 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMembership Inference Attacks and Generalization: A Causal Perspective
Paper and Code
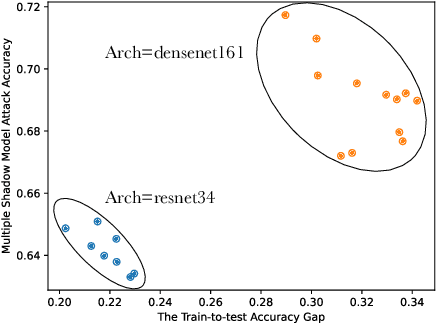
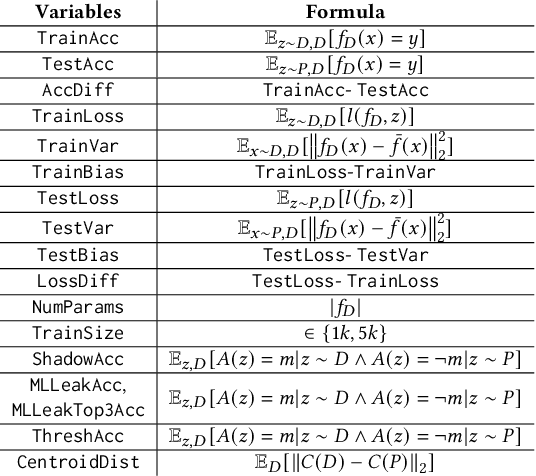
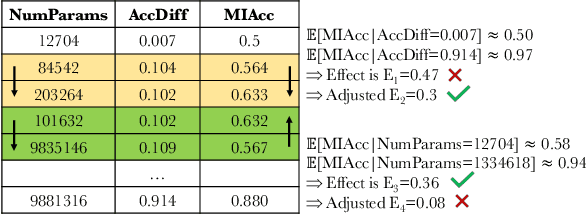
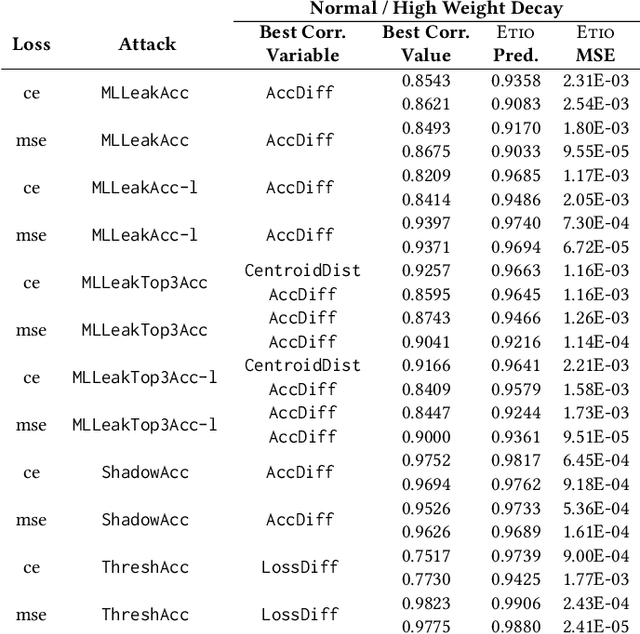
Membership inference (MI) attacks highlight a privacy weakness in present stochastic training methods for neural networks. It is not well understood, however, why they arise. Are they a natural consequence of imperfect generalization only? Which underlying causes should we address during training to mitigate these attacks? Towards answering such questions, we propose the first approach to explain MI attacks and their connection to generalization based on principled causal reasoning. We offer causal graphs that quantitatively explain the observed MI attack performance achieved for $6$ attack variants. We refute several prior non-quantitative hypotheses that over-simplify or over-estimate the influence of underlying causes, thereby failing to capture the complex interplay between several factors. Our causal models also show a new connection between generalization and MI attacks via their shared causal factors. Our causal models have high predictive power ($0.90$), i.e., their analytical predictions match with observations in unseen experiments often, which makes analysis via them a pragmatic alternative.