 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGNNs-to-MLPs by Teacher Injection and Dirichlet Energy Distillation
Dec 15, 2024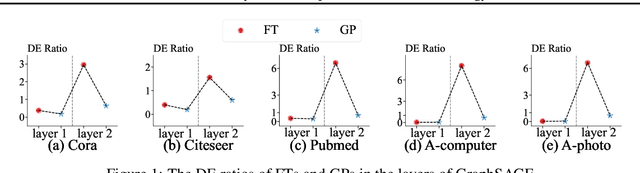

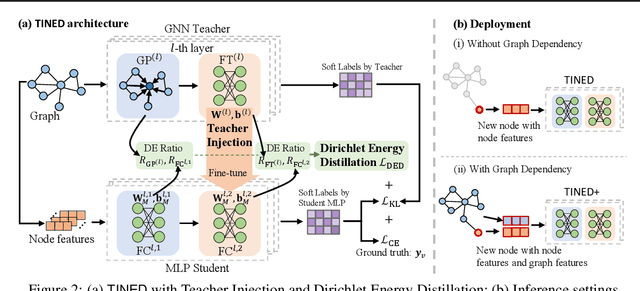
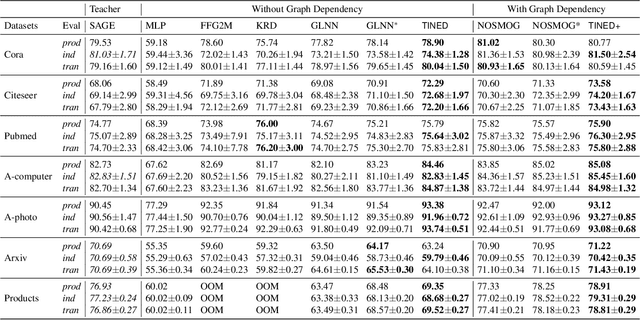
Graph Neural Networks (GNNs) are fundamental to graph-based learning and excel in node classification tasks. However, GNNs suffer from scalability issues due to the need for multi-hop data during inference, limiting their use in latency-sensitive applications. Recent studies attempt to distill GNNs into multi-layer perceptrons (MLPs) for faster inference. They typically treat GNN and MLP models as single units for distillation, insufficiently utilizing the fine-grained knowledge within GNN layers. In this paper, we propose TINED, a novel method that distills GNNs to MLPs layer-wise through Teacher Injection with fine-tuning and Dirichlet Energy Distillation techniques. We analyze key operations in GNN layers, feature transformation (FT) and graph propagation (GP), and identify that an FT performs the same computation as a fully-connected (FC) layer in MLPs. Thus, we propose directly injecting valuable teacher parameters of an FT in a GNN into an FC layer of the student MLP, assisted by fine-tuning. In TINED, FC layers in an MLP mirror the order of the corresponding FTs and GPs in GNN. We provide a theoretical bound on the approximation of GPs. Moreover, we observe that in a GNN layer, FT and GP operations often have opposing smoothing effects: GP is aggressive, while FT is conservative, in smoothing. Using Dirichlet energy, we design a DE ratio to quantify these smoothing effects and propose Dirichlet Energy Distillation to distill these characteristics from GNN layers to MLP layers. Extensive experiments demonstrate that TINED achieves superior performance over GNNs and state-of-the-art distillation methods under various settings across seven datasets. The code is in supplementary material.
