out-of-distribution issues and adversarial manipulations while maintaining strong general capabilities.
GNNs-to-MLPs by Teacher Injection and Dirichlet Energy Distillation
Dec 15, 2024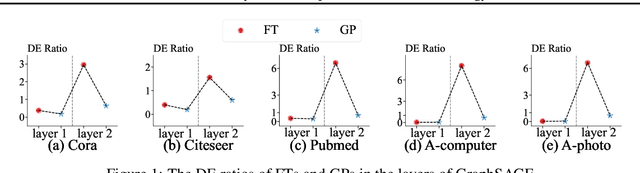

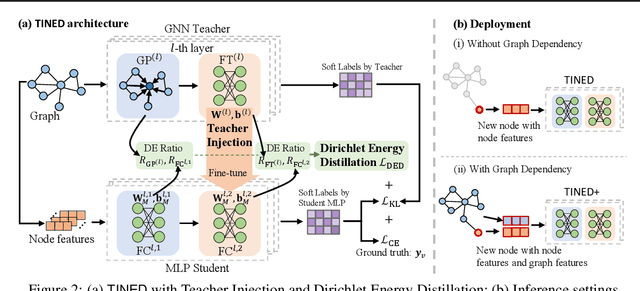
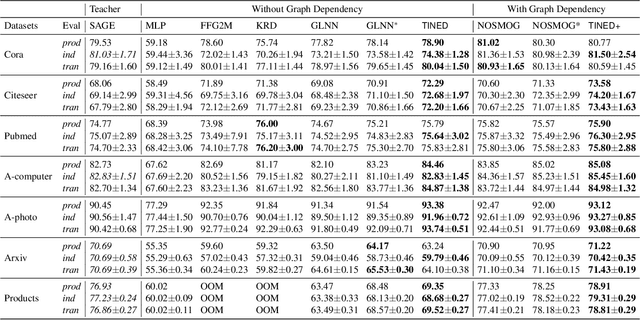
Graph Neural Networks (GNNs) are fundamental to graph-based learning and excel in node classification tasks. However, GNNs suffer from scalability issues due to the need for multi-hop data during inference, limiting their use in latency-sensitive applications. Recent studies attempt to distill GNNs into multi-layer perceptrons (MLPs) for faster inference. They typically treat GNN and MLP models as single units for distillation, insufficiently utilizing the fine-grained knowledge within GNN layers. In this paper, we propose TINED, a novel method that distills GNNs to MLPs layer-wise through Teacher Injection with fine-tuning and Dirichlet Energy Distillation techniques. We analyze key operations in GNN layers, feature transformation (FT) and graph propagation (GP), and identify that an FT performs the same computation as a fully-connected (FC) layer in MLPs. Thus, we propose directly injecting valuable teacher parameters of an FT in a GNN into an FC layer of the student MLP, assisted by fine-tuning. In TINED, FC layers in an MLP mirror the order of the corresponding FTs and GPs in GNN. We provide a theoretical bound on the approximation of GPs. Moreover, we observe that in a GNN layer, FT and GP operations often have opposing smoothing effects: GP is aggressive, while FT is conservative, in smoothing. Using Dirichlet energy, we design a DE ratio to quantify these smoothing effects and propose Dirichlet Energy Distillation to distill these characteristics from GNN layers to MLP layers. Extensive experiments demonstrate that TINED achieves superior performance over GNNs and state-of-the-art distillation methods under various settings across seven datasets. The code is in supplementary material.
GraSP: Simple yet Effective Graph Similarity Predictions
Dec 13, 2024Graph similarity computation (GSC) is to calculate the similarity between one pair of graphs, which is a fundamental problem with fruitful applications in the graph community. In GSC, graph edit distance (GED) and maximum common subgraph (MCS) are two important similarity metrics, both of which are NP-hard to compute. Instead of calculating the exact values, recent solutions resort to leveraging graph neural networks (GNNs) to learn data-driven models for the estimation of GED and MCS. Most of them are built on components involving node-level interactions crossing graphs, which engender vast computation overhead but are of little avail in effectiveness. In the paper, we present GraSP, a simple yet effective GSC approach for GED and MCS prediction. GraSP achieves high result efficacy through several key instruments: enhanced node features via positional encoding and a GNN model augmented by a gating mechanism, residual connections, as well as multi-scale pooling. Theoretically, GraSP can surpass the 1-WL test, indicating its high expressiveness. Empirically, extensive experiments comparing GraSP against 10 competitors on multiple widely adopted benchmark datasets showcase the superiority of GraSP over prior arts in terms of both effectiveness and efficiency. The code is available at https://github.com/HaoranZ99/GraSP.
RingFormer: A Ring-Enhanced Graph Transformer for Organic Solar Cell Property Prediction
Dec 12, 2024