A Versatile Framework for Attributed Network Clustering via K-Nearest Neighbor Augmentation
Aug 10, 2024Attributed networks containing entity-specific information in node attributes are ubiquitous in modeling social networks, e-commerce, bioinformatics, etc. Their inherent network topology ranges from simple graphs to hypergraphs with high-order interactions and multiplex graphs with separate layers. An important graph mining task is node clustering, aiming to partition the nodes of an attributed network into k disjoint clusters such that intra-cluster nodes are closely connected and share similar attributes, while inter-cluster nodes are far apart and dissimilar. It is highly challenging to capture multi-hop connections via nodes or attributes for effective clustering on multiple types of attributed networks. In this paper, we first present AHCKA as an efficient approach to attributed hypergraph clustering (AHC). AHCKA includes a carefully-crafted K-nearest neighbor augmentation strategy for the optimized exploitation of attribute information on hypergraphs, a joint hypergraph random walk model to devise an effective AHC objective, and an efficient solver with speedup techniques for the objective optimization. The proposed techniques are extensible to various types of attributed networks, and thus, we develop ANCKA as a versatile attributed network clustering framework, capable of attributed graph clustering (AGC), attributed multiplex graph clustering (AMGC), and AHC. Moreover, we devise ANCKA with algorithmic designs tailored for GPU acceleration to boost efficiency. We have conducted extensive experiments to compare our methods with 19 competitors on 8 attributed hypergraphs, 16 competitors on 6 attributed graphs, and 16 competitors on 3 attributed multiplex graphs, all demonstrating the superb clustering quality and efficiency of our methods.
Super(ficial)-alignment: Strong Models May Deceive Weak Models in Weak-to-Strong Generalization
Jun 17, 2024



Superalignment, where humans are weak supervisors of superhuman models, has become an important and widely discussed issue in the current era of rapid development of Large Language Models (LLMs). The recent work preliminarily studies this problem by using weak models to supervise strong models. It discovers that weakly supervised strong students can consistently outperform weak teachers towards the alignment target, leading to a weak-to-strong generalization phenomenon. However, we are concerned that behind such a promising phenomenon, whether there exists an issue of weak-to-strong deception, where strong models may deceive weak models by exhibiting well-aligned in areas known to weak models but producing misaligned behaviors in cases weak models do not know. We then take an initial step towards exploring this security issue in a specific but realistic multi-objective alignment case, where there may be some alignment targets conflicting with each other (e.g., helpfulness v.s. harmlessness). Such a conflict is likely to cause strong models to deceive weak models in one alignment dimension to gain high reward in other alignment dimension. Our experiments on both the reward modeling task and the preference optimization scenario indicate: (1) the weak-to-strong deception exists; (2) the deception phenomenon may intensify as the capability gap between weak and strong models increases. We also discuss potential solutions and find bootstrapping with an intermediate model can mitigate the deception to some extent. Our work highlights the urgent need to pay more attention to the true reliability of superalignment.
Unsupervised Graph Neural Architecture Search with Disentangled Self-supervision
Mar 08, 2024



The existing graph neural architecture search (GNAS) methods heavily rely on supervised labels during the search process, failing to handle ubiquitous scenarios where supervisions are not available. In this paper, we study the problem of unsupervised graph neural architecture search, which remains unexplored in the literature. The key problem is to discover the latent graph factors that drive the formation of graph data as well as the underlying relations between the factors and the optimal neural architectures. Handling this problem is challenging given that the latent graph factors together with architectures are highly entangled due to the nature of the graph and the complexity of the neural architecture search process. To address the challenge, we propose a novel Disentangled Self-supervised Graph Neural Architecture Search (DSGAS) model, which is able to discover the optimal architectures capturing various latent graph factors in a self-supervised fashion based on unlabeled graph data. Specifically, we first design a disentangled graph super-network capable of incorporating multiple architectures with factor-wise disentanglement, which are optimized simultaneously. Then, we estimate the performance of architectures under different factors by our proposed self-supervised training with joint architecture-graph disentanglement. Finally, we propose a contrastive search with architecture augmentations to discover architectures with factor-specific expertise. Extensive experiments on 11 real-world datasets demonstrate that the proposed model is able to achieve state-of-the-art performance against several baseline methods in an unsupervised manner.
Membership Inference Attacks and Generalization: A Causal Perspective
Sep 18, 2022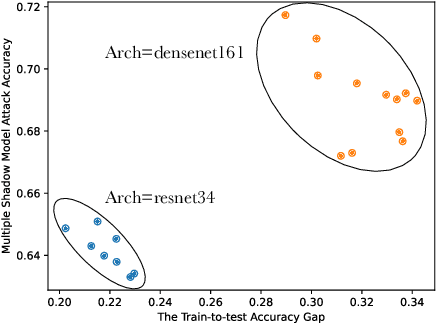
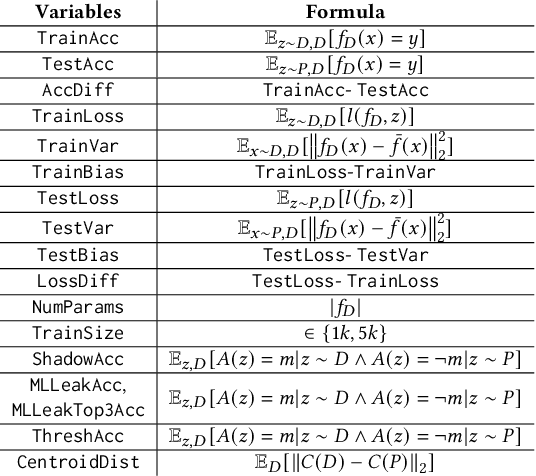
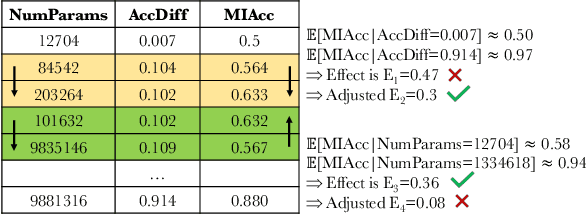
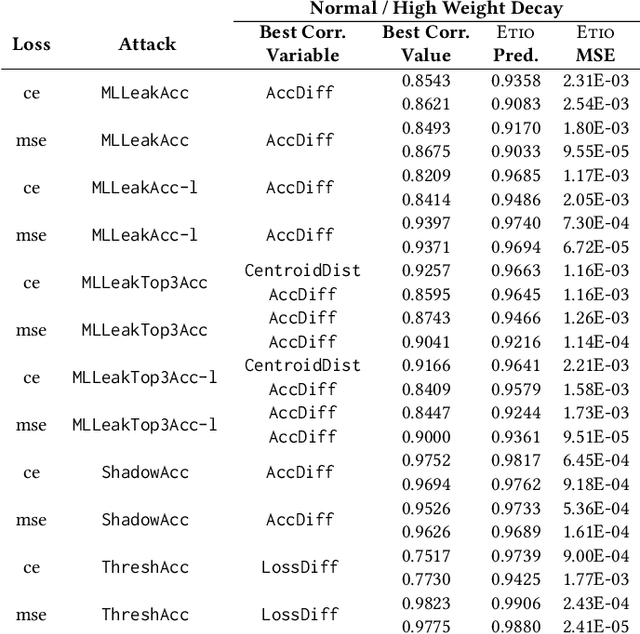
Membership inference (MI) attacks highlight a privacy weakness in present stochastic training methods for neural networks. It is not well understood, however, why they arise. Are they a natural consequence of imperfect generalization only? Which underlying causes should we address during training to mitigate these attacks? Towards answering such questions, we propose the first approach to explain MI attacks and their connection to generalization based on principled causal reasoning. We offer causal graphs that quantitatively explain the observed MI attack performance achieved for $6$ attack variants. We refute several prior non-quantitative hypotheses that over-simplify or over-estimate the influence of underlying causes, thereby failing to capture the complex interplay between several factors. Our causal models also show a new connection between generalization and MI attacks via their shared causal factors. Our causal models have high predictive power ($0.90$), i.e., their analytical predictions match with observations in unseen experiments often, which makes analysis via them a pragmatic alternative.