Organic Solar Cells (OSCs) are a promising technology for sustainable energy production. However, the identification of molecules with desired OSC properties typically involves laborious experimental research. To accelerate progress in the field, it is crucial to develop machine learning models capable of accurately predicting the properties of OSC molecules. While graph representation learning has demonstrated success in molecular property prediction, it remains underexplored for OSC-specific tasks. Existing methods fail to capture the unique structural features of OSC molecules, particularly the intricate ring systems that critically influence OSC properties, leading to suboptimal performance. To fill the gap, we present RingFormer, a novel graph transformer framework specially designed to capture both atom and ring level structural patterns in OSC molecules. RingFormer constructs a hierarchical graph that integrates atomic and ring structures and employs a combination of local message passing and global attention mechanisms to generate expressive graph representations for accurate OSC property prediction. We evaluate RingFormer's effectiveness on five curated OSC molecule datasets through extensive experiments. The results demonstrate that RingFormer consistently outperforms existing methods, achieving a 22.77% relative improvement over the nearest competitor on the CEPDB dataset.
A Versatile Framework for Attributed Network Clustering via K-Nearest Neighbor Augmentation
Aug 10, 2024Attributed networks containing entity-specific information in node attributes are ubiquitous in modeling social networks, e-commerce, bioinformatics, etc. Their inherent network topology ranges from simple graphs to hypergraphs with high-order interactions and multiplex graphs with separate layers. An important graph mining task is node clustering, aiming to partition the nodes of an attributed network into k disjoint clusters such that intra-cluster nodes are closely connected and share similar attributes, while inter-cluster nodes are far apart and dissimilar. It is highly challenging to capture multi-hop connections via nodes or attributes for effective clustering on multiple types of attributed networks. In this paper, we first present AHCKA as an efficient approach to attributed hypergraph clustering (AHC). AHCKA includes a carefully-crafted K-nearest neighbor augmentation strategy for the optimized exploitation of attribute information on hypergraphs, a joint hypergraph random walk model to devise an effective AHC objective, and an efficient solver with speedup techniques for the objective optimization. The proposed techniques are extensible to various types of attributed networks, and thus, we develop ANCKA as a versatile attributed network clustering framework, capable of attributed graph clustering (AGC), attributed multiplex graph clustering (AMGC), and AHC. Moreover, we devise ANCKA with algorithmic designs tailored for GPU acceleration to boost efficiency. We have conducted extensive experiments to compare our methods with 19 competitors on 8 attributed hypergraphs, 16 competitors on 6 attributed graphs, and 16 competitors on 3 attributed multiplex graphs, all demonstrating the superb clustering quality and efficiency of our methods.
Effective Clustering on Large Attributed Bipartite Graphs
May 20, 2024Attributed bipartite graphs (ABGs) are an expressive data model for describing the interactions between two sets of heterogeneous nodes that are associated with rich attributes, such as customer-product purchase networks and author-paper authorship graphs. Partitioning the target node set in such graphs into k disjoint clusters (referred to as k-ABGC) finds widespread use in various domains, including social network analysis, recommendation systems, information retrieval, and bioinformatics. However, the majority of existing solutions towards k-ABGC either overlook attribute information or fail to capture bipartite graph structures accurately, engendering severely compromised result quality. The severity of these issues is accentuated in real ABGs, which often encompass millions of nodes and a sheer volume of attribute data, rendering effective k-ABGC over such graphs highly challenging. In this paper, we propose TPO, an effective and efficient approach to k-ABGC that achieves superb clustering performance on multiple real datasets. TPO obtains high clustering quality through two major contributions: (i) a novel formulation and transformation of the k-ABGC problem based on multi-scale attribute affinity specialized for capturing attribute affinities between nodes with the consideration of their multi-hop connections in ABGs, and (ii) a highly efficient solver that includes a suite of carefully-crafted optimizations for sidestepping explicit affinity matrix construction and facilitating faster convergence. Extensive experiments, comparing TPO against 19 baselines over 5 real ABGs, showcase the superior clustering quality of TPO measured against ground-truth labels. Moreover, compared to the state of the arts, TPO is often more than 40x faster over both small and large ABGs.
SlotGAT: Slot-based Message Passing for Heterogeneous Graph Neural Network
May 03, 2024Heterogeneous graphs are ubiquitous to model complex data. There are urgent needs on powerful heterogeneous graph neural networks to effectively support important applications. We identify a potential semantic mixing issue in existing message passing processes, where the representations of the neighbors of a node $v$ are forced to be transformed to the feature space of $v$ for aggregation, though the neighbors are in different types. That is, the semantics in different node types are entangled together into node $v$'s representation. To address the issue, we propose SlotGAT with separate message passing processes in slots, one for each node type, to maintain the representations in their own node-type feature spaces. Moreover, in a slot-based message passing layer, we design an attention mechanism for effective slot-wise message aggregation. Further, we develop a slot attention technique after the last layer of SlotGAT, to learn the importance of different slots in downstream tasks. Our analysis indicates that the slots in SlotGAT can preserve different semantics in various feature spaces. The superiority of SlotGAT is evaluated against 13 baselines on 6 datasets for node classification and link prediction. Our code is at https://github.com/scottjiao/SlotGAT_ICML23/.
Enhancing Physical Layer Security in Dual-Function Radar-Communication Systems with Hybrid Beamforming Architecture
Mar 12, 2024


In this letter, we investigate enhancing the physical layer security (PLS) for the dual-function radar-communication (DFRC) system with hybrid beamforming (HBF) architecture, where the base station (BS) achieves downlink communication and radar target detection simultaneously. We consider an eavesdropper intercepting the information transmitted from the BS to the downlink communication users with imperfectly known channel state information. Additionally, the location of the radar target is also imperfectly known by the BS. To enhance PLS in the considered DFRC system, we propose a novel HBF architecture, which introduces a new integrated sensing and security (I2S) symbol. The secure HBF design problem for DFRC is formulated by maximizing the minimum legitimate user communication rate subject to radar interference-plus-noise ratio, eavesdropping rate, hardware and power constraints. To solve this non-convex problem, we propose an alternating optimization based method to jointly optimize transmit and receive beamformers. Numerical simulation results validate the effectiveness of the proposed algorithm and show the superiority of the proposed I2S-aided HBF architecture for achieving DFRC and enhancing PLS.