Quantitative Verification of Neural Networks And its Security Applications
Jun 25, 2019

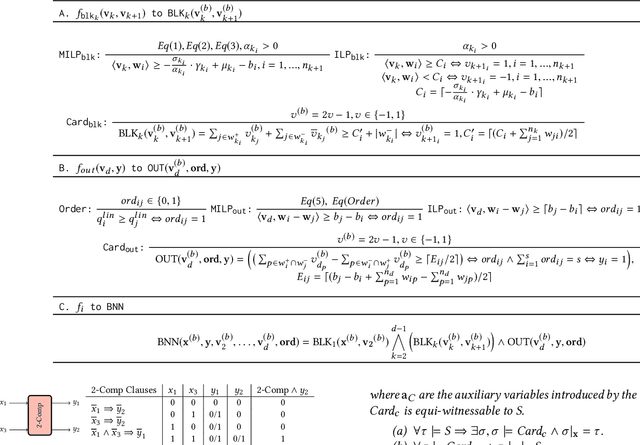
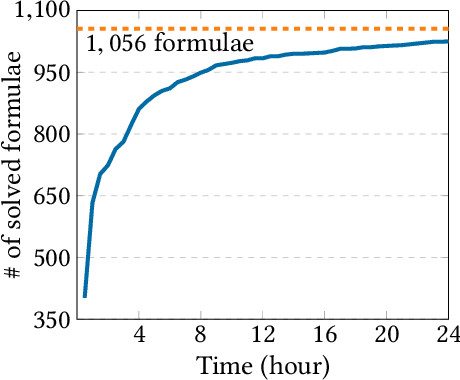
Neural networks are increasingly employed in safety-critical domains. This has prompted interest in verifying or certifying logically encoded properties of neural networks. Prior work has largely focused on checking existential properties, wherein the goal is to check whether there exists any input that violates a given property of interest. However, neural network training is a stochastic process, and many questions arising in their analysis require probabilistic and quantitative reasoning, i.e., estimating how many inputs satisfy a given property. To this end, our paper proposes a novel and principled framework to quantitative verification of logical properties specified over neural networks. Our framework is the first to provide PAC-style soundness guarantees, in that its quantitative estimates are within a controllable and bounded error from the true count. We instantiate our algorithmic framework by building a prototype tool called NPAQ that enables checking rich properties over binarized neural networks. We show how emerging security analyses can utilize our framework in 3 concrete point applications: quantifying robustness to adversarial inputs, efficacy of trojan attacks, and fairness/bias of given neural networks.
THUMT: An Open Source Toolkit for Neural Machine Translation
Jun 20, 2017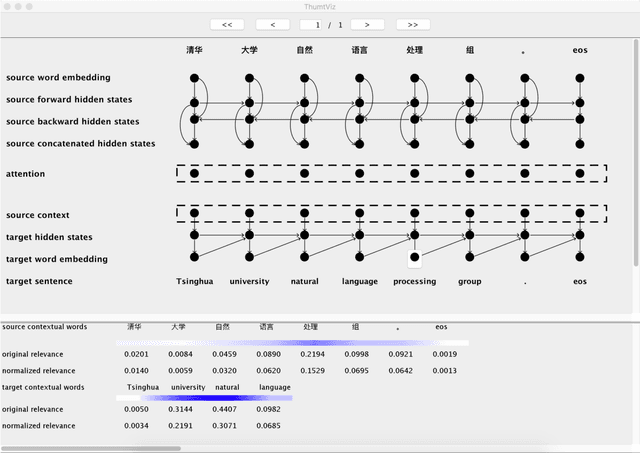
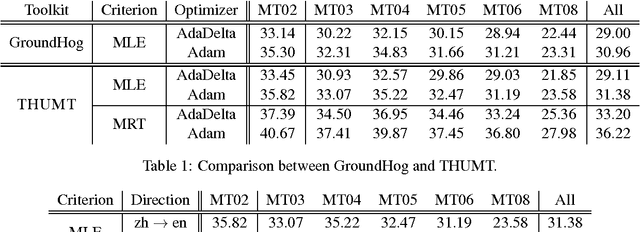
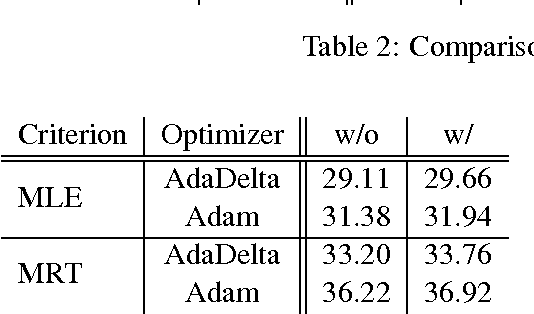
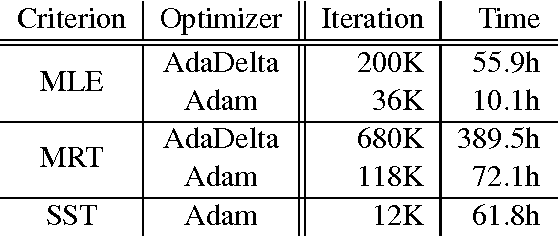
This paper introduces THUMT, an open-source toolkit for neural machine translation (NMT) developed by the Natural Language Processing Group at Tsinghua University. THUMT implements the standard attention-based encoder-decoder framework on top of Theano and supports three training criteria: maximum likelihood estimation, minimum risk training, and semi-supervised training. It features a visualization tool for displaying the relevance between hidden states in neural networks and contextual words, which helps to analyze the internal workings of NMT. Experiments on Chinese-English datasets show that THUMT using minimum risk training significantly outperforms GroundHog, a state-of-the-art toolkit for NMT.
Neural Headline Generation with Sentence-wise Optimization
Oct 09, 2016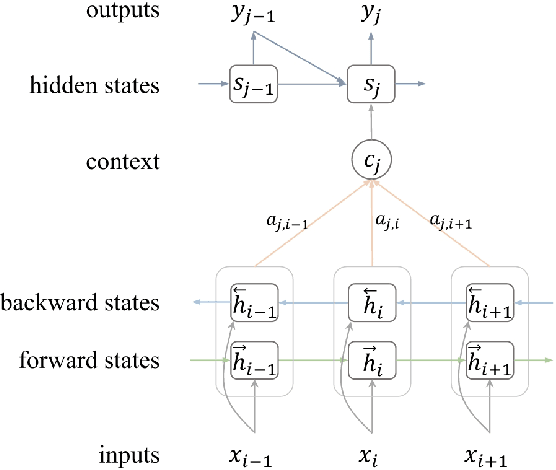
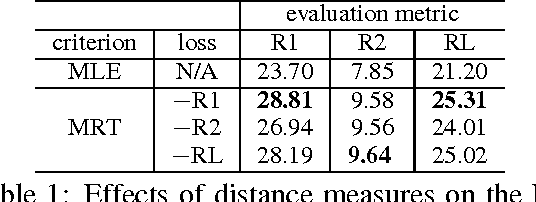
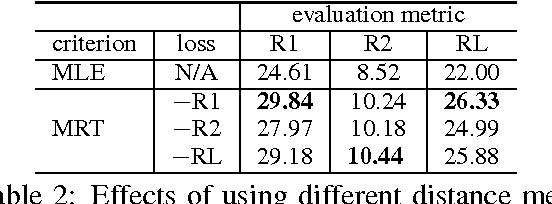
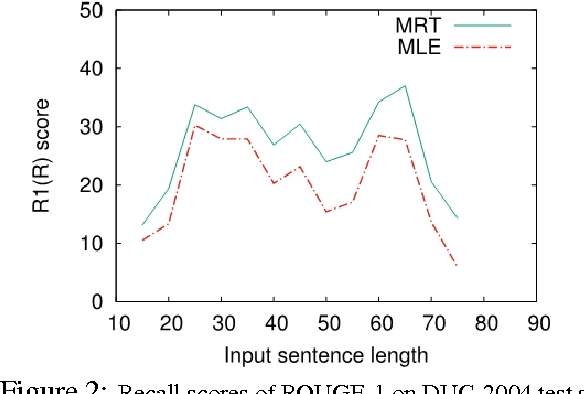
Recently, neural models have been proposed for headline generation by learning to map documents to headlines with recurrent neural networks. Nevertheless, as traditional neural network utilizes maximum likelihood estimation for parameter optimization, it essentially constrains the expected training objective within word level rather than sentence level. Moreover, the performance of model prediction significantly relies on training data distribution. To overcome these drawbacks, we employ minimum risk training strategy in this paper, which directly optimizes model parameters in sentence level with respect to evaluation metrics and leads to significant improvements for headline generation. Experiment results show that our models outperforms state-of-the-art systems on both English and Chinese headline generation tasks.
Minimum Risk Training for Neural Machine Translation
Jun 15, 2016
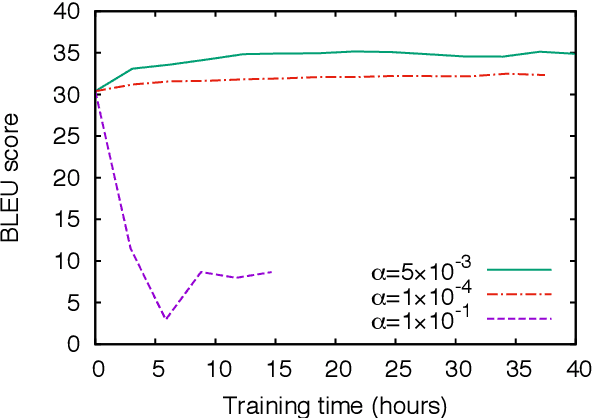
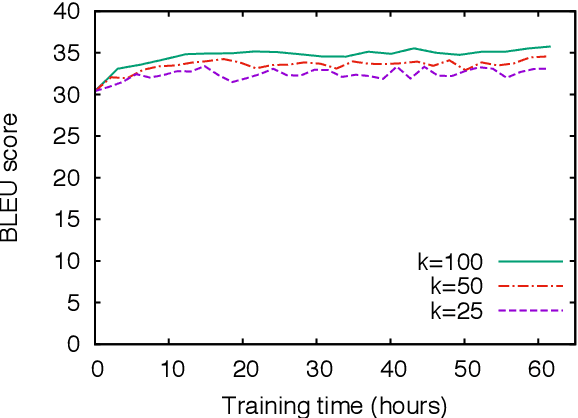
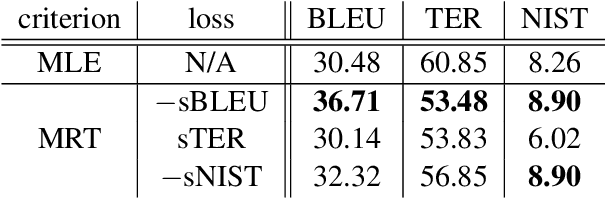
We propose minimum risk training for end-to-end neural machine translation. Unlike conventional maximum likelihood estimation, minimum risk training is capable of optimizing model parameters directly with respect to arbitrary evaluation metrics, which are not necessarily differentiable. Experiments show that our approach achieves significant improvements over maximum likelihood estimation on a state-of-the-art neural machine translation system across various languages pairs. Transparent to architectures, our approach can be applied to more neural networks and potentially benefit more NLP tasks.
Agreement-based Joint Training for Bidirectional Attention-based Neural Machine Translation
Apr 22, 2016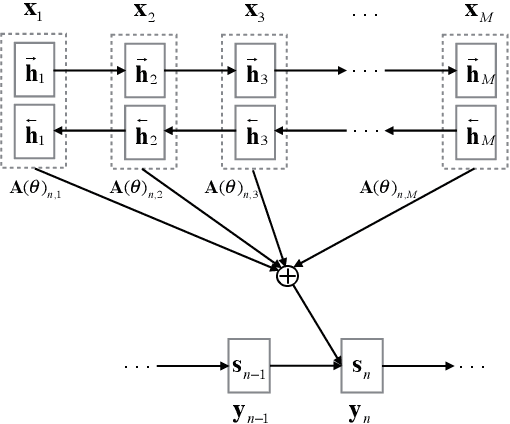



The attentional mechanism has proven to be effective in improving end-to-end neural machine translation. However, due to the intricate structural divergence between natural languages, unidirectional attention-based models might only capture partial aspects of attentional regularities. We propose agreement-based joint training for bidirectional attention-based end-to-end neural machine translation. Instead of training source-to-target and target-to-source translation models independently,our approach encourages the two complementary models to agree on word alignment matrices on the same training data. Experiments on Chinese-English and English-French translation tasks show that agreement-based joint training significantly improves both alignment and translation quality over independent training.